 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Jan 27, 2026Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/
Visual Fourier Prompt Tuning
Nov 02, 2024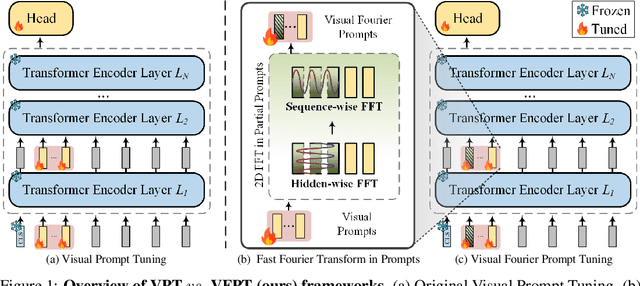
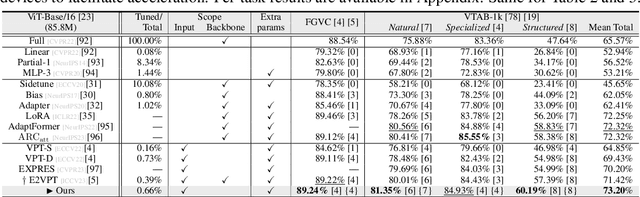
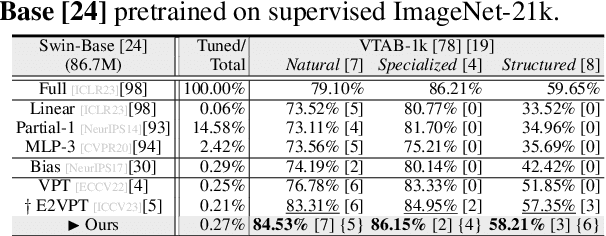
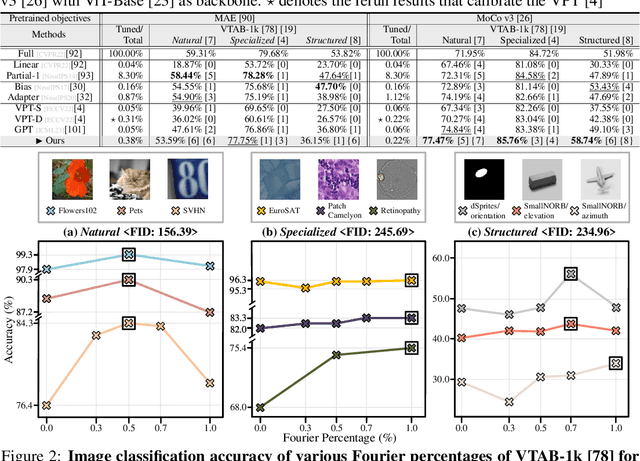
With the scale of vision Transformer-based models continuing to grow, finetuning these large-scale pretrained models for new tasks has become increasingly parameter-intensive. Visual prompt tuning is introduced as a parameter-efficient finetuning (PEFT) method to this trend. Despite its successes, a notable research challenge persists within almost all PEFT approaches: significant performance degradation is observed when there is a substantial disparity between the datasets applied in pretraining and finetuning phases. To address this challenge, we draw inspiration from human visual cognition, and propose the Visual Fourier Prompt Tuning (VFPT) method as a general and effective solution for adapting large-scale transformer-based models. Our approach innovatively incorporates the Fast Fourier Transform into prompt embeddings and harmoniously considers both spatial and frequency domain information. Apart from its inherent simplicity and intuitiveness, VFPT exhibits superior performance across all datasets, offering a general solution to dataset challenges, irrespective of data disparities. Empirical results demonstrate that our approach outperforms current state-of-the-art baselines on two benchmarks, with low parameter usage (e.g., 0.57% of model parameters on VTAB-1k) and notable performance enhancements (e.g., 73.20% of mean accuracy on VTAB-1k). Our code is avaliable at https://github.com/runtsang/VFPT.