 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Negative Data of Distantly Supervised Relation Extraction
Paper and Code
May 21, 2021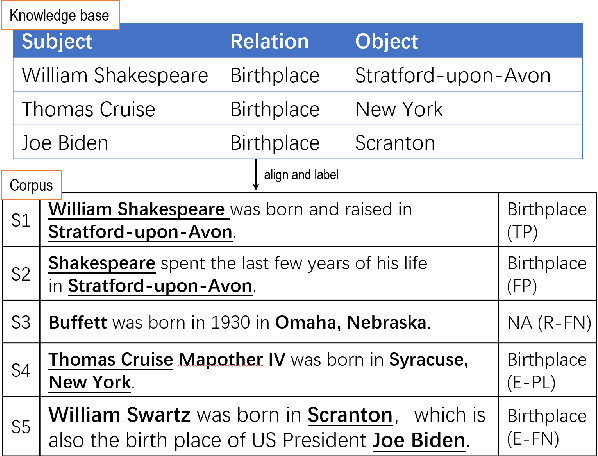
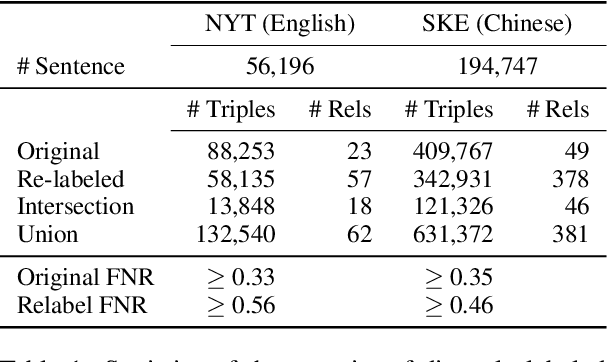
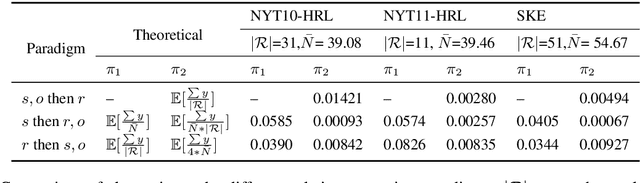
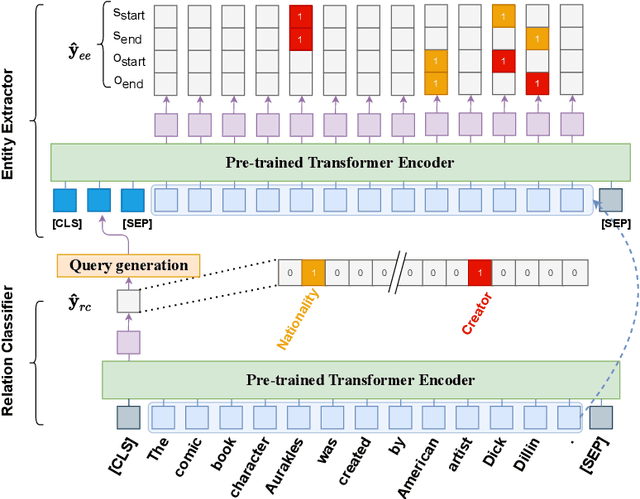
Distantly supervision automatically generates plenty of training samples for relation extraction. However, it also incurs two major problems: noisy labels and imbalanced training data. Previous works focus more on reducing wrongly labeled relations (false positives) while few explore the missing relations that are caused by incompleteness of knowledge base (false negatives). Furthermore, the quantity of negative labels overwhelmingly surpasses the positive ones in previous problem formulations. In this paper, we first provide a thorough analysis of the above challenges caused by negative data. Next, we formulate the problem of relation extraction into as a positive unlabeled learning task to alleviate false negative problem. Thirdly, we propose a pipeline approach, dubbed \textsc{ReRe}, that performs sentence-level relation detection then subject/object extraction to achieve sample-efficient training. Experimental results show that the proposed method consistently outperforms existing approaches and remains excellent performance even learned with a large quantity of false positive samples.