 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Highly Efficient Capsule Networks Processing Through A PIM-Based Architecture Design
Paper and Code
Nov 07, 2019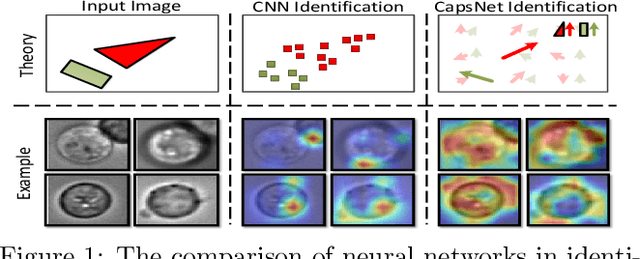

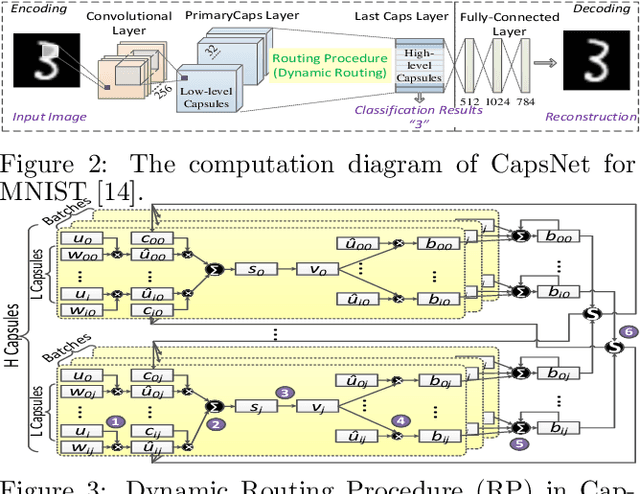
In recent years, the CNNs have achieved great successes in the image processing tasks, e.g., image recognition and object detection. Unfortunately, traditional CNN's classification is found to be easily misled by increasingly complex image features due to the usage of pooling operations, hence unable to preserve accurate position and pose information of the objects. To address this challenge, a novel neural network structure called Capsule Network has been proposed, which introduces equivariance through capsules to significantly enhance the learning ability for image segmentation and object detection. Due to its requirement of performing a high volume of matrix operations, CapsNets have been generally accelerated on modern GPU platforms that provide highly optimized software library for common deep learning tasks. However, based on our performance characterization on modern GPUs, CapsNets exhibit low efficiency due to the special program and execution features of their routing procedure, including massive unshareable intermediate variables and intensive synchronizations, which are very difficult to optimize at software level. To address these challenges, we propose a hybrid computing architecture design named \textit{PIM-CapsNet}. It preserves GPU's on-chip computing capability for accelerating CNN types of layers in CapsNet, while pipelining with an off-chip in-memory acceleration solution that effectively tackles routing procedure's inefficiency by leveraging the processing-in-memory capability of today's 3D stacked memory. Using routing procedure's inherent parallellization feature, our design enables hierarchical improvements on CapsNet inference efficiency through minimizing data movement and maximizing parallel processing in memory.