 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improvement of Large Language Models: A Technical Overview and Future Outlook
Mar 26, 2026As large language models (LLMs) continue to advance, improving them solely through human supervision is becoming increasingly costly and limited in scalability. As models approach human-level capabilities in certain domains, human feedback may no longer provide sufficiently informative signals for further improvement. At the same time, the growing ability of models to make autonomous decisions and execute complex actions naturally enables abstractions in which components of the model development process can be progressively automated. Together, these challenges and opportunities have driven increasing interest in self-improvement, where models autonomously generate data, evaluate outputs, and iteratively refine their own capabilities. In this paper, we present a system-level perspective on self-improving language models and introduce a unified framework that organizes existing techniques. We conceptualize the self-improvement system as a closed-loop lifecycle, consisting of four tightly coupled processes: data acquisition, data selection, model optimization, and inference refinement, along with an autonomous evaluation layer. Within this framework, the model itself plays a central role in driving each stage: collecting or generating data, selecting informative signals, updating its parameters, and refining outputs, while the autonomous evaluation layer continuously monitors progress and guides the improvement cycle across stages. Following this lifecycle perspective, we systematically review and analyze representative methods for each component from a technical standpoint. We further discuss current limitations and outline our vision for future research toward fully self-improving LLMs.
InstructTime++: Time Series Classification with Multimodal Language Modeling via Implicit Feature Enhancement
Jan 21, 2026Most existing time series classification methods adopt a discriminative paradigm that maps input sequences directly to one-hot encoded class labels. While effective, this paradigm struggles to incorporate contextual features and fails to capture semantic relationships among classes. To address these limitations, we propose InstructTime, a novel framework that reformulates time series classification as a multimodal generative task. Specifically, continuous numerical sequences, contextual textual features, and task instructions are treated as multimodal inputs, while class labels are generated as textual outputs by tuned language models. To bridge the modality gap, InstructTime introduces a time series discretization module that converts continuous sequences into discrete temporal tokens, together with an alignment projection layer and a generative self-supervised pre-training strategy to enhance cross-modal representation alignment. Building upon this framework, we further propose InstructTime++, which extends InstructTime by incorporating implicit feature modeling to compensate for the limited inductive bias of language models. InstructTime++ leverages specialized toolkits to mine informative implicit patterns from raw time series and contextual inputs, including statistical feature extraction and vision-language-based image captioning, and translates them into textual descriptions for seamless integration. Extensive experiments on multiple benchmark datasets demonstrate the superior performance of InstructTime++.
STaR: Towards Cognitive Table Reasoning via Slow-Thinking Large Language Models
Nov 14, 2025Table reasoning with the large language models (LLMs) is a fundamental path toward building intelligent systems that can understand and analyze over structured data. While recent progress has shown promising results, they still suffer from two key limitations: (i) the reasoning processes lack the depth and iterative refinement characteristic of human cognition; and (ii) the reasoning processes exhibit instability, which compromises their reliability in downstream applications. In this work, we present STaR (slow-thinking for table reasoning), a new framework achieving cognitive table reasoning, in which LLMs are equipped with slow-thinking capabilities by explicitly modeling step-by-step thinking and uncertainty-aware inference. During training, STaR employs two-stage difficulty-aware reinforcement learning (DRL), progressively learning from simple to complex queries under a composite reward. During inference, STaR performs trajectory-level uncertainty quantification by integrating token-level confidence and answer consistency, enabling selection of more credible reasoning paths. Extensive experiments on benchmarks demonstrate that STaR achieves superior performance and enhanced reasoning stability. Moreover, strong generalization over out-of-domain datasets further demonstrates STaR's potential as a reliable and cognitively inspired solution for table reasoning with LLMs.
LNE-Blocking: An Efficient Framework for Contamination Mitigation Evaluation on Large Language Models
Sep 18, 2025The problem of data contamination is now almost inevitable during the development of large language models (LLMs), with the training data commonly integrating those evaluation benchmarks even unintentionally. This problem subsequently makes it hard to benchmark LLMs fairly. Instead of constructing contamination-free datasets (quite hard), we propose a novel framework, \textbf{LNE-Blocking}, to restore model performance prior to contamination on potentially leaked datasets. Our framework consists of two components: contamination detection and disruption operation. For the prompt, the framework first uses the contamination detection method, \textbf{LNE}, to assess the extent of contamination in the model. Based on this, it adjusts the intensity of the disruption operation, \textbf{Blocking}, to elicit non-memorized responses from the model. Our framework is the first to efficiently restore the model's greedy decoding performance. This comes with a strong performance on multiple datasets with potential leakage risks, and it consistently achieves stable recovery results across different models and varying levels of data contamination. We release the code at https://github.com/RuijieH/LNE-Blocking to facilitate research.
Lost in Literalism: How Supervised Training Shapes Translationese in LLMs
Mar 06, 2025



Large language models (LLMs) have achieved remarkable success in machine translation, demonstrating impressive performance across diverse languages. However, translationese, characterized by overly literal and unnatural translations, remains a persistent challenge in LLM-based translation systems. Despite their pre-training on vast corpora of natural utterances, LLMs exhibit translationese errors and generate unexpected unnatural translations, stemming from biases introduced during supervised fine-tuning (SFT). In this work, we systematically evaluate the prevalence of translationese in LLM-generated translations and investigate its roots during supervised training. We introduce methods to mitigate these biases, including polishing golden references and filtering unnatural training instances. Empirical evaluations demonstrate that these approaches significantly reduce translationese while improving translation naturalness, validated by human evaluations and automatic metrics. Our findings highlight the need for training-aware adjustments to optimize LLM translation outputs, paving the way for more fluent and target-language-consistent translations. We release the data and code at https://github.com/yafuly/LLM_Translationese.
Leveraging Entailment Judgements in Cross-Lingual Summarisation
Aug 01, 2024



Synthetically created Cross-Lingual Summarisation (CLS) datasets are prone to include document-summary pairs where the reference summary is unfaithful to the corresponding document as it contains content not supported by the document (i.e., hallucinated content). This low data quality misleads model learning and obscures evaluation results. Automatic ways to assess hallucinations and improve training have been proposed for monolingual summarisation, predominantly in English. For CLS, we propose to use off-the-shelf cross-lingual Natural Language Inference (X-NLI) to evaluate faithfulness of reference and model generated summaries. Then, we study training approaches that are aware of faithfulness issues in the training data and propose an approach that uses unlikelihood loss to teach a model about unfaithful summary sequences. Our results show that it is possible to train CLS models that yield more faithful summaries while maintaining comparable or better informativess.
What Have We Achieved on Non-autoregressive Translation?
May 21, 2024
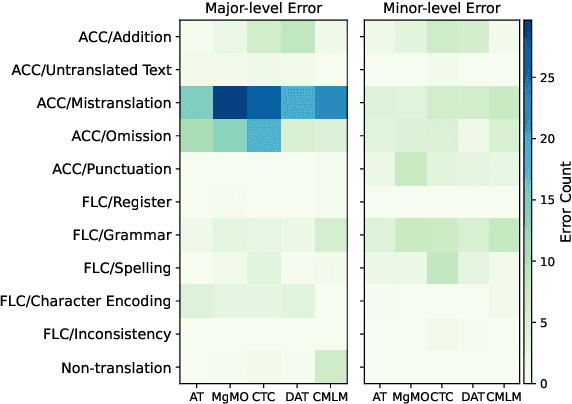


Recent advances have made non-autoregressive (NAT) translation comparable to autoregressive methods (AT). However, their evaluation using BLEU has been shown to weakly correlate with human annotations. Limited research compares non-autoregressive translation and autoregressive translation comprehensively, leaving uncertainty about the true proximity of NAT to AT. To address this gap, we systematically evaluate four representative NAT methods across various dimensions, including human evaluation. Our empirical results demonstrate that despite narrowing the performance gap, state-of-the-art NAT still underperforms AT under more reliable evaluation metrics. Furthermore, we discover that explicitly modeling dependencies is crucial for generating natural language and generalizing to out-of-distribution sequences.
Fine-Grained Natural Language Inference Based Faithfulness Evaluation for Diverse Summarisation Tasks
Feb 27, 2024We study existing approaches to leverage off-the-shelf Natural Language Inference (NLI) models for the evaluation of summary faithfulness and argue that these are sub-optimal due to the granularity level considered for premises and hypotheses. That is, the smaller content unit considered as hypothesis is a sentence and premises are made up of a fixed number of document sentences. We propose a novel approach, namely InFusE, that uses a variable premise size and simplifies summary sentences into shorter hypotheses. Departing from previous studies which focus on single short document summarisation, we analyse NLI based faithfulness evaluation for diverse summarisation tasks. We introduce DiverSumm, a new benchmark comprising long form summarisation (long documents and summaries) and diverse summarisation tasks (e.g., meeting and multi-document summarisation). In experiments, InFusE obtains superior performance across the different summarisation tasks. Our code and data are available at https://github.com/HJZnlp/infuse.
DiffYOLO: Object Detection for Anti-Noise via YOLO and Diffusion Models
Jan 03, 2024Object detection models represented by YOLO series have been widely used and have achieved great results on the high quality datasets, but not all the working conditions are ideal. To settle down the problem of locating targets on low quality datasets, the existing methods either train a new object detection network, or need a large collection of low-quality datasets to train. However, we propose a framework in this paper and apply it on the YOLO models called DiffYOLO. Specifically, we extract feature maps from the denoising diffusion probabilistic models to enhance the well-trained models, which allows us fine-tune YOLO on high-quality datasets and test on low-quality datasets. The results proved this framework can not only prove the performance on noisy datasets, but also prove the detection results on high-quality test datasets. We will supplement more experiments later (with various datasets and network architectures).
Revisiting Cross-Lingual Summarization: A Corpus-based Study and A New Benchmark with Improved Annotation
Jul 08, 2023
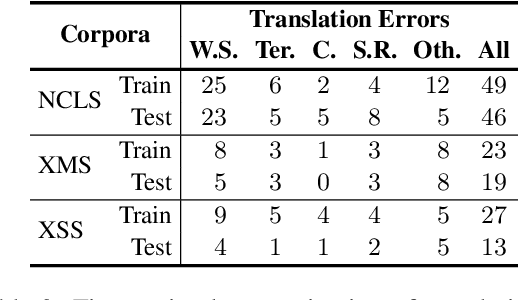
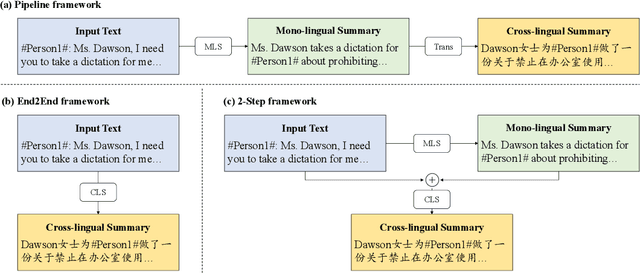
Most existing cross-lingual summarization (CLS) work constructs CLS corpora by simply and directly translating pre-annotated summaries from one language to another, which can contain errors from both summarization and translation processes. To address this issue, we propose ConvSumX, a cross-lingual conversation summarization benchmark, through a new annotation schema that explicitly considers source input context. ConvSumX consists of 2 sub-tasks under different real-world scenarios, with each covering 3 language directions. We conduct thorough analysis on ConvSumX and 3 widely-used manually annotated CLS corpora and empirically find that ConvSumX is more faithful towards input text. Additionally, based on the same intuition, we propose a 2-Step method, which takes both conversation and summary as input to simulate human annotation process. Experimental results show that 2-Step method surpasses strong baselines on ConvSumX under both automatic and human evaluation. Analysis shows that both source input text and summary are crucial for modeling cross-lingual summaries.