 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025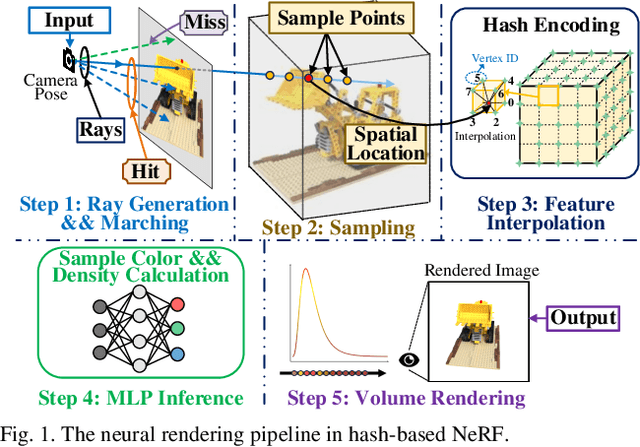
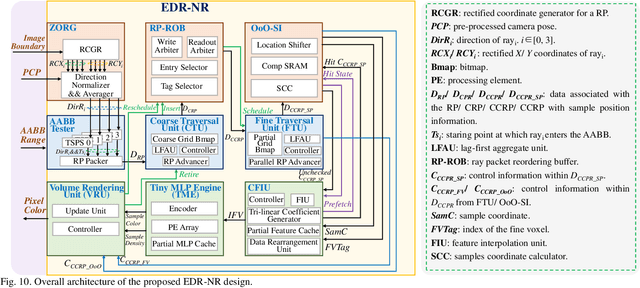
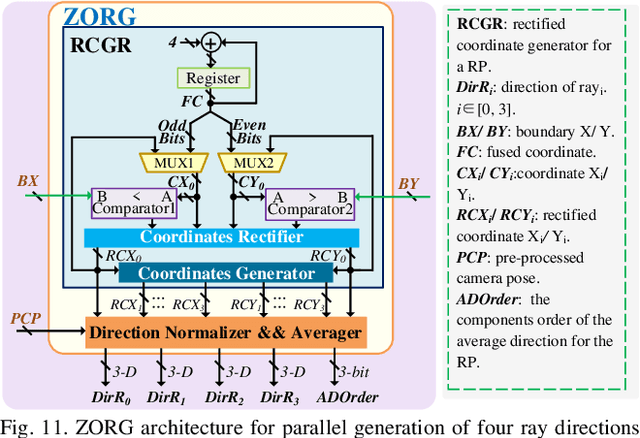
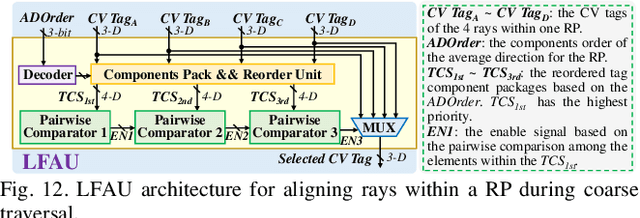
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.
Semformer: Transformer Language Models with Semantic Planning
Sep 17, 2024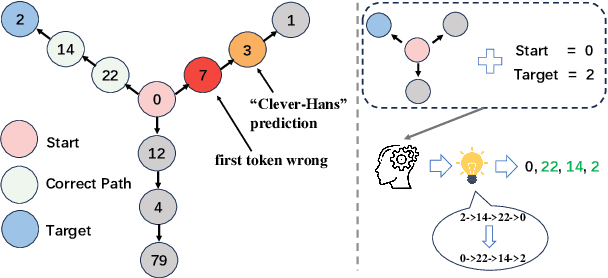
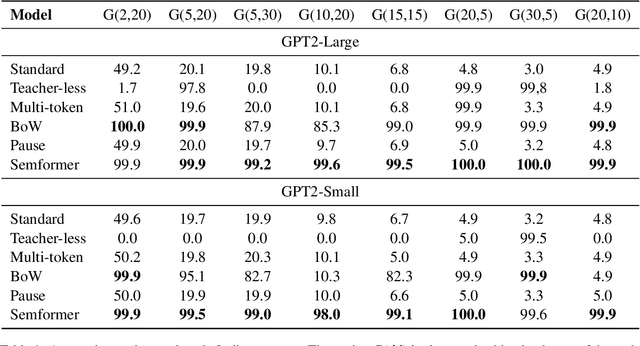
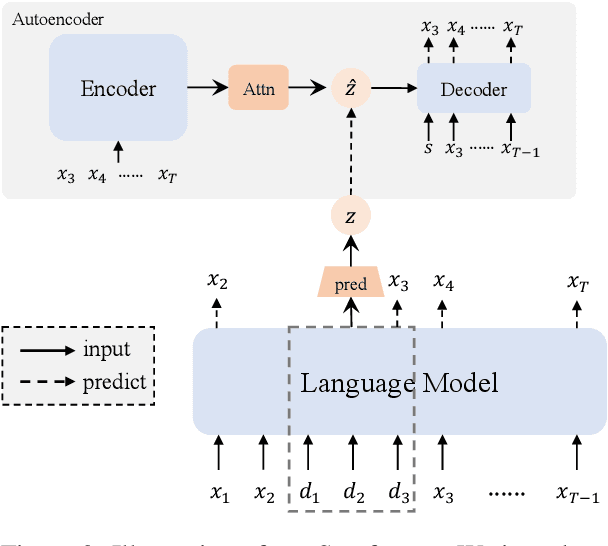
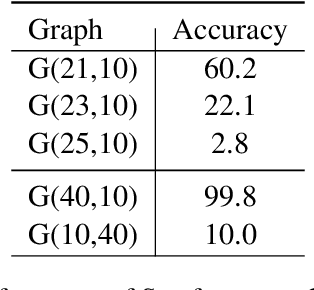
Next-token prediction serves as the dominant component in current neural language models. During the training phase, the model employs teacher forcing, which predicts tokens based on all preceding ground truth tokens. However, this approach has been found to create shortcuts, utilizing the revealed prefix to spuriously fit future tokens, potentially compromising the accuracy of the next-token predictor. In this paper, we introduce Semformer, a novel method of training a Transformer language model that explicitly models the semantic planning of response. Specifically, we incorporate a sequence of planning tokens into the prefix, guiding the planning token representations to predict the latent semantic representations of the response, which are induced by an autoencoder. In a minimal planning task (i.e., graph path-finding), our model exhibits near-perfect performance and effectively mitigates shortcut learning, a feat that standard training methods and baseline models have been unable to accomplish. Furthermore, we pretrain Semformer from scratch with 125M parameters, demonstrating its efficacy through measures of perplexity, in-context learning, and fine-tuning on summarization tasks.
NEPHELE: A Neural Platform for Highly Realistic Cloud Radiance Rendering
Mar 07, 2023We have recently seen tremendous progress in neural rendering (NR) advances, i.e., NeRF, for photo-real free-view synthesis. Yet, as a local technique based on a single computer/GPU, even the best-engineered Instant-NGP or i-NGP cannot reach real-time performance when rendering at a high resolution, and often requires huge local computing resources. In this paper, we resort to cloud rendering and present NEPHELE, a neural platform for highly realistic cloud radiance rendering. In stark contrast with existing NR approaches, our NEPHELE allows for more powerful rendering capabilities by combining multiple remote GPUs and facilitates collaboration by allowing multiple people to view the same NeRF scene simultaneously. We introduce i-NOLF to employ opacity light fields for ultra-fast neural radiance rendering in a one-query-per-ray manner. We further resemble the Lumigraph with geometry proxies for fast ray querying and subsequently employ a small MLP to model the local opacity lumishperes for high-quality rendering. We also adopt Perfect Spatial Hashing in i-NOLF to enhance cache coherence. As a result, our i-NOLF achieves an order of magnitude performance gain in terms of efficiency than i-NGP, especially for the multi-user multi-viewpoint setting under cloud rendering scenarios. We further tailor a task scheduler accompanied by our i-NOLF representation and demonstrate the advance of our methodological design through a comprehensive cloud platform, consisting of a series of cooperated modules, i.e., render farms, task assigner, frame composer, and detailed streaming strategies. Using such a cloud platform compatible with neural rendering, we further showcase the capabilities of our cloud radiance rendering through a series of applications, ranging from cloud VR/AR rendering.