 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
Privacy Preserving Semantic Communications Using Vision Language Models: A Segmentation and Generation Approach
Sep 09, 2025Semantic communication has emerged as a promising paradigm for next-generation wireless systems, improving the communication efficiency by transmitting high-level semantic features. However, reliance on unimodal representations can degrade reconstruction under poor channel conditions, and privacy concerns of the semantic information attack also gain increasing attention. In this work, a privacy-preserving semantic communication framework is proposed to protect sensitive content of the image data. Leveraging a vision-language model (VLM), the proposed framework identifies and removes private content regions from input images prior to transmission. A shared privacy database enables semantic alignment between the transmitter and receiver to ensure consistent identification of sensitive entities. At the receiver, a generative module reconstructs the masked regions using learned semantic priors and conditioned on the received text embedding. Simulation results show that generalizes well to unseen image processing tasks, improves reconstruction quality at the authorized receiver by over 10% using text embedding, and reduces identity leakage to the eavesdropper by more than 50%.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Apr 10, 2024
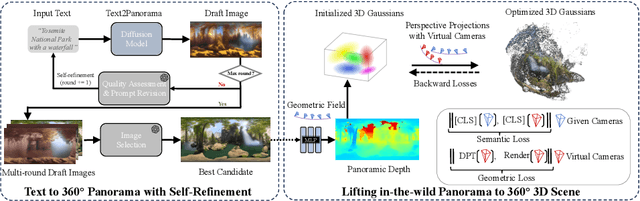
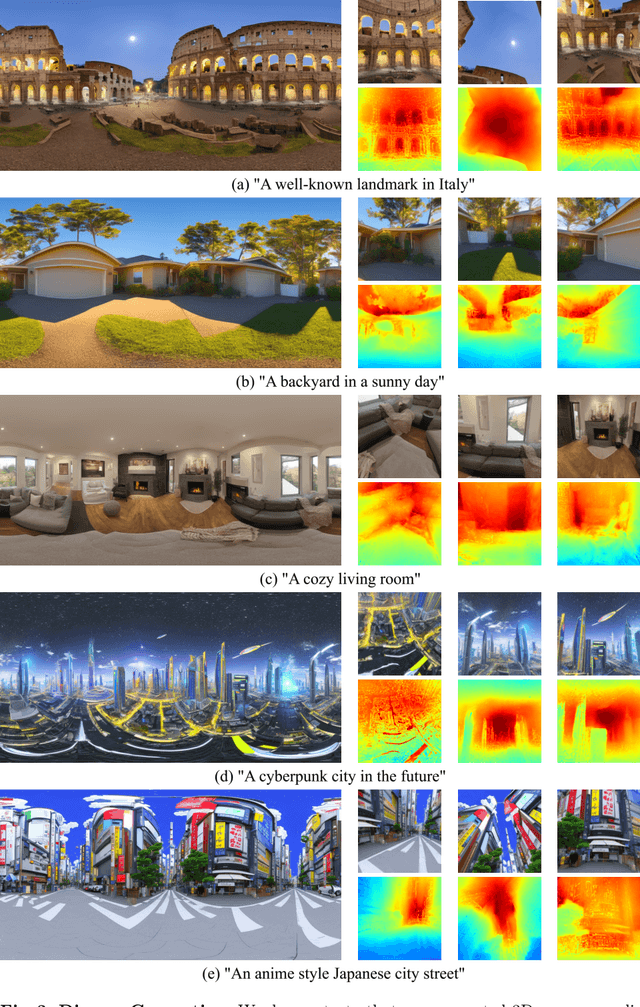

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Dec 06, 2023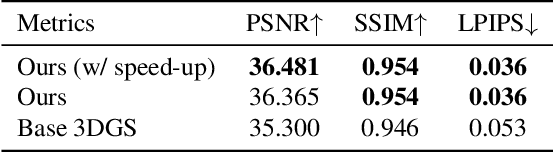
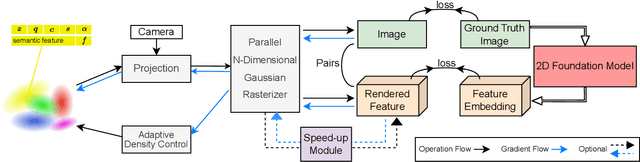
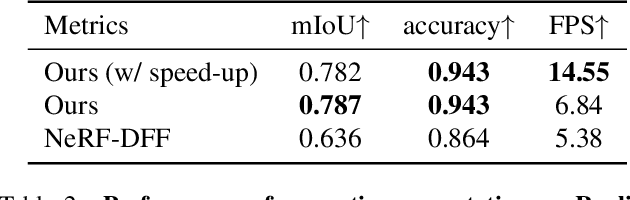
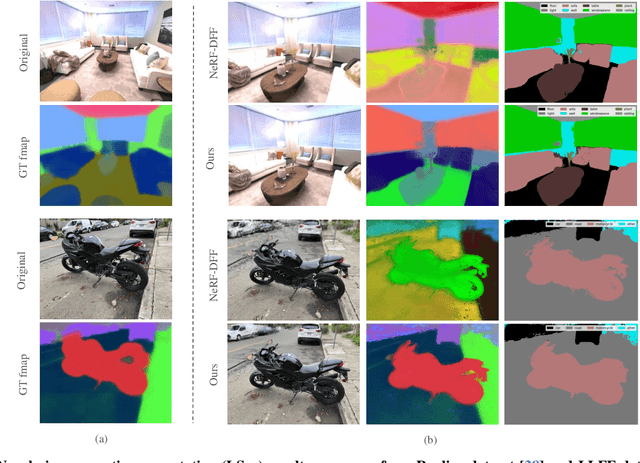
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework leads to warp-level divergence. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
Changeable Rate and Novel Quantization for CSI Feedback Based on Deep Learning
Feb 28, 2022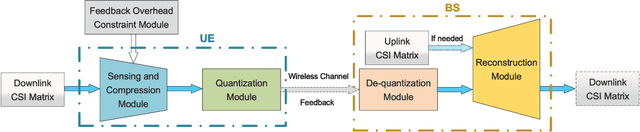
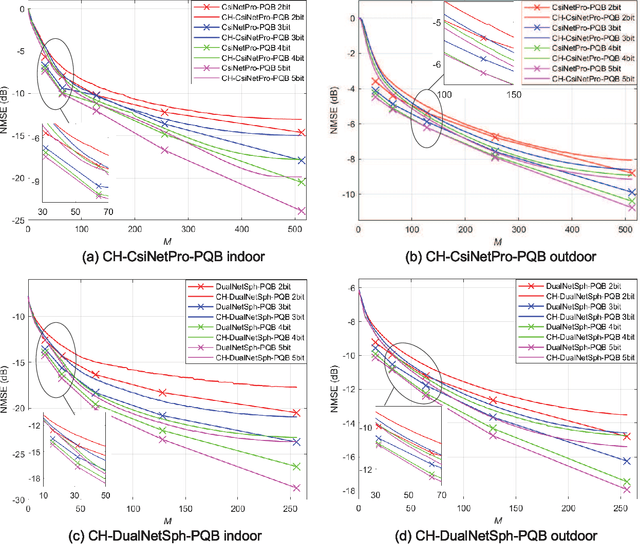

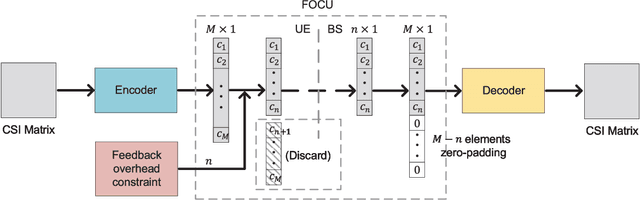
Deep learning (DL)-based channel state information (CSI) feedback improves the capacity and energy efficiency of massive multiple-input multiple-output (MIMO) systems in frequency division duplexing mode. However, multiple neural networks with different lengths of feedback overhead are required by time-varying bandwidth resources. The storage space required at the user equipment (UE) and the base station (BS) for these models increases linearly with the number of models. In this paper, we propose a DL-based changeable-rate framework with novel quantization scheme to improve the efficiency and feasibility of CSI feedback systems. This framework can reutilize all the network layers to achieve overhead-changeable CSI feedback to optimize the storage efficiency at the UE and the BS sides. Designed quantizer in this framework can avoid the normalization and gradient problems faced by traditional quantization schemes. Specifically, we propose two DL-based changeable-rate CSI feedback networks CH-CsiNetPro and CH-DualNetSph by introducing a feedback overhead control unit. Then, a pluggable quantization block (PQB) is developed to further improve the encoding efficiency of CSI feedback in an end-to-end way. Compared with existing CSI feedback methods, the proposed framework saves the storage space by about 50% with changeable-rate scheme and improves the encoding efficiency with the quantization module.
CSI Sensing and Feedback: A Semi-Supervised Learning Approach
Sep 26, 2021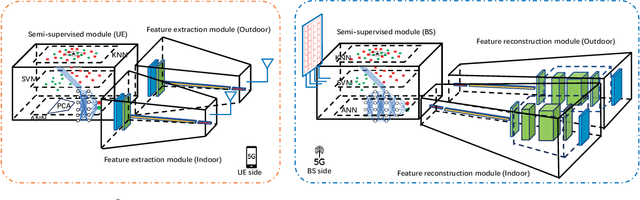
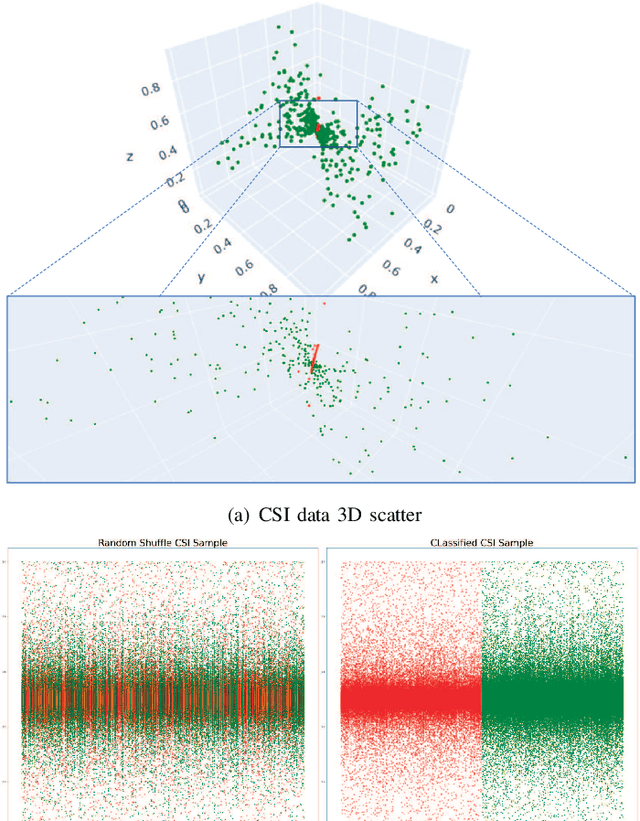
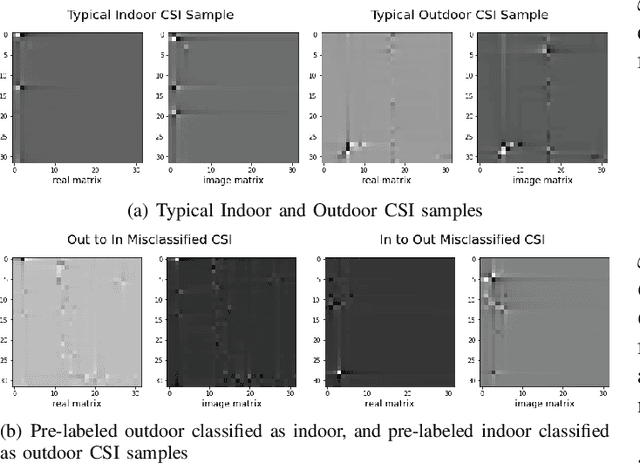

Deep learning-based (DL-based) channel state information (CSI) feedback for a Massive multiple-input multiple-output (MIMO) system has proved to be a creative and efficient application. However, the existing systems ignored the wireless channel environment variation sensing, e.g., indoor and outdoor scenarios. Moreover, systems training requires excess pre-labeled CSI data, which is often unavailable. In this letter, to address these issues, we first exploit the rationality of introducing semi-supervised learning on CSI feedback, then one semi-supervised CSI sensing and feedback Network ($S^2$CsiNet) with three classifiers comparisons is proposed. Experiment shows that $S^2$CsiNet primarily improves the feasibility of the DL-based CSI feedback system by \textbf{\textit{indoor}} and \textbf{\textit{outdoor}} environment sensing and at most 96.2\% labeled dataset decreasing and secondarily boost the system performance by data distillation and latent information mining.