 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Exhaustive Pattern Learning
Paper and Code
Apr 20, 2011
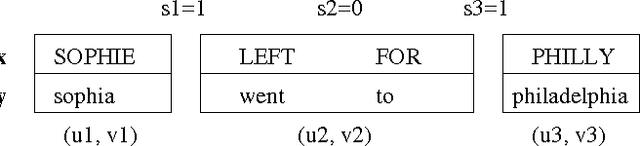
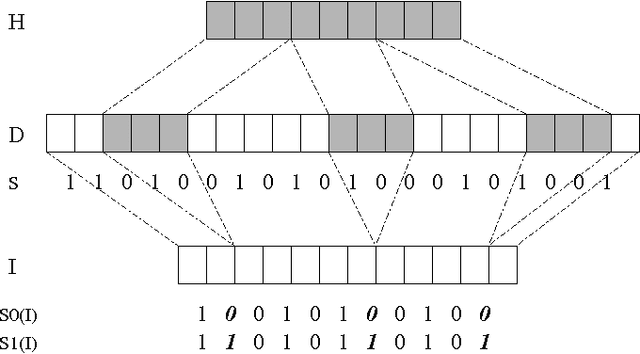
Pattern learning in an important problem in Natural Language Processing (NLP). Some exhaustive pattern learning (EPL) methods (Bod, 1992) were proved to be flawed (Johnson, 2002), while similar algorithms (Och and Ney, 2004) showed great advantages on other tasks, such as machine translation. In this article, we first formalize EPL, and then show that the probability given by an EPL model is constant-factor approximation of the probability given by an ensemble method that integrates exponential number of models obtained with various segmentations of the training data. This work for the first time provides theoretical justification for the widely used EPL algorithm in NLP, which was previously viewed as a flawed heuristic method. Better understanding of EPL may lead to improved pattern learning algorithms in future.