 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTR-Suite: A Framework for Evaluating and Synthesizing Conversational Retrieval Benchmarks
May 20, 2026Accurate evaluation of conversational retrieval is pivotal for advancing Retrieval-Augmented Generation (RAG) systems. However, existing conversational retrieval benchmarks suffer from costly, sparse human annotation or rigid, unnatural automated heuristics. To address these challenges, we introduce MTR-Suite, a unified framework for auditing, synthesizing, and benchmarking retrieval. It features: (1) MTR-Eval, an LLM-based auditor quantifying alignment gaps in previous benchmarks; (2) MTR-Pipeline, a multi-agent system using greedy traversal clustering to generate high-fidelity dialogues at 1/400th human cost; and (3) MTR-Bench, a rigorous general-domain benchmark. MTR-Bench mimics production-style challenges (hard topic switching, verbosity), offering superior discriminative power. We make our code and data publicly available to facilitate future research at https://github.com/rangehow/mtr-suite.
Causal Autoregressive Diffusion Language Model
Jan 29, 2026In this work, we propose Causal Autoregressive Diffusion (CARD), a novel framework that unifies the training efficiency of ARMs with the high-throughput inference of diffusion models. CARD reformulates the diffusion process within a strictly causal attention mask, enabling dense, per-token supervision in a single forward pass. To address the optimization instability of causal diffusion, we introduce a soft-tailed masking schema to preserve local context and a context-aware reweighting mechanism derived from signal-to-noise principles. This design enables dynamic parallel decoding, where the model leverages KV-caching to adaptively generate variable-length token sequences based on confidence. Empirically, CARD outperforms existing discrete diffusion baselines while reducing training latency by 3 $\times$ compared to block diffusion methods. Our results demonstrate that CARD achieves ARM-level data efficiency while unlocking the latency benefits of parallel generation, establishing a robust paradigm for next-generation efficient LLMs.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
BAPO: Boundary-Aware Policy Optimization for Reliable Agentic Search
Jan 16, 2026RL-based agentic search enables LLMs to solve complex questions via dynamic planning and external search. While this approach significantly enhances accuracy with agent policies optimized via large-scale reinforcement learning, we identify a critical gap in reliability: these agents fail to recognize their reasoning boundaries and rarely admit ``I DON'T KNOW'' (IDK) even when evidence is insufficient or reasoning reaches its limit. The lack of reliability often leads to plausible but unreliable answers, introducing significant risks in many real-world scenarios. To this end, we propose Boundary-Aware Policy Optimization (BAPO), a novel RL framework designed to cultivate reliable boundary awareness without compromising accuracy. BAPO introduces two key components: (i) a group-based boundary-aware reward that encourages an IDK response only when the reasoning reaches its limit, and (ii) an adaptive reward modulator that strategically suspends this reward during early exploration, preventing the model from exploiting IDK as a shortcut. Extensive experiments on four benchmarks demonstrate that BAPO substantially enhances the overall reliability of agentic search.
Lost in Literalism: How Supervised Training Shapes Translationese in LLMs
Mar 06, 2025



Large language models (LLMs) have achieved remarkable success in machine translation, demonstrating impressive performance across diverse languages. However, translationese, characterized by overly literal and unnatural translations, remains a persistent challenge in LLM-based translation systems. Despite their pre-training on vast corpora of natural utterances, LLMs exhibit translationese errors and generate unexpected unnatural translations, stemming from biases introduced during supervised fine-tuning (SFT). In this work, we systematically evaluate the prevalence of translationese in LLM-generated translations and investigate its roots during supervised training. We introduce methods to mitigate these biases, including polishing golden references and filtering unnatural training instances. Empirical evaluations demonstrate that these approaches significantly reduce translationese while improving translation naturalness, validated by human evaluations and automatic metrics. Our findings highlight the need for training-aware adjustments to optimize LLM translation outputs, paving the way for more fluent and target-language-consistent translations. We release the data and code at https://github.com/yafuly/LLM_Translationese.
Semformer: Transformer Language Models with Semantic Planning
Sep 17, 2024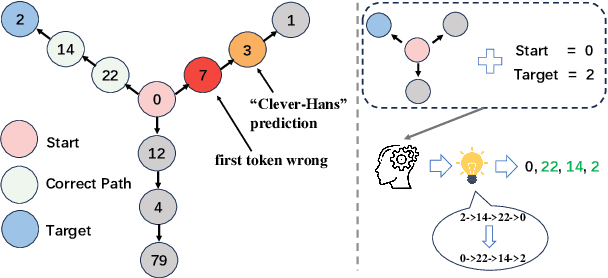
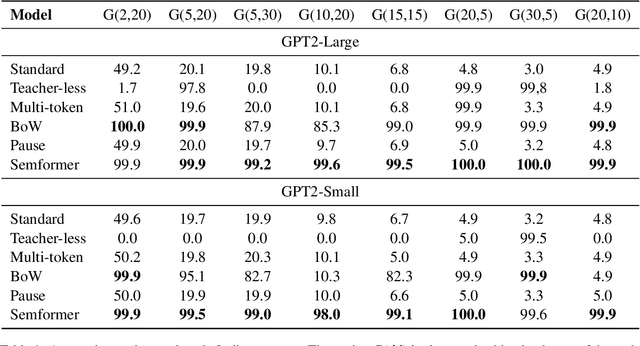
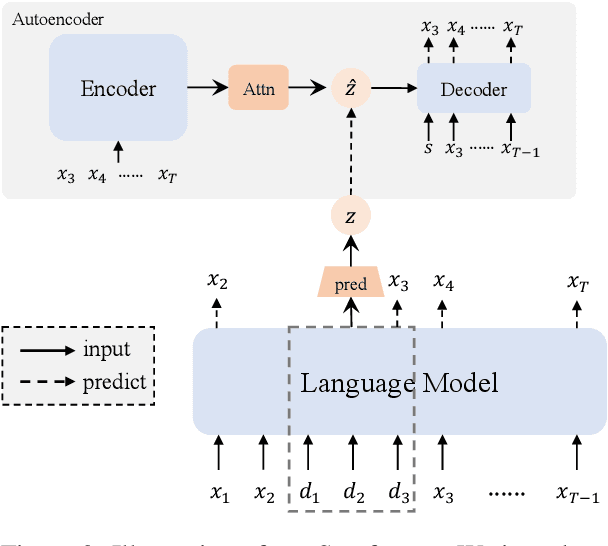
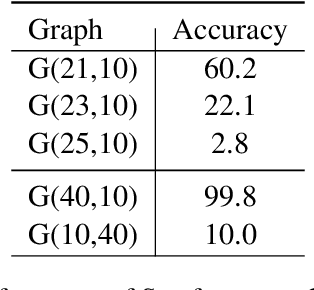
Next-token prediction serves as the dominant component in current neural language models. During the training phase, the model employs teacher forcing, which predicts tokens based on all preceding ground truth tokens. However, this approach has been found to create shortcuts, utilizing the revealed prefix to spuriously fit future tokens, potentially compromising the accuracy of the next-token predictor. In this paper, we introduce Semformer, a novel method of training a Transformer language model that explicitly models the semantic planning of response. Specifically, we incorporate a sequence of planning tokens into the prefix, guiding the planning token representations to predict the latent semantic representations of the response, which are induced by an autoencoder. In a minimal planning task (i.e., graph path-finding), our model exhibits near-perfect performance and effectively mitigates shortcut learning, a feat that standard training methods and baseline models have been unable to accomplish. Furthermore, we pretrain Semformer from scratch with 125M parameters, demonstrating its efficacy through measures of perplexity, in-context learning, and fine-tuning on summarization tasks.
LexMatcher: Dictionary-centric Data Collection for LLM-based Machine Translation
Jun 03, 2024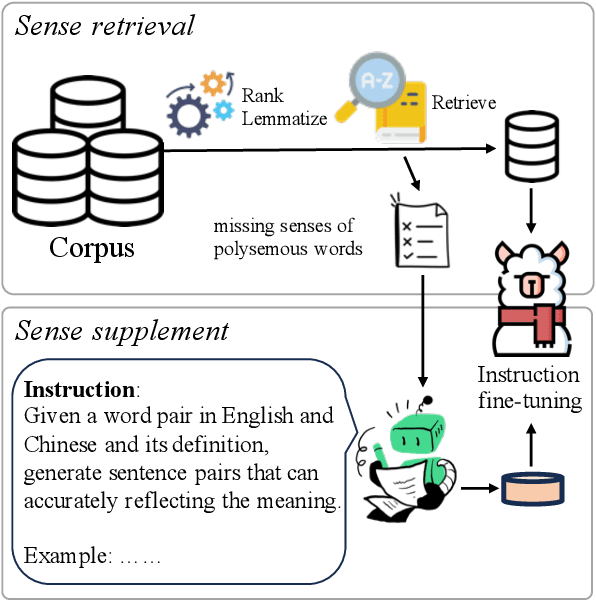
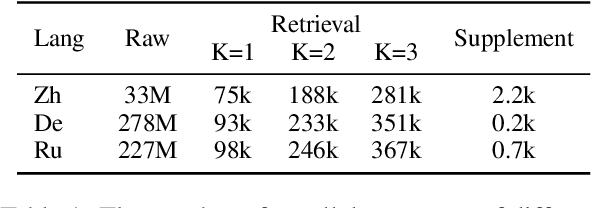
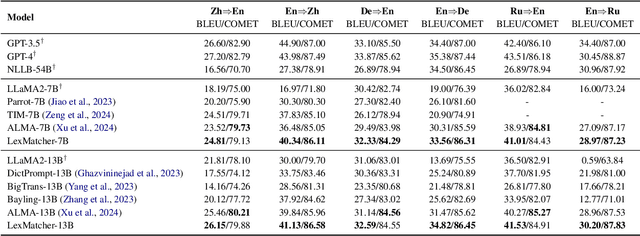
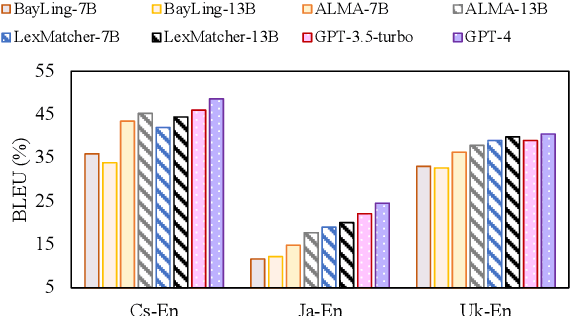
The fine-tuning of open-source large language models (LLMs) for machine translation has recently received considerable attention, marking a shift towards data-centric research from traditional neural machine translation. However, the area of data collection for instruction fine-tuning in machine translation remains relatively underexplored. In this paper, we present LexMatcher, a simple yet effective method for data collection that leverages bilingual dictionaries to generate a dataset, the design of which is driven by the coverage of senses found in these dictionaries. The dataset comprises a subset retrieved from an existing corpus and a smaller synthesized subset which supplements the infrequent senses of polysemous words. Utilizing LLaMA2 as our base model, our approach outperforms the established baselines on the WMT2022 test sets and also exhibits significant performance improvements in tasks related to word sense disambiguation and specialized terminology translation. These results underscore the effectiveness of LexMatcher in enhancing LLM-based machine translation.
What Have We Achieved on Non-autoregressive Translation?
May 21, 2024
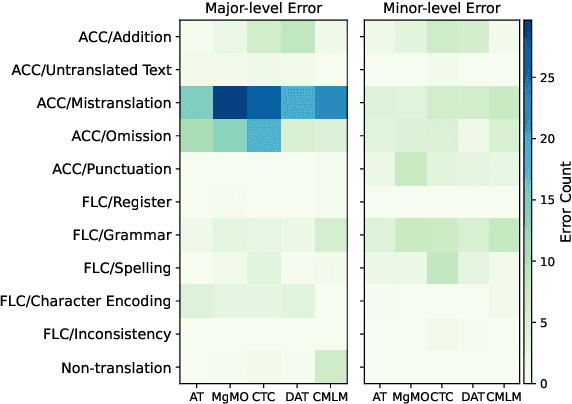


Recent advances have made non-autoregressive (NAT) translation comparable to autoregressive methods (AT). However, their evaluation using BLEU has been shown to weakly correlate with human annotations. Limited research compares non-autoregressive translation and autoregressive translation comprehensively, leaving uncertainty about the true proximity of NAT to AT. To address this gap, we systematically evaluate four representative NAT methods across various dimensions, including human evaluation. Our empirical results demonstrate that despite narrowing the performance gap, state-of-the-art NAT still underperforms AT under more reliable evaluation metrics. Furthermore, we discover that explicitly modeling dependencies is crucial for generating natural language and generalizing to out-of-distribution sequences.
AI-driven platform for systematic nomenclature and intelligent knowledge acquisition of natural medicinal materials
Dec 27, 2023



Natural Medicinal Materials (NMMs) have a long history of global clinical applications, accompanied by extensive informational records. Despite their significant impact on healthcare, the field faces a major challenge: the non-standardization of NMM knowledge, stemming from historical complexities and causing limitations in broader applications. To address this, we introduce a Systematic Nomenclature for NMMs, underpinned by ShennongAlpha, an AI-driven platform designed for intelligent knowledge acquisition. This nomenclature system enables precise identification and differentiation of NMMs. ShennongAlpha, cataloging over ten thousand NMMs with standardized bilingual information, enhances knowledge management and application capabilities, thereby overcoming traditional barriers. Furthermore, it pioneers AI-empowered conversational knowledge acquisition and standardized machine translation. These synergistic innovations mark the first major advance in integrating domain-specific NMM knowledge with AI, propelling research and applications across both NMM and AI fields while establishing a groundbreaking precedent in this crucial area.
Improving Machine Translation with Large Language Models: A Preliminary Study with Cooperative Decoding
Nov 06, 2023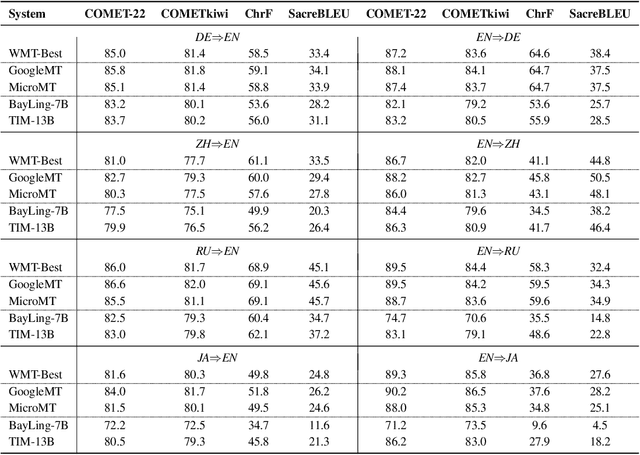
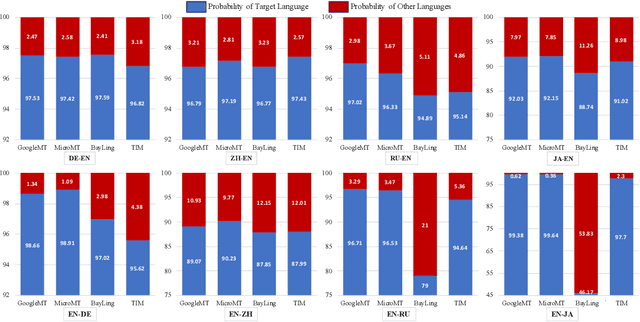
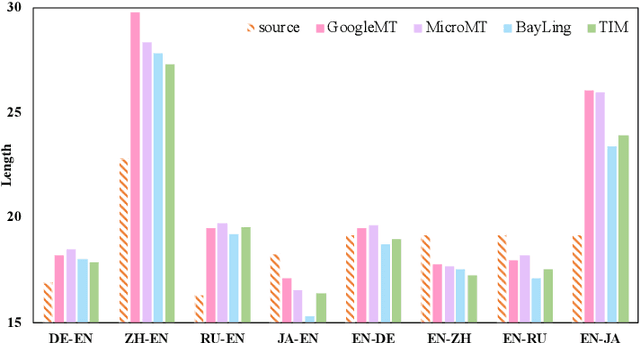

Contemporary translation engines built upon the encoder-decoder framework have reached a high level of development, while the emergence of Large Language Models (LLMs) has disrupted their position by offering the potential for achieving superior translation quality. Therefore, it is crucial to understand in which scenarios LLMs outperform traditional NMT systems and how to leverage their strengths. In this paper, we first conduct a comprehensive analysis to assess the strengths and limitations of various commercial NMT systems and MT-oriented LLMs. Our findings indicate that neither NMT nor MT-oriented LLMs alone can effectively address all the translation issues, but MT-oriented LLMs can serve as a promising complement to the NMT systems. Building upon these insights, we explore hybrid methods and propose Cooperative Decoding (CoDec), which treats NMT systems as a pretranslation model and MT-oriented LLMs as a supplemental solution to handle complex scenarios beyond the capability of NMT alone. The results on the WMT22 test sets and a newly collected test set WebCrawl demonstrate the effectiveness and efficiency of CoDec, highlighting its potential as a robust solution for combining NMT systems with MT-oriented LLMs in machine translation.