 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRakutenAI-7B: Extending Large Language Models for Japanese
Mar 21, 2024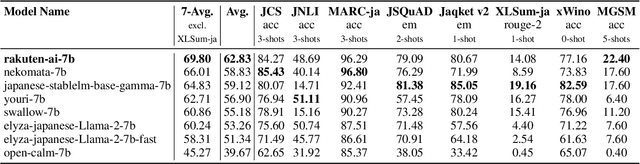
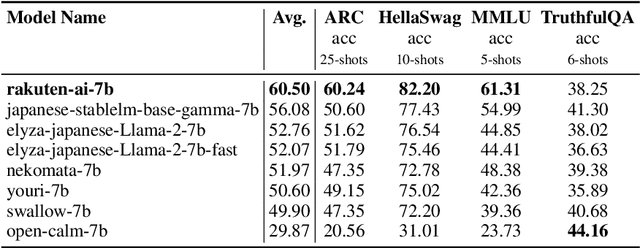
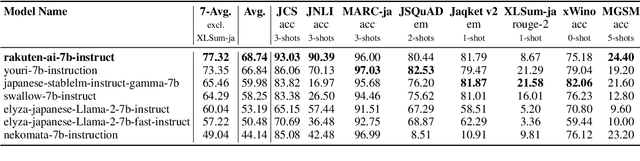
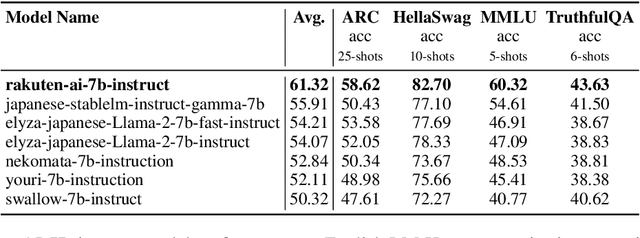
We introduce RakutenAI-7B, a suite of Japanese-oriented large language models that achieve the best performance on the Japanese LM Harness benchmarks among the open 7B models. Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
A Unified Generative Approach to Product Attribute-Value Identification
Jun 09, 2023Product attribute-value identification (PAVI) has been studied to link products on e-commerce sites with their attribute values (e.g., <Material, Cotton>) using product text as clues. Technical demands from real-world e-commerce platforms require PAVI methods to handle unseen values, multi-attribute values, and canonicalized values, which are only partly addressed in existing extraction- and classification-based approaches. Motivated by this, we explore a generative approach to the PAVI task. We finetune a pre-trained generative model, T5, to decode a set of attribute-value pairs as a target sequence from the given product text. Since the attribute value pairs are unordered set elements, how to linearize them will matter; we, thus, explore methods of composing an attribute-value pair and ordering the pairs for the task. Experimental results confirm that our generation-based approach outperforms the existing extraction and classification-based methods on large-scale real-world datasets meant for those methods.
Simple and Effective Knowledge-Driven Query Expansion for QA-Based Product Attribute Extraction
Jun 28, 2022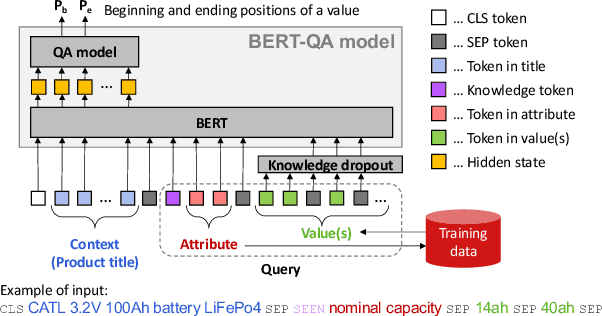
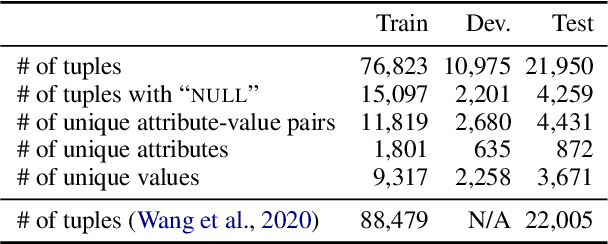
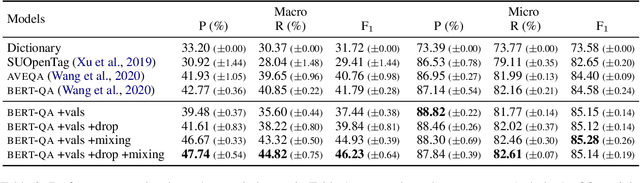
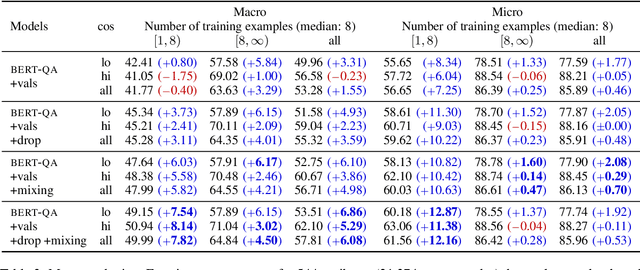
A key challenge in attribute value extraction (AVE) from e-commerce sites is how to handle a large number of attributes for diverse products. Although this challenge is partially addressed by a question answering (QA) approach which finds a value in product data for a given query (attribute), it does not work effectively for rare and ambiguous queries. We thus propose simple knowledge-driven query expansion based on possible answers (values) of a query (attribute) for QA-based AVE. We retrieve values of a query (attribute) from the training data to expand the query. We train a model with two tricks, knowledge dropout and knowledge token mixing, which mimic the imperfection of the value knowledge in testing. Experimental results on our cleaned version of AliExpress dataset show that our method improves the performance of AVE (+6.08 macro F1), especially for rare and ambiguous attributes (+7.82 and +6.86 macro F1, respectively).
* Published at ACL 2022
Chinese Event Extraction Using DeepNeural Network with Word Embedding
Oct 04, 2016

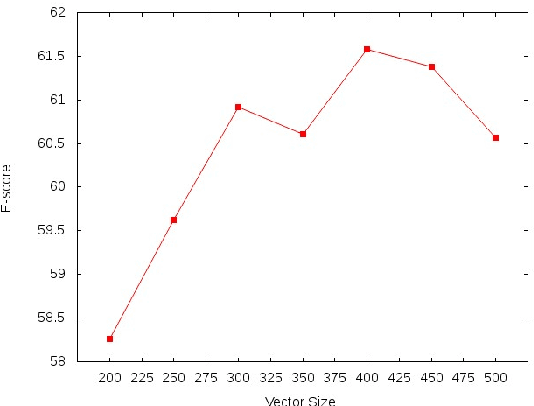
A lot of prior work on event extraction has exploited a variety of features to represent events. Such methods have several drawbacks: 1) the features are often specific for a particular domain and do not generalize well; 2) the features are derived from various linguistic analyses and are error-prone; and 3) some features may be expensive and require domain expert. In this paper, we develop a Chinese event extraction system that uses word embedding vectors to represent language, and deep neural networks to learn the abstract feature representation in order to greatly reduce the effort of feature engineering. In addition, in this framework, we leverage large amount of unlabeled data, which can address the problem of limited labeled corpus for this task. Our experiments show that our proposed method performs better compared to the system using rich language features, and using unlabeled data benefits the word embeddings. This study suggests the potential of DNN and word embedding for the event extraction task.