 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-inspired Federated Learning for Dynamic Spatio-Temporal Graphs
Mar 31, 2026Federated Graph Learning (FGL) has emerged as a powerful paradigm for decentralized training of graph neural networks while preserving data privacy. However, existing FGL methods are predominantly designed for static graphs and rely on parameter averaging or distribution alignment, which implicitly assume that all features are equally transferable across clients, overlooking both the spatial and temporal heterogeneity and the presence of client-specific knowledge in real-world graphs. In this work, we identify that such assumptions create a vicious cycle of spurious representation entanglement, client-specific interference, and negative transfer, degrading generalization performance in Federated Learning over Dynamic Spatio-Temporal Graphs (FSTG). To address this issue, we propose a novel causality-inspired framework named SC-FSGL, which explicitly decouples transferable causal knowledge from client-specific noise through representation-level interventions. Specifically, we introduce a Conditional Separation Module that simulates soft interventions through client conditioned masks, enabling the disentanglement of invariant spatio-temporal causal factors from spurious signals and mitigating representation entanglement caused by client heterogeneity. In addition, we propose a Causal Codebook that clusters causal prototypes and aligns local representations via contrastive learning, promoting cross-client consistency and facilitating knowledge sharing across diverse spatio-temporal patterns. Experiments on five diverse heterogeneity Spatio-Temporal Graph (STG) datasets show that SC-FSGL outperforms state-of-the-art methods.
Event-VStream: Event-Driven Real-Time Understanding for Long Video Streams
Jan 22, 2026Real-time understanding of long video streams remains challenging for multimodal large language models (VLMs) due to redundant frame processing and rapid forgetting of past context. Existing streaming systems rely on fixed-interval decoding or cache pruning, which either produce repetitive outputs or discard crucial temporal information. We introduce Event-VStream, an event-aware framework that represents continuous video as a sequence of discrete, semantically coherent events. Our system detects meaningful state transitions by integrating motion, semantic, and predictive cues, and triggers language generation only at those boundaries. Each event embedding is consolidated into a persistent memory bank, enabling long-horizon reasoning while maintaining low latency. Across OVOBench-Realtime, and long-form Ego4D evaluations, Event-VStream achieves competitive performance. It improves over a VideoLLM-Online-8B baseline by +10.4 points on OVOBench-Realtime, achieves performance close to Flash-VStream-7B despite using only a general-purpose LLaMA-3-8B text backbone, and maintains around 70% GPT-5 win rate on 2-hour Ego4D streams.
SDiT: Semantic Region-Adaptive for Diffusion Transformers
Jan 18, 2026Diffusion Transformers (DiTs) achieve state-of-the-art performance in text-to-image synthesis but remain computationally expensive due to the iterative nature of denoising and the quadratic cost of global attention. In this work, we observe that denoising dynamics are spatially non-uniform-background regions converge rapidly while edges and textured areas evolve much more actively. Building on this insight, we propose SDiT, a Semantic Region-Adaptive Diffusion Transformer that allocates computation according to regional complexity. SDiT introduces a training-free framework combining (1) semantic-aware clustering via fast Quickshift-based segmentation, (2) complexity-driven regional scheduling to selectively update informative areas, and (3) boundary-aware refinement to maintain spatial coherence. Without any model retraining or architectural modification, SDiT achieves up to 3.0x acceleration while preserving nearly identical perceptual and semantic quality to full-attention inference.
IGenBench: Benchmarking the Reliability of Text-to-Infographic Generation
Jan 08, 2026Infographics are composite visual artifacts that combine data visualizations with textual and illustrative elements to communicate information. While recent text-to-image (T2I) models can generate aesthetically appealing images, their reliability in generating infographics remains unclear. Generated infographics may appear correct at first glance but contain easily overlooked issues, such as distorted data encoding or incorrect textual content. We present IGENBENCH, the first benchmark for evaluating the reliability of text-to-infographic generation, comprising 600 curated test cases spanning 30 infographic types. We design an automated evaluation framework that decomposes reliability verification into atomic yes/no questions based on a taxonomy of 10 question types. We employ multimodal large language models (MLLMs) to verify each question, yielding question-level accuracy (Q-ACC) and infographic-level accuracy (I-ACC). We comprehensively evaluate 10 state-of-the-art T2I models on IGENBENCH. Our systematic analysis reveals key insights for future model development: (i) a three-tier performance hierarchy with the top model achieving Q-ACC of 0.90 but I-ACC of only 0.49; (ii) data-related dimensions emerging as universal bottlenecks (e.g., Data Completeness: 0.21); and (iii) the challenge of achieving end-to-end correctness across all models. We release IGENBENCH at https://igen-bench.vercel.app/.
Treatment response as a latent variable
Feb 12, 2025Scientists often need to analyze the samples in a study that responded to treatment in order to refine their hypotheses and find potential causal drivers of response. Natural variation in outcomes makes teasing apart responders from non-responders a statistical inference problem. To handle latent responses, we introduce the causal two-groups (C2G) model, a causal extension of the classical two-groups model. The C2G model posits that treated samples may or may not experience an effect, according to some prior probability. We propose two empirical Bayes procedures for the causal two-groups model, one under semi-parametric conditions and another under fully nonparametric conditions. The semi-parametric model assumes additive treatment effects and is identifiable from observed data. The nonparametric model is unidentifiable, but we show it can still be used to test for response in each treated sample. We show empirically and theoretically that both methods for selecting responders control the false discovery rate at the target level with near-optimal power. We also propose two novel estimands of interest and provide a strategy for deriving estimand intervals in the unidentifiable nonparametric model. On a cancer immunotherapy dataset, the nonparametric C2G model recovers clinically-validated predictive biomarkers of both positive and negative outcomes. Code is available at https://github.com/tansey-lab/causal2groups.
NeurLZ: On Enhancing Lossy Compression Performance based on Error-Controlled Neural Learning for Scientific Data
Sep 10, 2024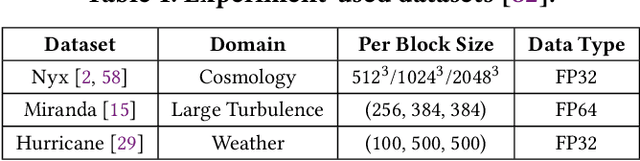



Large-scale scientific simulations generate massive datasets that pose significant challenges for storage and I/O. While traditional lossy compression techniques can improve performance, balancing compression ratio, data quality, and throughput remains difficult. To address this, we propose NeurLZ, a novel cross-field learning-based and error-controlled compression framework for scientific data. By integrating skipping DNN models, cross-field learning, and error control, our framework aims to substantially enhance lossy compression performance. Our contributions are three-fold: (1) We design a lightweight skipping model to provide high-fidelity detail retention, further improving prediction accuracy. (2) We adopt a cross-field learning approach to significantly improve data prediction accuracy, resulting in a substantially improved compression ratio. (3) We develop an error control approach to provide strict error bounds according to user requirements. We evaluated NeurLZ on several real-world HPC application datasets, including Nyx (cosmological simulation), Miranda (large turbulence simulation), and Hurricane (weather simulation). Experiments demonstrate that our framework achieves up to a 90% relative reduction in bit rate under the same data distortion, compared to the best existing approach.
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
NEPHELE: A Neural Platform for Highly Realistic Cloud Radiance Rendering
Mar 07, 2023We have recently seen tremendous progress in neural rendering (NR) advances, i.e., NeRF, for photo-real free-view synthesis. Yet, as a local technique based on a single computer/GPU, even the best-engineered Instant-NGP or i-NGP cannot reach real-time performance when rendering at a high resolution, and often requires huge local computing resources. In this paper, we resort to cloud rendering and present NEPHELE, a neural platform for highly realistic cloud radiance rendering. In stark contrast with existing NR approaches, our NEPHELE allows for more powerful rendering capabilities by combining multiple remote GPUs and facilitates collaboration by allowing multiple people to view the same NeRF scene simultaneously. We introduce i-NOLF to employ opacity light fields for ultra-fast neural radiance rendering in a one-query-per-ray manner. We further resemble the Lumigraph with geometry proxies for fast ray querying and subsequently employ a small MLP to model the local opacity lumishperes for high-quality rendering. We also adopt Perfect Spatial Hashing in i-NOLF to enhance cache coherence. As a result, our i-NOLF achieves an order of magnitude performance gain in terms of efficiency than i-NGP, especially for the multi-user multi-viewpoint setting under cloud rendering scenarios. We further tailor a task scheduler accompanied by our i-NOLF representation and demonstrate the advance of our methodological design through a comprehensive cloud platform, consisting of a series of cooperated modules, i.e., render farms, task assigner, frame composer, and detailed streaming strategies. Using such a cloud platform compatible with neural rendering, we further showcase the capabilities of our cloud radiance rendering through a series of applications, ranging from cloud VR/AR rendering.
Easy Begun is Half Done: Spatial-Temporal Graph Modeling with ST-Curriculum Dropout
Nov 28, 2022



Spatial-temporal (ST) graph modeling, such as traffic speed forecasting and taxi demand prediction, is an important task in deep learning area. However, for the nodes in graph, their ST patterns can vary greatly in difficulties for modeling, owning to the heterogeneous nature of ST data. We argue that unveiling the nodes to the model in a meaningful order, from easy to complex, can provide performance improvements over traditional training procedure. The idea has its root in Curriculum Learning which suggests in the early stage of training models can be sensitive to noise and difficult samples. In this paper, we propose ST-Curriculum Dropout, a novel and easy-to-implement strategy for spatial-temporal graph modeling. Specifically, we evaluate the learning difficulty of each node in high-level feature space and drop those difficult ones out to ensure the model only needs to handle fundamental ST relations at the beginning, before gradually moving to hard ones. Our strategy can be applied to any canonical deep learning architecture without extra trainable parameters, and extensive experiments on a wide range of datasets are conducted to illustrate that, by controlling the difficulty level of ST relations as the training progresses, the model is able to capture better representation of the data and thus yields better generalization.
Multi-task Deep Neural Networks for Massive MIMO CSI Feedback
Apr 18, 2022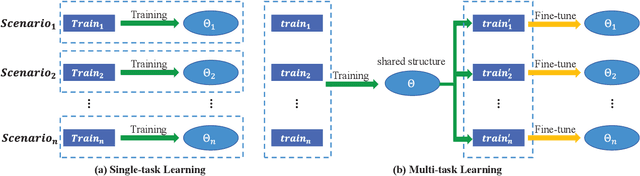
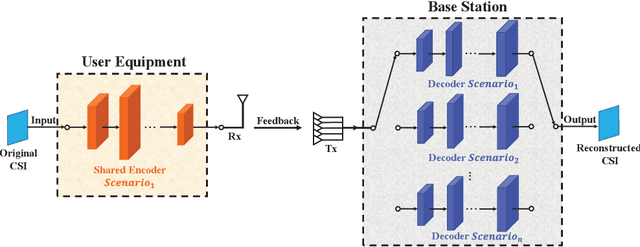
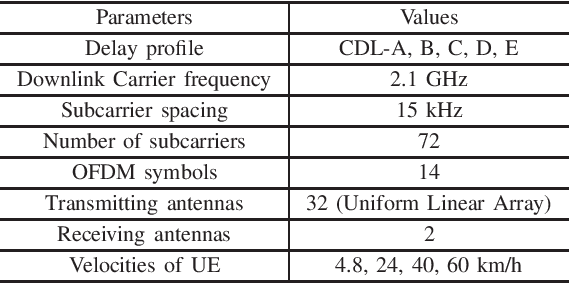
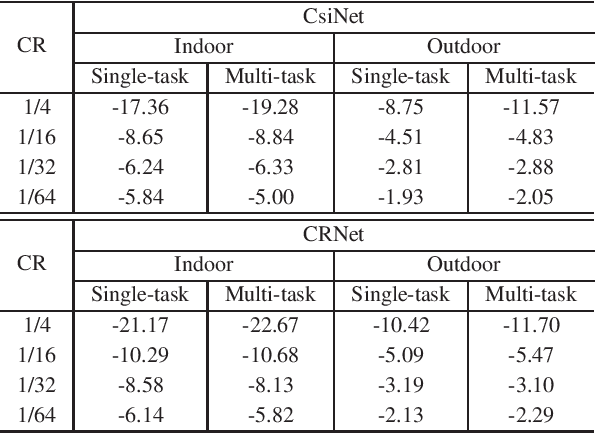
Deep learning has been widely applied for the channel state information (CSI) feedback in frequency division duplexing (FDD) massive multiple-input multiple-output (MIMO) system. For the typical supervised training of the feedback model, the requirements of large amounts of task-specific labeled data can hardly be satisfied, and the huge training costs and storage usage of the model in multiple scenarios are hindrance for model application. In this letter, a multi-task learning-based approach is proposed to improve the feasibility of the feedback network. An encoder-shared feedback architecture and the corresponding training scheme are further proposed to facilitate the implementation of the multi-task learning approach. The experimental results indicate that the proposed multi-task learning approach can achieve comprehensive feedback performance with considerable reduction of training cost and storage usage of the feedback model.