 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Embedding Distribution Refinement and Entropy-Aware Attention for 3D Point Cloud Classification
Jan 27, 2022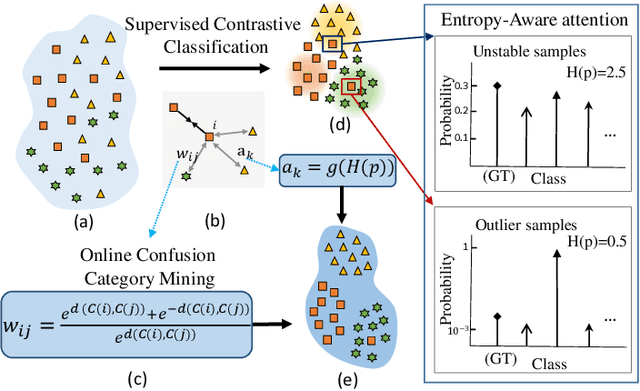
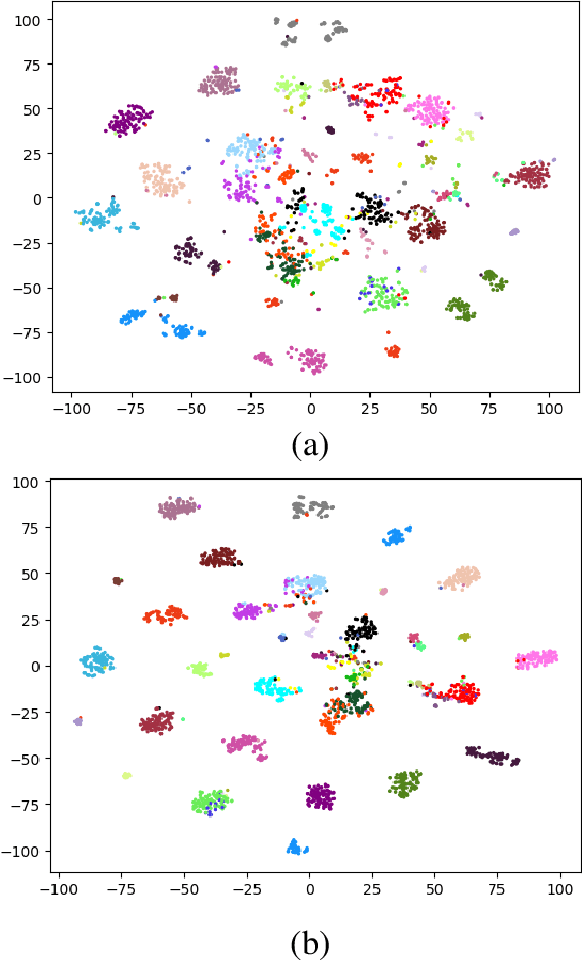
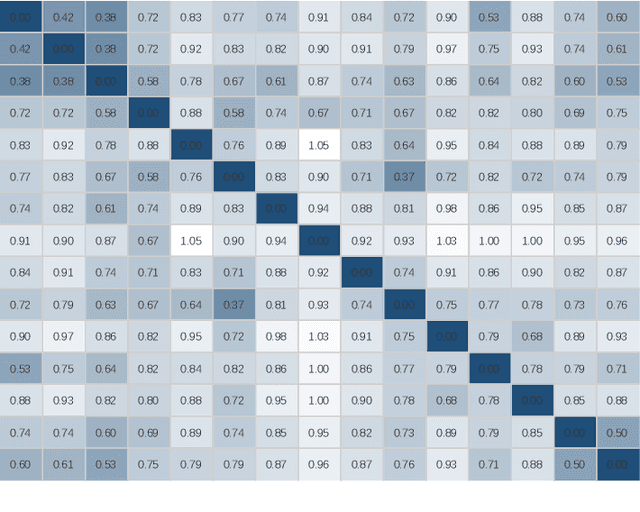
Learning a powerful representation from point clouds is a fundamental and challenging problem in the field of computer vision. Different from images where RGB pixels are stored in the regular grid, for point clouds, the underlying semantic and structural information of point clouds is the spatial layout of the points. Moreover, the properties of challenging in-context and background noise pose more challenges to point cloud analysis. One assumption is that the poor performance of the classification model can be attributed to the indistinguishable embedding feature that impedes the search for the optimal classifier. This work offers a new strategy for learning powerful representations via a contrastive learning approach that can be embedded into any point cloud classification network. First, we propose a supervised contrastive classification method to implement embedding feature distribution refinement by improving the intra-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class variations between some similar-looking categories, we propose a confusion-prone class mining strategy to alleviate the confusion effect. Finally, considering that outliers of the sample clusters in the embedding space may cause performance degradation, we design an entropy-aware attention module with information entropy theory to identify the outlier cases and the unstable samples by measuring the uncertainty of predicted probability. The results of extensive experiments demonstrate that our method outperforms the state-of-the-art approaches by achieving 82.9% accuracy on the real-world ScanObjectNN dataset and substantial performance gains up to 2.9% in DCGNN, 3.1% in PointNet++, and 2.4% in GBNet.
Hierarchical Motion Encoder-Decoder Network for Trajectory Forecasting
Nov 26, 2021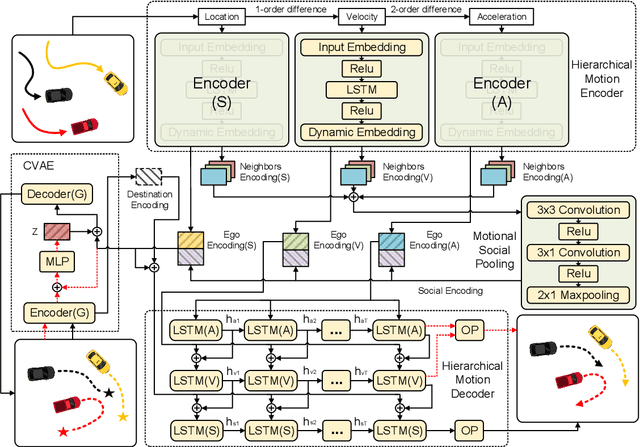
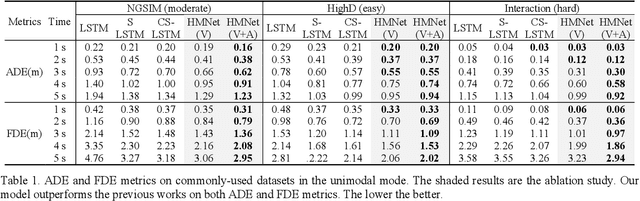
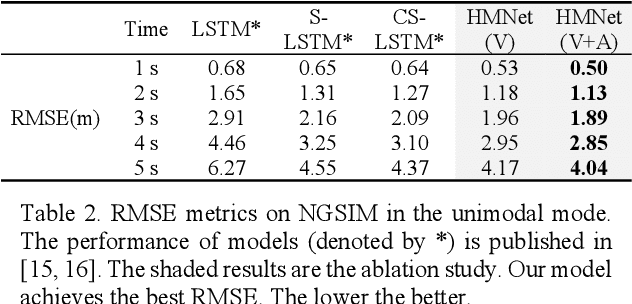
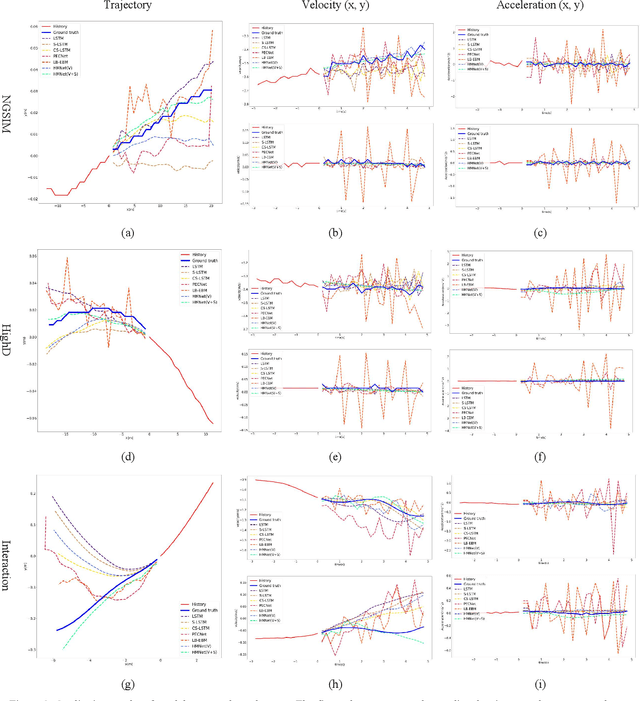
Trajectory forecasting plays a pivotal role in the field of intelligent vehicles or social robots. Recent works focus on modeling spatial social impacts or temporal motion attentions, but neglect inherent properties of motions, i.e. moving trends and driving intentions. This paper proposes a context-free Hierarchical Motion Encoder-Decoder Network (HMNet) for vehicle trajectory prediction. HMNet first infers the hierarchical difference on motions to encode physically compliant patterns with high expressivity of moving trends and driving intentions. Then, a goal (endpoint)-embedded decoder hierarchically constructs multimodal predictions depending on the location-velocity-acceleration-related patterns. Besides, we present a modified social pooling module which considers certain motion properties to represent social interactions. HMNet enables to make the accurate, unimodal/multimodal and physically-socially-compliant prediction. Experiments on three public trajectory prediction datasets, i.e. NGSIM, HighD and Interaction show that our model achieves the state-of-the-art performance both quantitatively and qualitatively. We will release our code here: https://github.com/xuedashuai/HMNet.
Deep Kalman Filter: A Refinement Module for the Rollout Trajectory Prediction Methods
Feb 22, 2021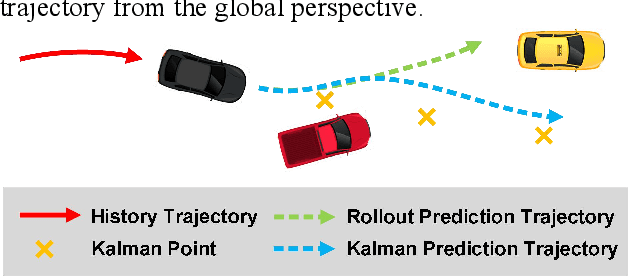

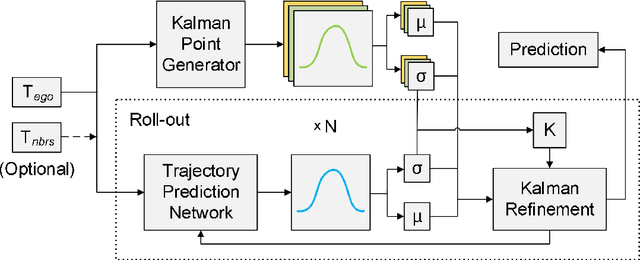
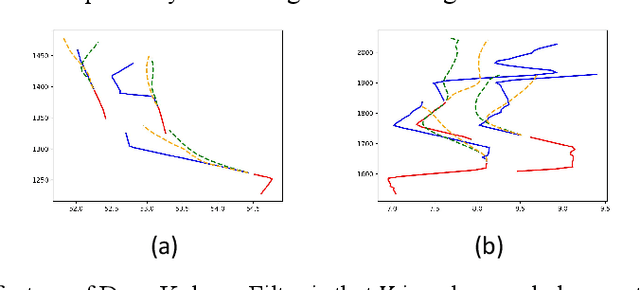
Trajectory prediction plays a pivotal role in the field of intelligent vehicles. It currently suffers from several challenges, e.g., accumulative error in rollout process and weak adaptability in various scenarios. This paper proposes a parametric-learning Kalman filter based on deep neural network for trajectory prediction. We design a flexible plug-in module which can be readily implanted into most rollout approaches. Kalman points are proposed to capture the long-term prediction stability from the global perspective. We carried experiments out on the NGSIM dataset. The promising results indicate that our method could improve rollout trajectory prediction methods effectively.
Spatial-Channel Transformer Network for Trajectory Prediction on the Traffic Scenes
Feb 05, 2021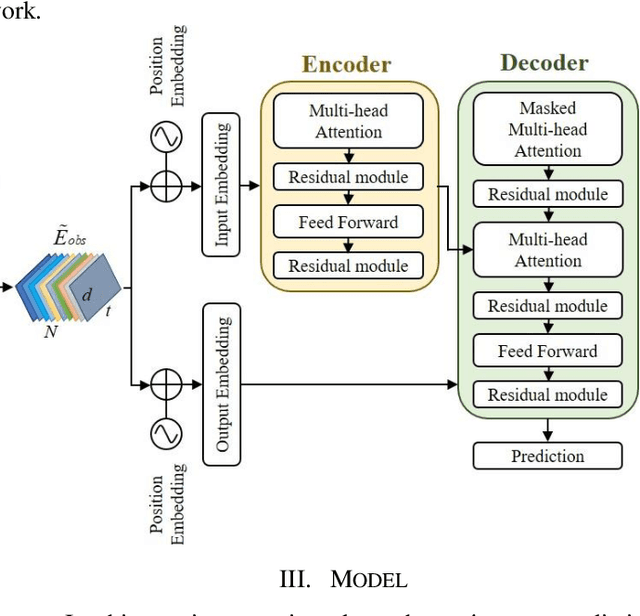
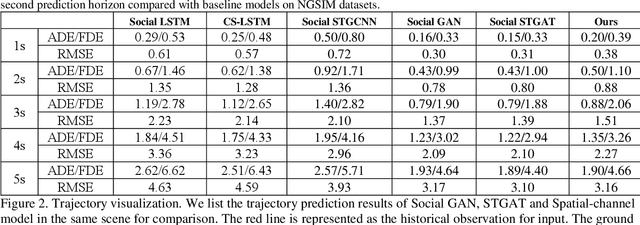
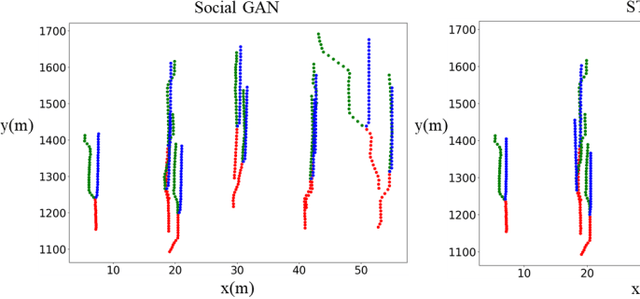
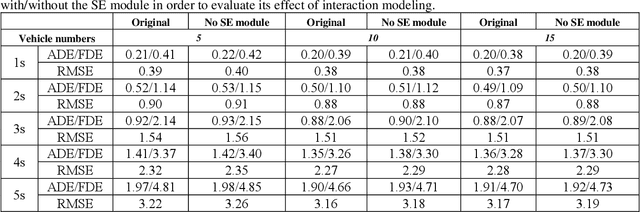
Predicting motion of surrounding agents is critical to real-world applications of tactical path planning for autonomous driving. Due to the complex temporal dependencies and social interactions of agents, on-line trajectory prediction is a challenging task. With the development of attention mechanism in recent years, transformer model has been applied in natural language sequence processing first and then image processing. In this paper, we present a Spatial-Channel Transformer Network for trajectory prediction with attention functions. Instead of RNN models, we employ transformer model to capture the spatial-temporal features of agents. A channel-wise module is inserted to measure the social interaction between agents. We find that the Spatial-Channel Transformer Network achieves promising results on real-world trajectory prediction datasets on the traffic scenes.
Enabling Highly Efficient Capsule Networks Processing Through A PIM-Based Architecture Design
Nov 07, 2019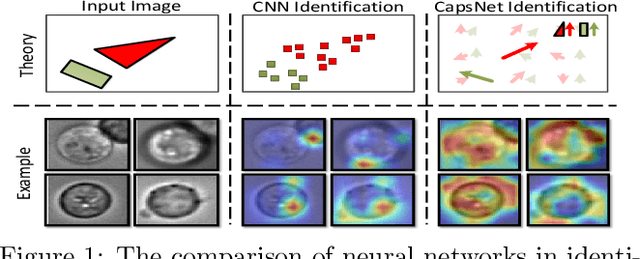
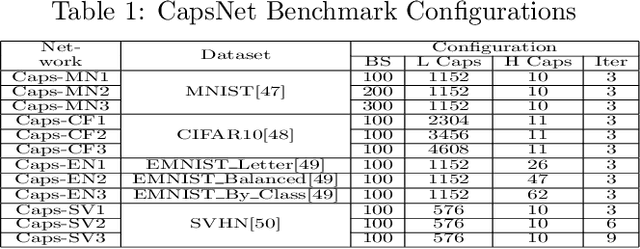

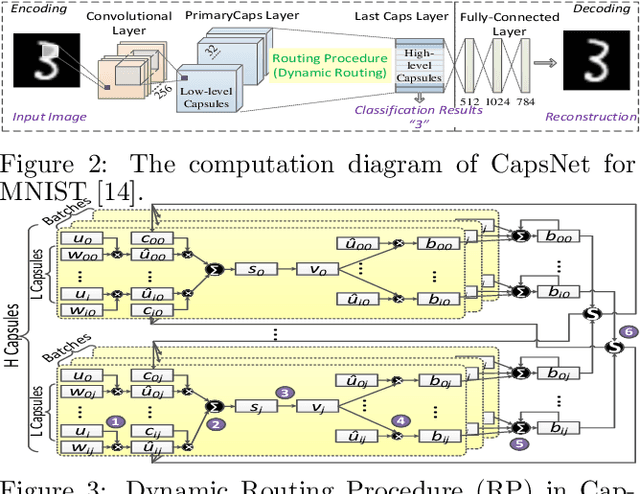
In recent years, the CNNs have achieved great successes in the image processing tasks, e.g., image recognition and object detection. Unfortunately, traditional CNN's classification is found to be easily misled by increasingly complex image features due to the usage of pooling operations, hence unable to preserve accurate position and pose information of the objects. To address this challenge, a novel neural network structure called Capsule Network has been proposed, which introduces equivariance through capsules to significantly enhance the learning ability for image segmentation and object detection. Due to its requirement of performing a high volume of matrix operations, CapsNets have been generally accelerated on modern GPU platforms that provide highly optimized software library for common deep learning tasks. However, based on our performance characterization on modern GPUs, CapsNets exhibit low efficiency due to the special program and execution features of their routing procedure, including massive unshareable intermediate variables and intensive synchronizations, which are very difficult to optimize at software level. To address these challenges, we propose a hybrid computing architecture design named \textit{PIM-CapsNet}. It preserves GPU's on-chip computing capability for accelerating CNN types of layers in CapsNet, while pipelining with an off-chip in-memory acceleration solution that effectively tackles routing procedure's inefficiency by leveraging the processing-in-memory capability of today's 3D stacked memory. Using routing procedure's inherent parallellization feature, our design enables hierarchical improvements on CapsNet inference efficiency through minimizing data movement and maximizing parallel processing in memory.