 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing and Exploring Mild Cognitive Impairment Detection with W2V-BERT-2.0
Jan 27, 2025



This study explores a multi-lingual audio self-supervised learning model for detecting mild cognitive impairment (MCI) using the TAUKADIAL cross-lingual dataset. While speech transcription-based detection with BERT models is effective, limitations exist due to a lack of transcriptions and temporal information. To address these issues, the study utilizes features directly from speech utterances with W2V-BERT-2.0. We propose a visualization method to detect essential layers of the model for MCI classification and design a specific inference logic considering the characteristics of MCI. The experiment shows competitive results, and the proposed inference logic significantly contributes to the improvements from the baseline. We also conduct detailed analysis which reveals the challenges related to speaker bias in the features and the sensitivity of MCI classification accuracy to the data split, providing valuable insights for future research.
Summarization-based Data Augmentation for Document Classification
Dec 01, 2023



Despite the prevalence of pretrained language models in natural language understanding tasks, understanding lengthy text such as document is still challenging due to the data sparseness problem. Inspired by that humans develop their ability of understanding lengthy text from reading shorter text, we propose a simple yet effective summarization-based data augmentation, SUMMaug, for document classification. We first obtain easy-to-learn examples for the target document classification task by summarizing the input of the original training examples, while optionally merging the original labels to conform to the summarized input. We then use the generated pseudo examples to perform curriculum learning. Experimental results on two datasets confirmed the advantage of our method compared to existing baseline methods in terms of robustness and accuracy. We release our code and data at https://github.com/etsurin/summaug.
Revisiting Cross-Lingual Summarization: A Corpus-based Study and A New Benchmark with Improved Annotation
Jul 08, 2023
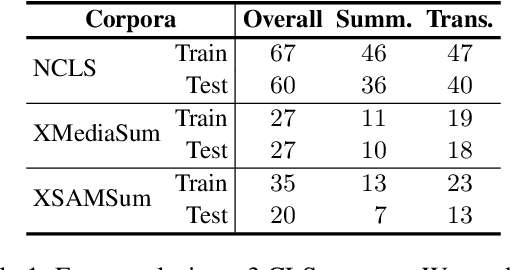
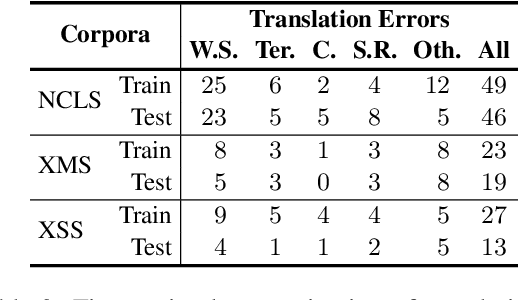
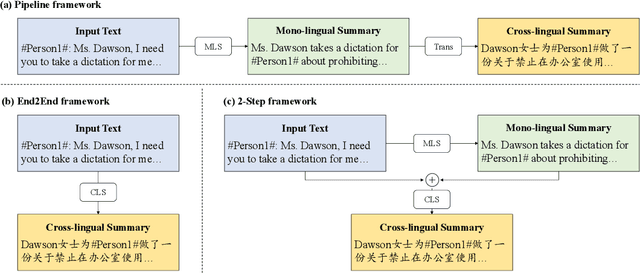
Most existing cross-lingual summarization (CLS) work constructs CLS corpora by simply and directly translating pre-annotated summaries from one language to another, which can contain errors from both summarization and translation processes. To address this issue, we propose ConvSumX, a cross-lingual conversation summarization benchmark, through a new annotation schema that explicitly considers source input context. ConvSumX consists of 2 sub-tasks under different real-world scenarios, with each covering 3 language directions. We conduct thorough analysis on ConvSumX and 3 widely-used manually annotated CLS corpora and empirically find that ConvSumX is more faithful towards input text. Additionally, based on the same intuition, we propose a 2-Step method, which takes both conversation and summary as input to simulate human annotation process. Experimental results show that 2-Step method surpasses strong baselines on ConvSumX under both automatic and human evaluation. Analysis shows that both source input text and summary are crucial for modeling cross-lingual summaries.
Are All Steps Equally Important? Benchmarking Essentiality Detection of Events
Oct 12, 2022



Natural language often describes events in different granularities, such that more coarse-grained (goal) events can often be decomposed into fine-grained sequences of (step) events. A critical but overlooked challenge in understanding an event process lies in the fact that the step events are not equally important to the central goal. In this paper, we seek to fill this gap by studying how well current models can understand the essentiality of different step events towards a goal event. As discussed by cognitive studies, such an ability enables the machine to mimic human's commonsense reasoning about preconditions and necessary efforts of daily-life tasks. Our work contributes with a high-quality corpus of (goal, step) pairs from a community guideline website WikiHow, where the steps are manually annotated with their essentiality w.r.t. the goal. The high IAA indicates that humans have a consistent understanding of the events. Despite evaluating various statistical and massive pre-trained NLU models, we observe that existing SOTA models all perform drastically behind humans, indicating the need for future investigation of this crucial yet challenging task.