 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Dense 3D Semantic Mapping from Monocular SLAM
Nov 13, 2016
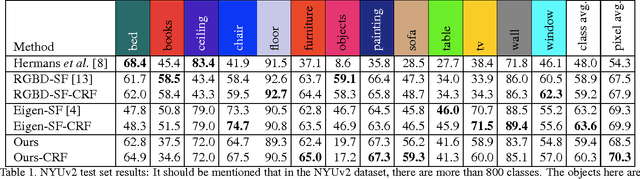
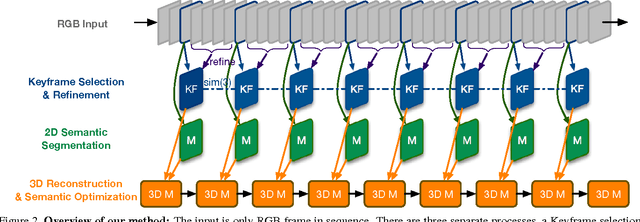

The bundle of geometry and appearance in computer vision has proven to be a promising solution for robots across a wide variety of applications. Stereo cameras and RGB-D sensors are widely used to realise fast 3D reconstruction and trajectory tracking in a dense way. However, they lack flexibility of seamless switch between different scaled environments, i.e., indoor and outdoor scenes. In addition, semantic information are still hard to acquire in a 3D mapping. We address this challenge by combining the state-of-art deep learning method and semi-dense Simultaneous Localisation and Mapping (SLAM) based on video stream from a monocular camera. In our approach, 2D semantic information are transferred to 3D mapping via correspondence between connective Keyframes with spatial consistency. There is no need to obtain a semantic segmentation for each frame in a sequence, so that it could achieve a reasonable computation time. We evaluate our method on indoor/outdoor datasets and lead to an improvement in the 2D semantic labelling over baseline single frame predictions.