 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Disentangled Representation Learning for Interpretable Radio Frequency Fingerprint
Aug 18, 2025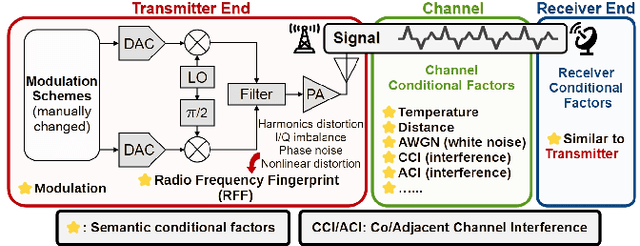
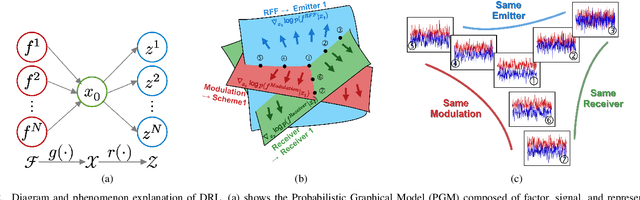
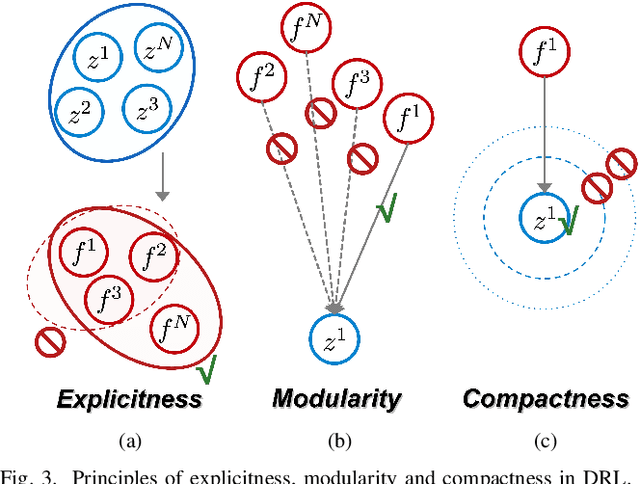
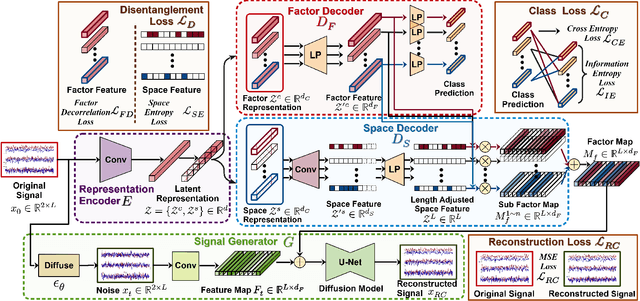
In response to the rapid growth of Internet of Things (IoT) devices and rising security risks, Radio Frequency Fingerprint (RFF) has become key for device identification and authentication. However, various changing factors - beyond the RFF itself - can be entangled from signal transmission to reception, reducing the effectiveness of RFF Identification (RFFI). Existing RFFI methods mainly rely on domain adaptation techniques, which often lack explicit factor representations, resulting in less robustness and limited controllability for downstream tasks. To tackle this problem, we propose a novel Disentangled Representation Learning (DRL) framework that learns explicit and independent representations of multiple factors, including the RFF. Our framework introduces modules for disentanglement, guided by the principles of explicitness, modularity, and compactness. We design two dedicated modules for factor classification and signal reconstruction, each with tailored loss functions that encourage effective disentanglement and enhance support for downstream tasks. Thus, the framework can extract a set of interpretable vectors that explicitly represent corresponding factors. We evaluate our approach on two public benchmark datasets and a self-collected dataset. Our method achieves impressive performance on multiple DRL metrics. We also analyze the effectiveness of our method on downstream RFFI task and conditional signal generation task. All modules of the framework contribute to improved classification accuracy, and enable precise control over conditional generated signals. These results highlight the potential of our DRL framework for interpretable and explicit RFFs.
Global Spatio-Temporal Fusion-based Traffic Prediction Algorithm with Anomaly Aware
Dec 19, 2024
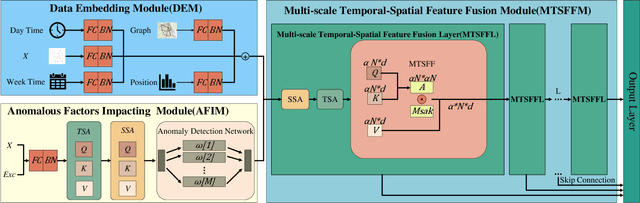
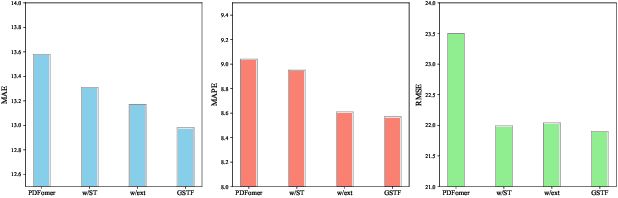
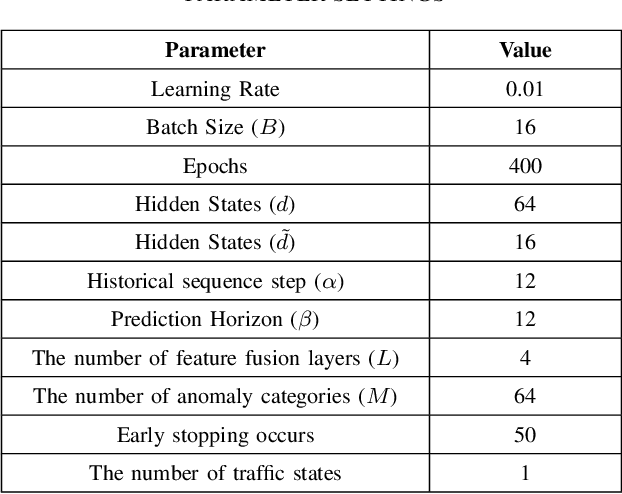
Traffic prediction is an indispensable component of urban planning and traffic management. Achieving accurate traffic prediction hinges on the ability to capture the potential spatio-temporal relationships among road sensors. However, the majority of existing works focus on local short-term spatio-temporal correlations, failing to fully consider the interactions of different sensors in the long-term state. In addition, these works do not analyze the influences of anomalous factors, or have insufficient ability to extract personalized features of anomalous factors, which make them ineffectively capture their spatio-temporal influences on traffic prediction. To address the aforementioned issues, We propose a global spatio-temporal fusion-based traffic prediction algorithm that incorporates anomaly awareness. Initially, based on the designed anomaly detection network, we construct an efficient anomalous factors impacting module (AFIM), to evaluate the spatio-temporal impact of unexpected external events on traffic prediction. Furthermore, we propose a multi-scale spatio-temporal feature fusion module (MTSFFL) based on the transformer architecture, to obtain all possible both long and short term correlations among different sensors in a wide-area traffic environment for accurate prediction of traffic flow. Finally, experiments are implemented based on real-scenario public transportation datasets (PEMS04 and PEMS08) to demonstrate that our approach can achieve state-of-the-art performance.
MAMCA -- Optimal on Accuracy and Efficiency for Automatic Modulation Classification with Extended Signal Length
May 18, 2024With the rapid growth of the Internet of Things ecosystem, Automatic Modulation Classification (AMC) has become increasingly paramount. However, extended signal lengths offer a bounty of information, yet impede the model's adaptability, introduce more noise interference, extend the training and inference time, and increase storage overhead. To bridge the gap between these requisites, we propose a novel AMC framework, designated as the Mamba-based Automatic Modulation ClassificAtion (MAMCA). Our method adeptly addresses the accuracy and efficiency requirements for long-sequence AMC. Specifically, we introduce the Selective State Space Model as the backbone, enhancing the model efficiency by reducing the dimensions of the state matrices and diminishing the frequency of information exchange across GPU memories. We design a denoising-capable unit to elevate the network's performance under low signal-to-noise radio. Rigorous experimental evaluations on the publicly available dataset RML2016.10, along with our synthetic dataset within multiple quadrature amplitude modulations and lengths, affirm that MAMCA delivers superior recognition accuracy while necessitating minimal computational time and memory occupancy. Codes are available on https://github.com/ZhangYezhuo/MAMCA.
Specific Emitter Identification Handling Modulation Variation with Margin Disparity Discrepancy
Mar 18, 2024



In the domain of Specific Emitter Identification (SEI), it is recognized that transmitters can be distinguished through the impairments of their radio frequency front-end, commonly referred to as Radio Frequency Fingerprint (RFF) features. However, modulation schemes can be deliberately coupled into signal-level data to confound RFF information, often resulting in high susceptibility to failure in SEI. In this paper, we propose a domain-invariant feature oriented Margin Disparity Discrepancy (MDD) approach to enhance SEI's robustness in rapidly modulation-varying environments. First, we establish an upper bound for the difference between modulation domains and define the loss function accordingly. Then, we design an adversarial network framework incorporating MDD to align variable modulation features. Finally, We conducted experiments utilizing 7 HackRF-One transmitters, emitting 11 types of signals with analog and digital modulations. Numerical results indicate that our approach achieves an average improvement of over 20\% in accuracy compared to classical SEI methods and outperforms other UDA techniques. Codes are available at https://github.com/ZhangYezhuo/MDD-SEI.
CILF:Causality Inspired Learning Framework for Out-of-Distribution Vehicle Trajectory Prediction
Jul 11, 2023



Trajectory prediction is critical for autonomous driving vehicles. Most existing methods tend to model the correlation between history trajectory (input) and future trajectory (output). Since correlation is just a superficial description of reality, these methods rely heavily on the i.i.d. assumption and evince a heightened susceptibility to out-of-distribution data. To address this problem, we propose an Out-of- Distribution Causal Graph (OOD-CG), which explicitly defines the underlying causal structure of the data with three entangled latent features: 1) domain-invariant causal feature (IC), 2) domain-variant causal feature (VC), and 3) domain-variant non-causal feature (VN ). While these features are confounded by confounder (C) and domain selector (D). To leverage causal features for prediction, we propose a Causal Inspired Learning Framework (CILF), which includes three steps: 1) extracting domain-invariant causal feature by means of an invariance loss, 2) extracting domain variant feature by domain contrastive learning, and 3) separating domain-variant causal and non-causal feature by encouraging causal sufficiency. We evaluate the performance of CILF in different vehicle trajectory prediction models on the mainstream datasets NGSIM and INTERACTION. Experiments show promising improvements in CILF on domain generalization.
Contrastive Embedding Distribution Refinement and Entropy-Aware Attention for 3D Point Cloud Classification
Jan 27, 2022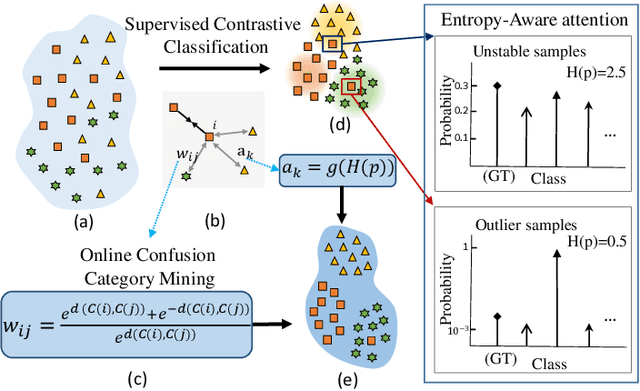
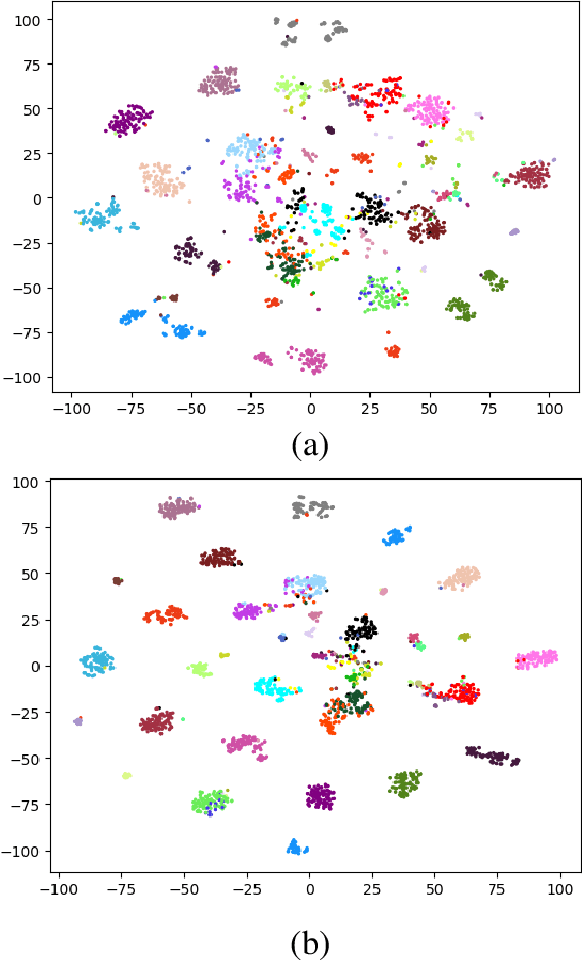
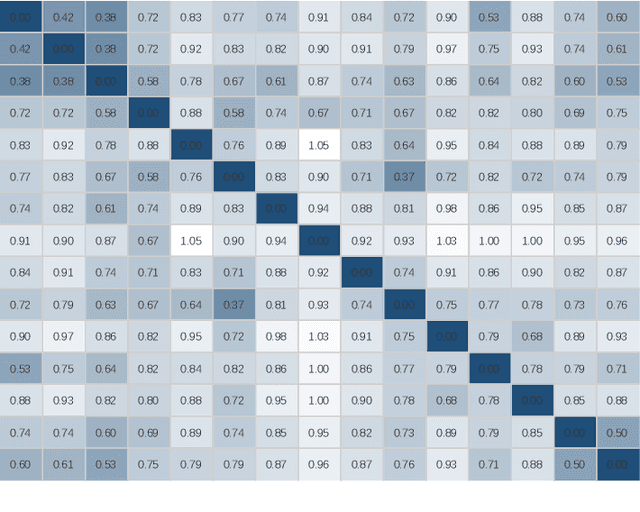
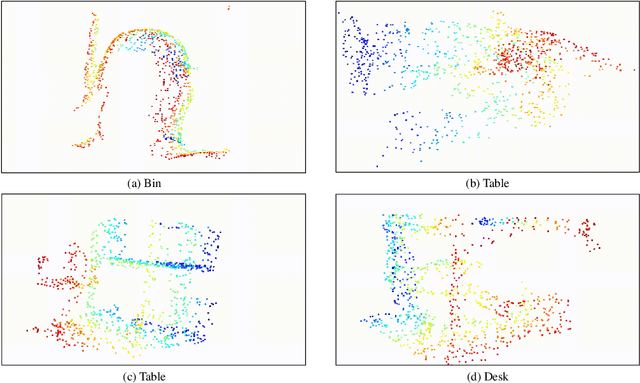
Learning a powerful representation from point clouds is a fundamental and challenging problem in the field of computer vision. Different from images where RGB pixels are stored in the regular grid, for point clouds, the underlying semantic and structural information of point clouds is the spatial layout of the points. Moreover, the properties of challenging in-context and background noise pose more challenges to point cloud analysis. One assumption is that the poor performance of the classification model can be attributed to the indistinguishable embedding feature that impedes the search for the optimal classifier. This work offers a new strategy for learning powerful representations via a contrastive learning approach that can be embedded into any point cloud classification network. First, we propose a supervised contrastive classification method to implement embedding feature distribution refinement by improving the intra-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class variations between some similar-looking categories, we propose a confusion-prone class mining strategy to alleviate the confusion effect. Finally, considering that outliers of the sample clusters in the embedding space may cause performance degradation, we design an entropy-aware attention module with information entropy theory to identify the outlier cases and the unstable samples by measuring the uncertainty of predicted probability. The results of extensive experiments demonstrate that our method outperforms the state-of-the-art approaches by achieving 82.9% accuracy on the real-world ScanObjectNN dataset and substantial performance gains up to 2.9% in DCGNN, 3.1% in PointNet++, and 2.4% in GBNet.
Hierarchical Motion Encoder-Decoder Network for Trajectory Forecasting
Nov 26, 2021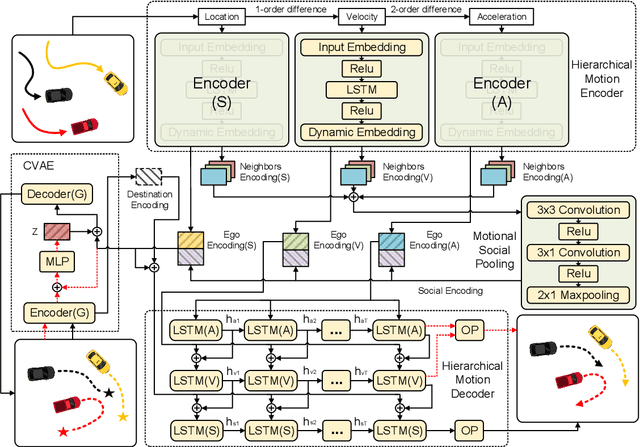
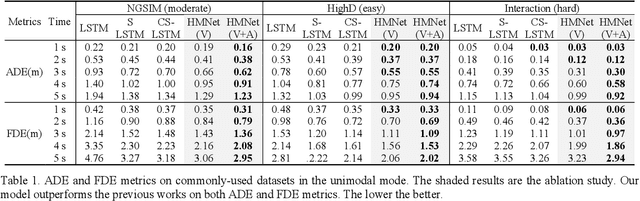
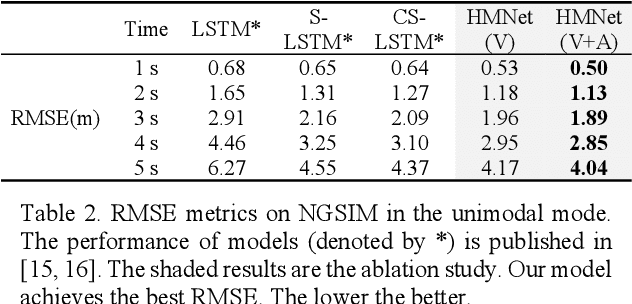
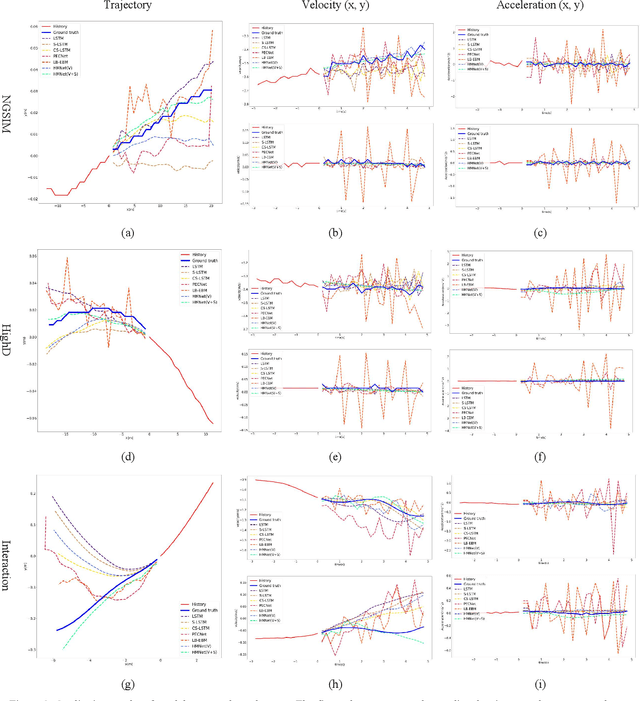
Trajectory forecasting plays a pivotal role in the field of intelligent vehicles or social robots. Recent works focus on modeling spatial social impacts or temporal motion attentions, but neglect inherent properties of motions, i.e. moving trends and driving intentions. This paper proposes a context-free Hierarchical Motion Encoder-Decoder Network (HMNet) for vehicle trajectory prediction. HMNet first infers the hierarchical difference on motions to encode physically compliant patterns with high expressivity of moving trends and driving intentions. Then, a goal (endpoint)-embedded decoder hierarchically constructs multimodal predictions depending on the location-velocity-acceleration-related patterns. Besides, we present a modified social pooling module which considers certain motion properties to represent social interactions. HMNet enables to make the accurate, unimodal/multimodal and physically-socially-compliant prediction. Experiments on three public trajectory prediction datasets, i.e. NGSIM, HighD and Interaction show that our model achieves the state-of-the-art performance both quantitatively and qualitatively. We will release our code here: https://github.com/xuedashuai/HMNet.
Deep Kalman Filter: A Refinement Module for the Rollout Trajectory Prediction Methods
Feb 22, 2021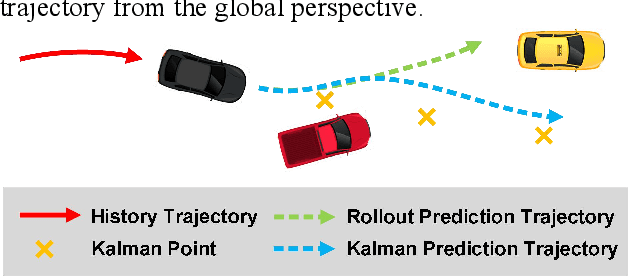

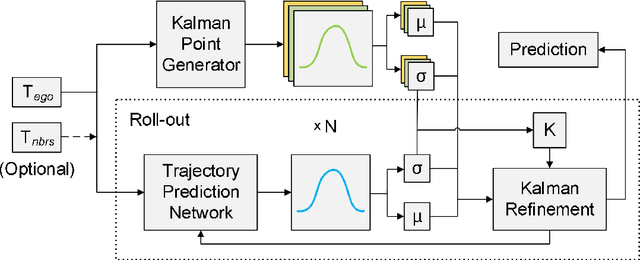
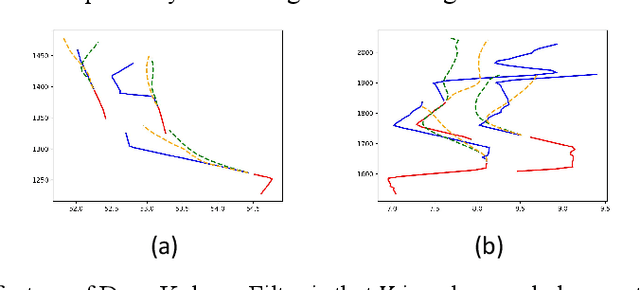
Trajectory prediction plays a pivotal role in the field of intelligent vehicles. It currently suffers from several challenges, e.g., accumulative error in rollout process and weak adaptability in various scenarios. This paper proposes a parametric-learning Kalman filter based on deep neural network for trajectory prediction. We design a flexible plug-in module which can be readily implanted into most rollout approaches. Kalman points are proposed to capture the long-term prediction stability from the global perspective. We carried experiments out on the NGSIM dataset. The promising results indicate that our method could improve rollout trajectory prediction methods effectively.
Spatial-Channel Transformer Network for Trajectory Prediction on the Traffic Scenes
Feb 05, 2021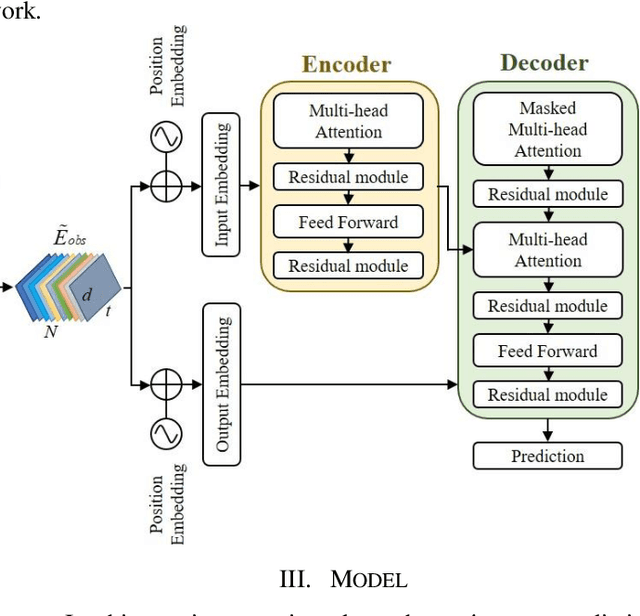
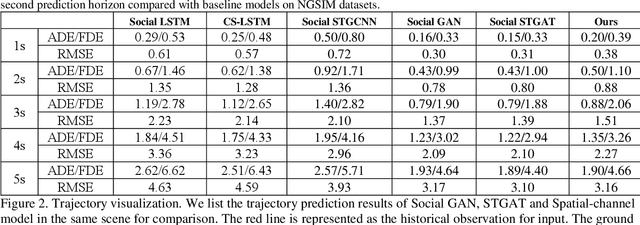
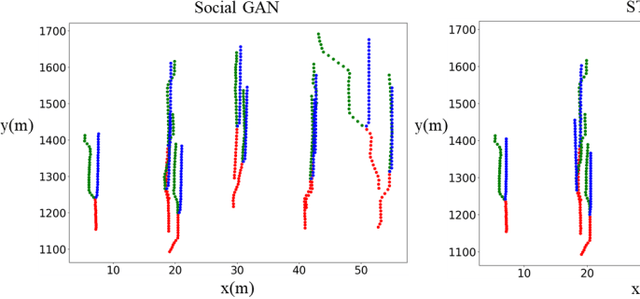
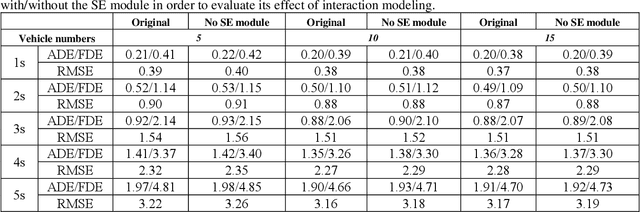
Predicting motion of surrounding agents is critical to real-world applications of tactical path planning for autonomous driving. Due to the complex temporal dependencies and social interactions of agents, on-line trajectory prediction is a challenging task. With the development of attention mechanism in recent years, transformer model has been applied in natural language sequence processing first and then image processing. In this paper, we present a Spatial-Channel Transformer Network for trajectory prediction with attention functions. Instead of RNN models, we employ transformer model to capture the spatial-temporal features of agents. A channel-wise module is inserted to measure the social interaction between agents. We find that the Spatial-Channel Transformer Network achieves promising results on real-world trajectory prediction datasets on the traffic scenes.
Semi-Dense 3D Semantic Mapping from Monocular SLAM
Nov 13, 2016
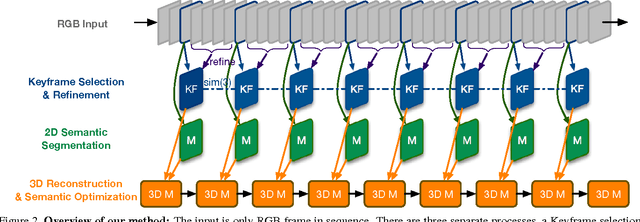

The bundle of geometry and appearance in computer vision has proven to be a promising solution for robots across a wide variety of applications. Stereo cameras and RGB-D sensors are widely used to realise fast 3D reconstruction and trajectory tracking in a dense way. However, they lack flexibility of seamless switch between different scaled environments, i.e., indoor and outdoor scenes. In addition, semantic information are still hard to acquire in a 3D mapping. We address this challenge by combining the state-of-art deep learning method and semi-dense Simultaneous Localisation and Mapping (SLAM) based on video stream from a monocular camera. In our approach, 2D semantic information are transferred to 3D mapping via correspondence between connective Keyframes with spatial consistency. There is no need to obtain a semantic segmentation for each frame in a sequence, so that it could achieve a reasonable computation time. We evaluate our method on indoor/outdoor datasets and lead to an improvement in the 2D semantic labelling over baseline single frame predictions.