 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSourceNet: Interpretable Sim-to-Real Inference on Variable-Geometry Sensor Arrays for Earthquake Source Inversion
Jan 09, 2026Inferring high-dimensional physical states from sparse, ad-hoc sensor arrays is a fundamental challenge across AI for Science, as they are complicated by irregular geometries and the profound Sim-to-Real gap in physical modeling. Taking earthquake source characterization as a representative challenge, we address limitations in conventional deep learning: CNNs demand fixed grids, while pooling-based architectures (e.g., DeepSets) struggle to capture the relational wave physics. Here, we propose SourceNet, a Transformer-based framework that treats the sensor array as a flexible set to model arbitrary geometries. To bridge the reality gap, we introduce Physics-Structured Domain Randomization (PSDR). Instead of forcing feature alignment, PSDR randomizes the governing physical dynamics by varying velocity structures, propagation effects, and sensor availability, to force the model to learn robust representations invariant to unmodeled environmental heterogeneity. By pre-training on 100,000 synthetic events and fine-tuning on ~2,000 real world events, SourceNet achieves state-of-the-art precision on held-out real data. This demonstrates exceptional data efficiency, and matches classical solvers while enabling real-time processing. Remarkably, interpretability analysis reveals that the model shows scientific-agent-like features: it autonomously discovers geometric information bottlenecks and learns an attention policy that prioritizes sparse sensor placements, effectively recovering principles of optimal experimental design from data alone.
Structure-Preserving Margin Distribution Learning for High-Order Tensor Data with Low-Rank Decomposition
Sep 18, 2025



The Large Margin Distribution Machine (LMDM) is a recent advancement in classifier design that optimizes not just the minimum margin (as in SVM) but the entire margin distribution, thereby improving generalization. However, existing LMDM formulations are limited to vectorized inputs and struggle with high-dimensional tensor data due to the need for flattening, which destroys the data's inherent multi-mode structure and increases computational burden. In this paper, we propose a Structure-Preserving Margin Distribution Learning for High-Order Tensor Data with Low-Rank Decomposition (SPMD-LRT) that operates directly on tensor representations without vectorization. The SPMD-LRT preserves multi-dimensional spatial structure by incorporating first-order and second-order tensor statistics (margin mean and variance) into the objective, and it leverages low-rank tensor decomposition techniques including rank-1(CP), higher-rank CP, and Tucker decomposition to parameterize the weight tensor. An alternating optimization (double-gradient descent) algorithm is developed to efficiently solve the SPMD-LRT, iteratively updating factor matrices and core tensor. This approach enables SPMD-LRT to maintain the structural information of high-order data while optimizing margin distribution for improved classification. Extensive experiments on diverse datasets (including MNIST, images and fMRI neuroimaging) demonstrate that SPMD-LRT achieves superior classification accuracy compared to conventional SVM, vector-based LMDM, and prior tensor-based SVM extensions (Support Tensor Machines and Support Tucker Machines). Notably, SPMD-LRT with Tucker decomposition attains the highest accuracy, highlighting the benefit of structure preservation. These results confirm the effectiveness and robustness of SPMD-LRT in handling high-dimensional tensor data for classification.
A Unified Empirical Risk Minimization Framework for Flexible N-Tuples Weak Supervision
Jul 10, 2025To alleviate the annotation burden in supervised learning, N-tuples learning has recently emerged as a powerful weakly-supervised method. While existing N-tuples learning approaches extend pairwise learning to higher-order comparisons and accommodate various real-world scenarios, they often rely on task-specific designs and lack a unified theoretical foundation. In this paper, we propose a general N-tuples learning framework based on empirical risk minimization, which systematically integrates pointwise unlabeled data to enhance learning performance. This paper first unifies the data generation processes of N-tuples and pointwise unlabeled data under a shared probabilistic formulation. Based on this unified view, we derive an unbiased empirical risk estimator that generalizes a broad class of existing N-tuples models. We further establish a generalization error bound for theoretical support. To demonstrate the flexibility of the framework, we instantiate it in four representative weakly supervised scenarios, each recoverable as a special case of our general model. Additionally, to address overfitting issues arising from negative risk terms, we adopt correction functions to adjust the empirical risk. Extensive experiments on benchmark datasets validate the effectiveness of the proposed framework and demonstrate that leveraging pointwise unlabeled data consistently improves generalization across various N-tuples learning tasks.
Combining Supervised Learning and Reinforcement Learning for Multi-Label Classification Tasks with Partial Labels
Jun 24, 2024
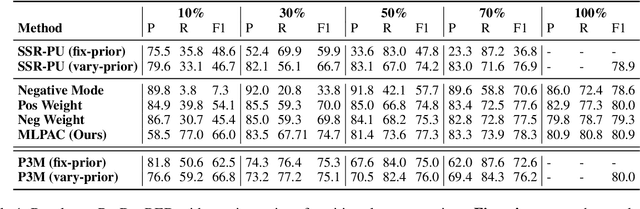
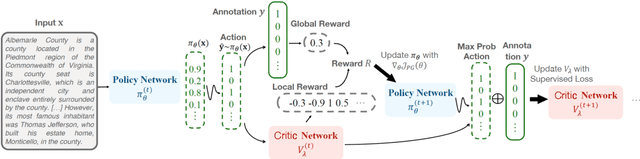
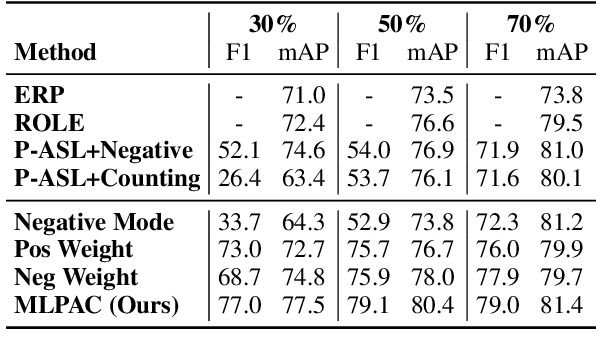
Traditional supervised learning heavily relies on human-annotated datasets, especially in data-hungry neural approaches. However, various tasks, especially multi-label tasks like document-level relation extraction, pose challenges in fully manual annotation due to the specific domain knowledge and large class sets. Therefore, we address the multi-label positive-unlabelled learning (MLPUL) problem, where only a subset of positive classes is annotated. We propose Mixture Learner for Partially Annotated Classification (MLPAC), an RL-based framework combining the exploration ability of reinforcement learning and the exploitation ability of supervised learning. Experimental results across various tasks, including document-level relation extraction, multi-label image classification, and binary PU learning, demonstrate the generalization and effectiveness of our framework.
Semi-automatic Data Enhancement for Document-Level Relation Extraction with Distant Supervision from Large Language Models
Nov 13, 2023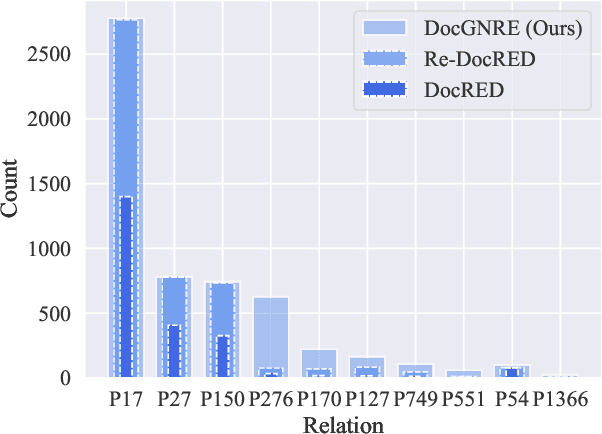
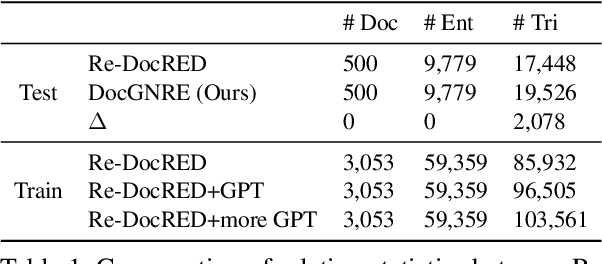
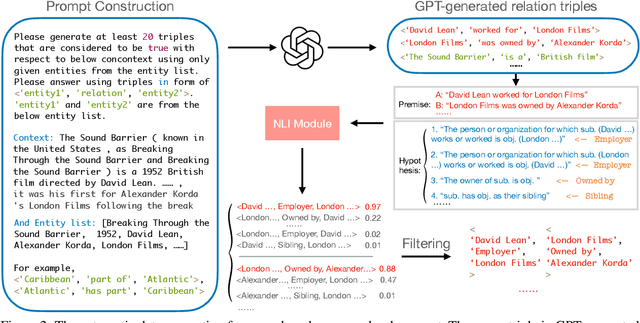

Document-level Relation Extraction (DocRE), which aims to extract relations from a long context, is a critical challenge in achieving fine-grained structural comprehension and generating interpretable document representations. Inspired by recent advances in in-context learning capabilities emergent from large language models (LLMs), such as ChatGPT, we aim to design an automated annotation method for DocRE with minimum human effort. Unfortunately, vanilla in-context learning is infeasible for document-level relation extraction due to the plenty of predefined fine-grained relation types and the uncontrolled generations of LLMs. To tackle this issue, we propose a method integrating a large language model (LLM) and a natural language inference (NLI) module to generate relation triples, thereby augmenting document-level relation datasets. We demonstrate the effectiveness of our approach by introducing an enhanced dataset known as DocGNRE, which excels in re-annotating numerous long-tail relation types. We are confident that our method holds the potential for broader applications in domain-specific relation type definitions and offers tangible benefits in advancing generalized language semantic comprehension.