 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuron Empirical Gradient: Connecting Neurons' Linear Controllability and Representational Capacity
Dec 24, 2024Although neurons in the feed-forward layers of pre-trained language models (PLMs) can store factual knowledge, most prior analyses remain qualitative, leaving the quantitative relationship among knowledge representation, neuron activations, and model output poorly understood. In this study, by performing neuron-wise interventions using factual probing datasets, we first reveal the linear relationship between neuron activations and output token probabilities. We refer to the gradient of this linear relationship as ``neuron empirical gradients.'' and propose NeurGrad, an efficient method for their calculation to facilitate quantitative neuron analysis. We next investigate whether neuron empirical gradients in PLMs encode general task knowledge by probing skill neurons. To this end, we introduce MCEval8k, a multi-choice knowledge evaluation benchmark spanning six genres and 22 tasks. Our experiments confirm that neuron empirical gradients effectively capture knowledge, while skill neurons exhibit efficiency, generality, inclusivity, and interdependency. These findings link knowledge to PLM outputs via neuron empirical gradients, shedding light on how PLMs store knowledge. The code and dataset are released.
What Matters in Learning Facts in Language Models? Multifaceted Knowledge Probing with Diverse Multi-Prompt Datasets
Jun 18, 2024Large language models (LLMs) face issues in handling factual knowledge, making it vital to evaluate their true ability to understand facts. In this study, we introduce knowledge probing frameworks, BELIEF(-ICL), to evaluate the knowledge understanding ability of not only encoder-based PLMs but also decoder-based PLMs from diverse perspectives. BELIEFs utilize a multi-prompt dataset to evaluate PLM's accuracy, consistency, and reliability in factual knowledge understanding. To provide a more reliable evaluation with BELIEFs, we semi-automatically create MyriadLAMA, which has more diverse prompts than existing datasets. We validate the effectiveness of BELIEFs in correctly and comprehensively evaluating PLM's factual understanding ability through extensive evaluations. We further investigate key factors in learning facts in LLMs, and reveal the limitation of the prompt-based knowledge probing. The dataset is anonymously publicized.
Tracing the Roots of Facts in Multilingual Language Models: Independent, Shared, and Transferred Knowledge
Mar 08, 2024Acquiring factual knowledge for language models (LMs) in low-resource languages poses a serious challenge, thus resorting to cross-lingual transfer in multilingual LMs (ML-LMs). In this study, we ask how ML-LMs acquire and represent factual knowledge. Using the multilingual factual knowledge probing dataset, mLAMA, we first conducted a neuron investigation of ML-LMs (specifically, multilingual BERT). We then traced the roots of facts back to the knowledge source (Wikipedia) to identify the ways in which ML-LMs acquire specific facts. We finally identified three patterns of acquiring and representing facts in ML-LMs: language-independent, cross-lingual shared and transferred, and devised methods for differentiating them. Our findings highlight the challenge of maintaining consistent factual knowledge across languages, underscoring the need for better fact representation learning in ML-LMs.
Rethinking Response Evaluation from Interlocutor's Eye for Open-Domain Dialogue Systems
Jan 04, 2024Open-domain dialogue systems have started to engage in continuous conversations with humans. Those dialogue systems are required to be adjusted to the human interlocutor and evaluated in terms of their perspective. However, it is questionable whether the current automatic evaluation methods can approximate the interlocutor's judgments. In this study, we analyzed and examined what features are needed in an automatic response evaluator from the interlocutor's perspective. The first experiment on the Hazumi dataset revealed that interlocutor awareness plays a critical role in making automatic response evaluation correlate with the interlocutor's judgments. The second experiment using massive conversations on X (formerly Twitter) confirmed that dialogue continuity prediction can train an interlocutor-aware response evaluator without human feedback while revealing the difficulty in evaluating generated responses compared to human responses.
Summarization-based Data Augmentation for Document Classification
Dec 01, 2023



Despite the prevalence of pretrained language models in natural language understanding tasks, understanding lengthy text such as document is still challenging due to the data sparseness problem. Inspired by that humans develop their ability of understanding lengthy text from reading shorter text, we propose a simple yet effective summarization-based data augmentation, SUMMaug, for document classification. We first obtain easy-to-learn examples for the target document classification task by summarizing the input of the original training examples, while optionally merging the original labels to conform to the summarized input. We then use the generated pseudo examples to perform curriculum learning. Experimental results on two datasets confirmed the advantage of our method compared to existing baseline methods in terms of robustness and accuracy. We release our code and data at https://github.com/etsurin/summaug.
PerPLM: Personalized Fine-tuning of Pretrained Language Models via Writer-specific Intermediate Learning and Prompts
Sep 14, 2023The meanings of words and phrases depend not only on where they are used (contexts) but also on who use them (writers). Pretrained language models (PLMs) are powerful tools for capturing context, but they are typically pretrained and fine-tuned for universal use across different writers. This study aims to improve the accuracy of text understanding tasks by personalizing the fine-tuning of PLMs for specific writers. We focus on a general setting where only the plain text from target writers are available for personalization. To avoid the cost of fine-tuning and storing multiple copies of PLMs for different users, we exhaustively explore using writer-specific prompts to personalize a unified PLM. Since the design and evaluation of these prompts is an underdeveloped area, we introduce and compare different types of prompts that are possible in our setting. To maximize the potential of prompt-based personalized fine-tuning, we propose a personalized intermediate learning based on masked language modeling to extract task-independent traits of writers' text. Our experiments, using multiple tasks, datasets, and PLMs, reveal the nature of different prompts and the effectiveness of our intermediate learning approach.
A Unified Generative Approach to Product Attribute-Value Identification
Jun 09, 2023



Product attribute-value identification (PAVI) has been studied to link products on e-commerce sites with their attribute values (e.g., <Material, Cotton>) using product text as clues. Technical demands from real-world e-commerce platforms require PAVI methods to handle unseen values, multi-attribute values, and canonicalized values, which are only partly addressed in existing extraction- and classification-based approaches. Motivated by this, we explore a generative approach to the PAVI task. We finetune a pre-trained generative model, T5, to decode a set of attribute-value pairs as a target sequence from the given product text. Since the attribute value pairs are unordered set elements, how to linearize them will matter; we, thus, explore methods of composing an attribute-value pair and ordering the pairs for the task. Experimental results confirm that our generation-based approach outperforms the existing extraction and classification-based methods on large-scale real-world datasets meant for those methods.
Back to Patterns: Efficient Japanese Morphological Analysis with Feature-Sequence Trie
May 30, 2023Accurate neural models are much less efficient than non-neural models and are useless for processing billions of social media posts or handling user queries in real time with a limited budget. This study revisits the fastest pattern-based NLP methods to make them as accurate as possible, thus yielding a strikingly simple yet surprisingly accurate morphological analyzer for Japanese. The proposed method induces reliable patterns from a morphological dictionary and annotated data. Experimental results on two standard datasets confirm that the method exhibits comparable accuracy to learning-based baselines, while boasting a remarkable throughput of over 1,000,000 sentences per second on a single modern CPU. The source code is available at https://www.tkl.iis.u-tokyo.ac.jp/~ynaga/jagger/
Esports Data-to-commentary Generation on Large-scale Data-to-text Dataset
Dec 21, 2022



Esports, a sports competition using video games, has become one of the most important sporting events in recent years. Although the amount of esports data is increasing than ever, only a small fraction of those data accompanies text commentaries for the audience to retrieve and understand the plays. Therefore, in this study, we introduce a task of generating game commentaries from structured data records to address the problem. We first build a large-scale esports data-to-text dataset using structured data and commentaries from a popular esports game, League of Legends. On this dataset, we devise several data preprocessing methods including linearization and data splitting to augment its quality. We then introduce several baseline encoder-decoder models and propose a hierarchical model to generate game commentaries. Considering the characteristics of esports commentaries, we design evaluation metrics including three aspects of the output: correctness, fluency, and strategic depth. Experimental results on our large-scale esports dataset confirmed the advantage of the hierarchical model, and the results revealed several challenges of this novel task.
Self-Adaptive Named Entity Recognition by Retrieving Unstructured Knowledge
Oct 14, 2022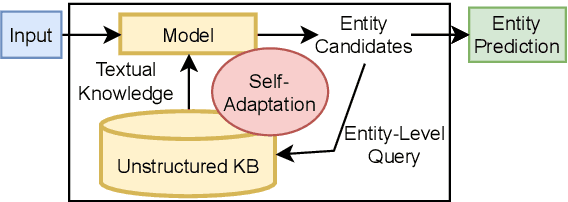
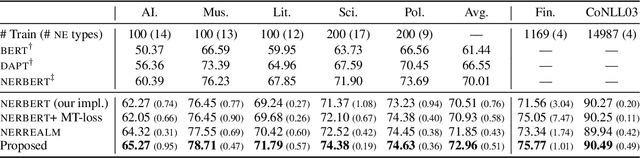
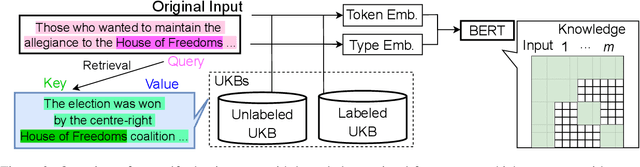
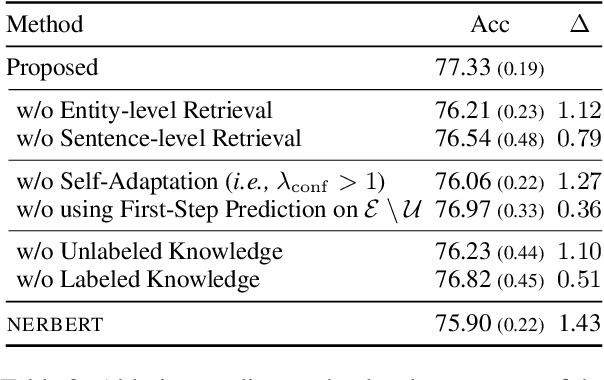
Although named entity recognition (NER) helps us to extract various domain-specific entities from text (e.g., artists in the music domain), it is costly to create a large amount of training data or a structured knowledge base to perform accurate NER in the target domain. Here, we propose self-adaptive NER, where the model retrieves the external knowledge from unstructured text to learn the usage of entities that has not been learned well. To retrieve useful knowledge for NER, we design an effective two-stage model that retrieves unstructured knowledge using uncertain entities as queries. Our model first predicts the entities in the input and then finds the entities of which the prediction is not confident. Then, our model retrieves knowledge by using these uncertain entities as queries and concatenates the retrieved text to the original input to revise the prediction. Experiments on CrossNER datasets demonstrated that our model outperforms the strong NERBERT baseline by 2.45 points on average.