 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Framework for Acceleration of CNN Training on Deeply-Pipelined FPGA Clusters with Weight and Workload Balancing
Paper and Code
Jan 04, 2019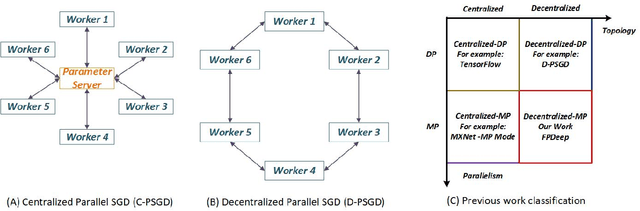
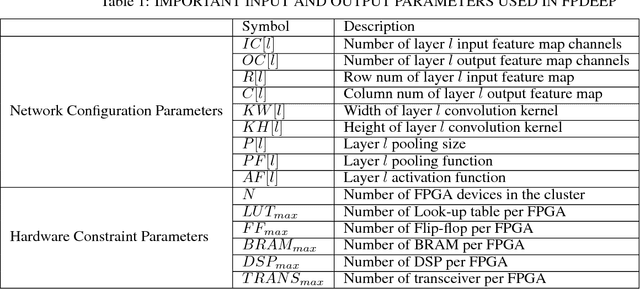
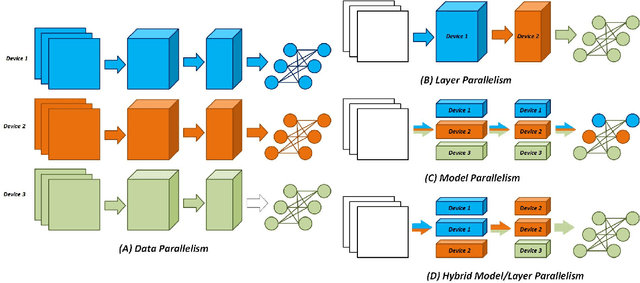
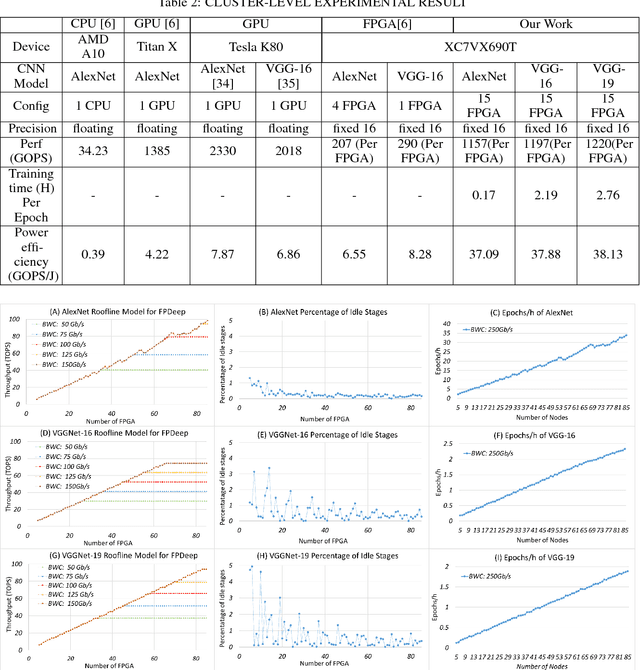
Deep Neural Networks (DNNs) have revolutionized numerous applications, but the demand for ever more performance remains unabated. Scaling DNN computations to larger clusters is generally done by distributing tasks in batch mode using methods such as distributed synchronous SGD. Among the issues with this approach is that to make the distributed cluster work with high utilization, the workload distributed to each node must be large, which implies nontrivial growth in the SGD mini-batch size. In this paper, we propose a framework called FPDeep, which uses a hybrid of model and layer parallelism to configure distributed reconfigurable clusters to train DNNs. This approach has numerous benefits. First, the design does not suffer from batch size growth. Second, novel workload and weight partitioning leads to balanced loads of both among nodes. And third, the entire system is a fine-grained pipeline. This leads to high parallelism and utilization and also minimizes the time features need to be cached while waiting for back-propagation. As a result, storage demand is reduced to the point where only on-chip memory is used for the convolution layers. We evaluate FPDeep with the Alexnet, VGG-16, and VGG-19 benchmarks. Experimental results show that FPDeep has good scalability to a large number of FPGAs, with the limiting factor being the FPGA-to-FPGA bandwidth. With 6 transceivers per FPGA, FPDeep shows linearity up to 83 FPGAs. Energy efficiency is evaluated with respect to GOPs/J. FPDeep provides, on average, 6.36x higher energy efficiency than comparable GPU servers.