 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUWB-GCN: Hardware Acceleration of Graph-Convolution-Network through Runtime Workload Rebalancing
Aug 23, 2019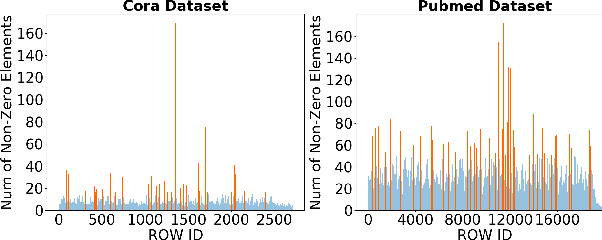
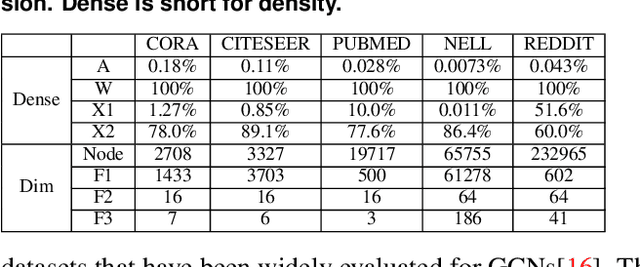
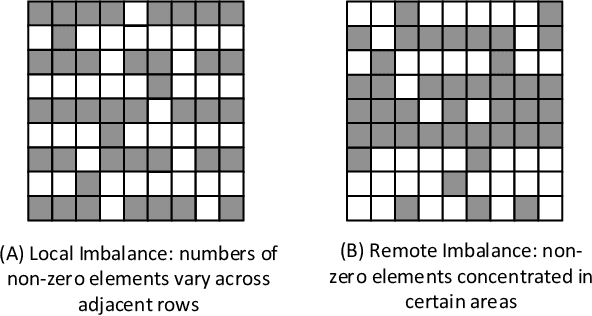
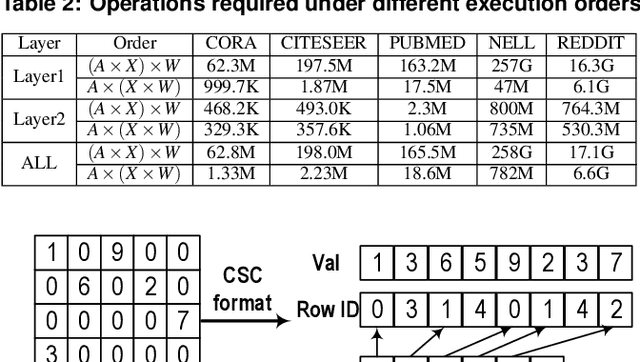
The recent development of deep learning has mostly been focusing on Euclidean data, such as images, videos, and audios. However, most real-world information and relationships are often expressed in graphs. Graph convolutional networks (GCNs) appear as a promising approach to efficiently learn from graph data structures, showing advantages in several practical applications such as social network analysis, knowledge discovery, 3D modeling, and motion capturing. However, practical graphs are often extremely large and unbalanced, posting significant performance demand and design challenges on the hardware dedicated to GCN inference. In this paper, we propose an architecture design called Ultra-Workload-Balanced-GCN (UWB-GCN) to accelerate graph convolutional network inference. To tackle the major performance bottleneck of workload imbalance, we propose two techniques: dynamic local sharing and dynamic remote switching, both of which rely on hardware flexibility to achieve performance auto-tuning with negligible area or delay overhead. Specifically, UWB-GCN is able to effectively profile the sparse graph pattern while continuously adjusting the workload distribution among parallel processing elements (PEs). After converging, the ideal configuration is reused for the remaining iterations. To the best of our knowledge, this is the first accelerator design targeted to GCNs and the first work that auto-tunes workload balance in accelerator at runtime through hardware, rather than software, approaches. Our methods can achieve near-ideal workload balance in processing sparse matrices. Experimental results show that UWB-GCN can finish the inference of the Nell graph (66K vertices, 266K edges) in 8.4ms, corresponding to 192x, 289x, and 7.3x respectively, compared to the CPU, GPU, and the baseline GCN design without workload rebalancing.