 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Response Evaluation from Interlocutor's Eye for Open-Domain Dialogue Systems
Jan 04, 2024Open-domain dialogue systems have started to engage in continuous conversations with humans. Those dialogue systems are required to be adjusted to the human interlocutor and evaluated in terms of their perspective. However, it is questionable whether the current automatic evaluation methods can approximate the interlocutor's judgments. In this study, we analyzed and examined what features are needed in an automatic response evaluator from the interlocutor's perspective. The first experiment on the Hazumi dataset revealed that interlocutor awareness plays a critical role in making automatic response evaluation correlate with the interlocutor's judgments. The second experiment using massive conversations on X (formerly Twitter) confirmed that dialogue continuity prediction can train an interlocutor-aware response evaluator without human feedback while revealing the difficulty in evaluating generated responses compared to human responses.
PerPLM: Personalized Fine-tuning of Pretrained Language Models via Writer-specific Intermediate Learning and Prompts
Sep 14, 2023The meanings of words and phrases depend not only on where they are used (contexts) but also on who use them (writers). Pretrained language models (PLMs) are powerful tools for capturing context, but they are typically pretrained and fine-tuned for universal use across different writers. This study aims to improve the accuracy of text understanding tasks by personalizing the fine-tuning of PLMs for specific writers. We focus on a general setting where only the plain text from target writers are available for personalization. To avoid the cost of fine-tuning and storing multiple copies of PLMs for different users, we exhaustively explore using writer-specific prompts to personalize a unified PLM. Since the design and evaluation of these prompts is an underdeveloped area, we introduce and compare different types of prompts that are possible in our setting. To maximize the potential of prompt-based personalized fine-tuning, we propose a personalized intermediate learning based on masked language modeling to extract task-independent traits of writers' text. Our experiments, using multiple tasks, datasets, and PLMs, reveal the nature of different prompts and the effectiveness of our intermediate learning approach.
Early Discovery of Disappearing Entities in Microblogs
Oct 13, 2022
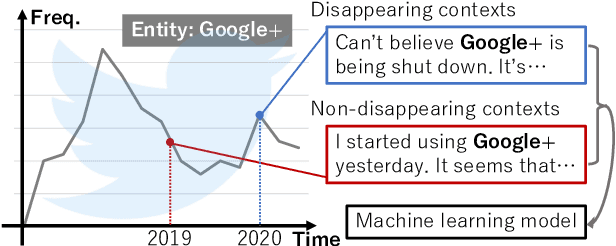
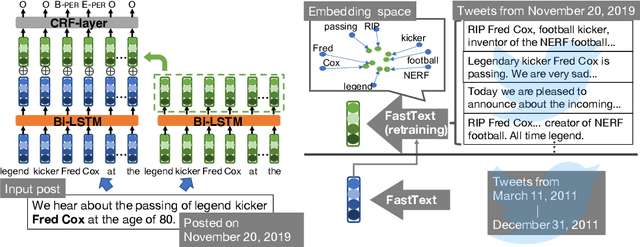
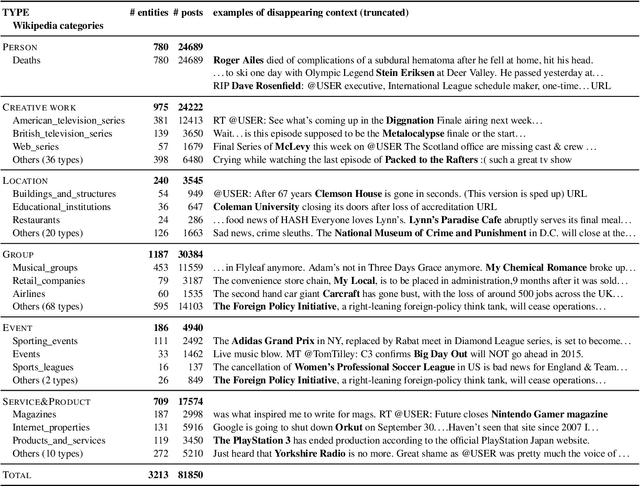
We make decisions by reacting to changes in the real world, in particular, the emergence and disappearance of impermanent entities such as events, restaurants, and services. Because we want to avoid missing out on opportunities or making fruitless actions after they have disappeared, it is important to know when entities disappear as early as possible. We thus tackle the task of detecting disappearing entities from microblogs, whose posts mention various entities, in a timely manner. The major challenge is detecting uncertain contexts of disappearing entities from noisy microblog posts. To collect these disappearing contexts, we design time-sensitive distant supervision, which utilizes entities from the knowledge base and time-series posts, for this task to build large-scale Twitter datasets\footnote{We will release the datasets (tweet IDs) used in the experiments to promote reproducibility.} for English and Japanese. To ensure robust detection in noisy environments, we refine pretrained word embeddings of the detection model on microblog streams of the target day. Experimental results on the Twitter datasets confirmed the effectiveness of the collected labeled data and refined word embeddings; more than 70\% of the detected disappearing entities in Wikipedia are discovered earlier than the update on Wikipedia, and the average lead-time is over one month.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020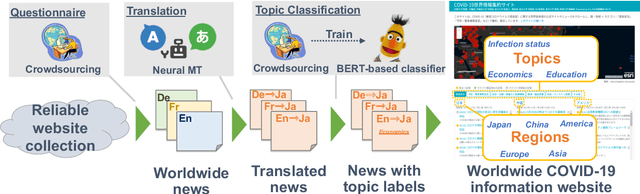

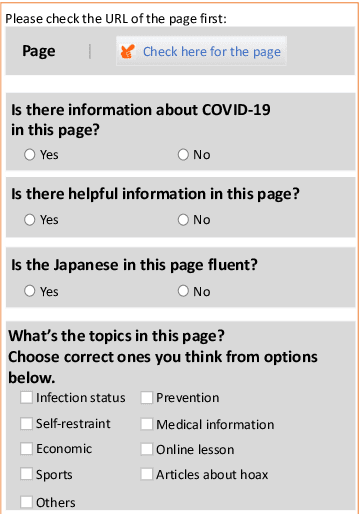
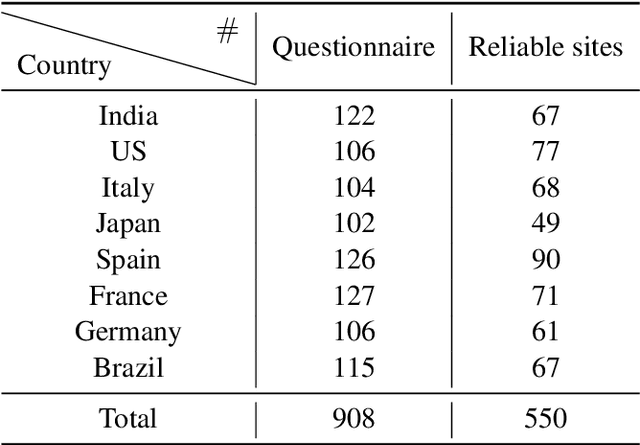
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.
Vocabulary Adaptation for Distant Domain Adaptation in Neural Machine Translation
Apr 30, 2020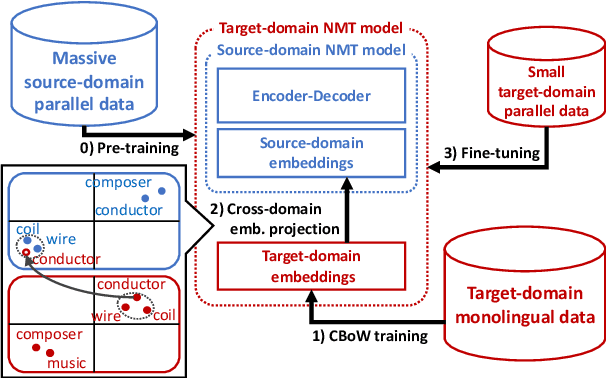
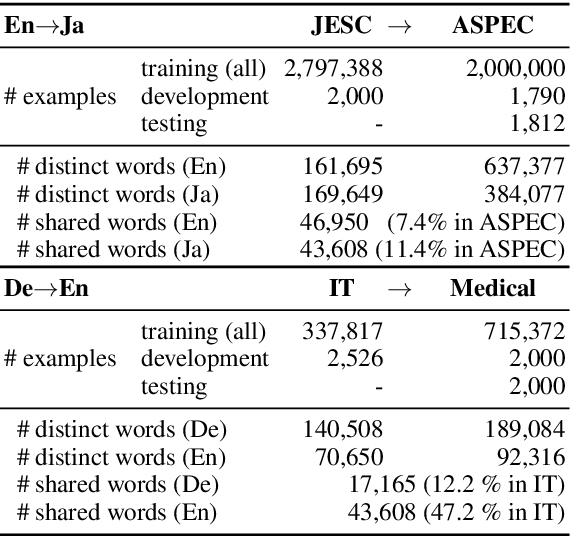
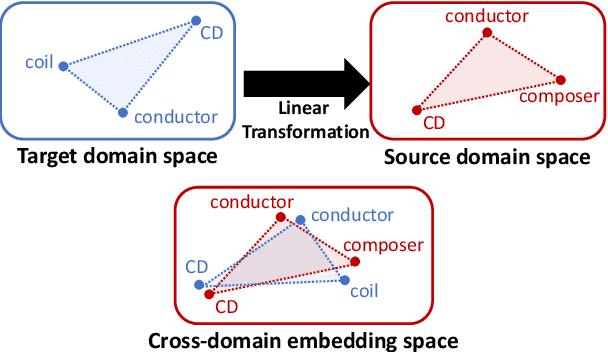

Neural machine translation (NMT) models do not work well in domains different from the training data. The standard approach to this problem is to build a small parallel data in the target domain and perform domain adaptation from a source domain where massive parallel data is available. However, domain adaptation between distant domains (e.g., subtitles and research papers) does not perform effectively because of mismatches in vocabulary; it will encounter many domain-specific unknown words (e.g., `angstrom') and words whose meanings shift across domains (e.g., `conductor'). In this study, aiming to solve these vocabulary mismatches in distant domain adaptation, we propose vocabulary adaptation, a simple method for effective fine-tuning that adapts embedding layers in a given pre-trained NMT model to the target domain. Prior to fine-tuning, our method replaces word embeddings in embedding layers of the NMT model, by projecting general word embeddings induced from monolingual data in the target domain onto the source-domain embedding space. Experimental results on distant domain adaptation for English-to-Japanese translation and German-to-English translation indicate that our vocabulary adaptation improves the performance of fine-tuning by 3.6 BLEU points.
Early Discovery of Emerging Entities in Microblogs
Jul 08, 2019


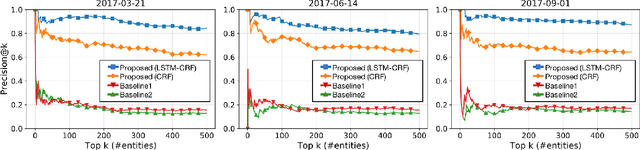
Keeping up to date on emerging entities that appear every day is indispensable for various applications, such as social-trend analysis and marketing research. Previous studies have attempted to detect unseen entities that are not registered in a particular knowledge base as emerging entities and consequently find non-emerging entities since the absence of entities in knowledge bases does not guarantee their emergence. We therefore introduce a novel task of discovering truly emerging entities when they have just been introduced to the public through microblogs and propose an effective method based on time-sensitive distant supervision, which exploits distinctive early-stage contexts of emerging entities. Experimental results with a large-scale Twitter archive show that the proposed method achieves 83.2% precision of the top 500 discovered emerging entities, which outperforms baselines based on unseen entity recognition with burst detection. Besides notable emerging entities, our method can discover massive long-tail and homographic emerging entities. An evaluation of relative recall shows that the method detects 80.4% emerging entities newly registered in Wikipedia; 92.4% of them are discovered earlier than their registration in Wikipedia, and the average lead-time is more than one year (571 days).
* Fixed errata in IJCAI paper. Dataset is available here:http://www.tkl.iis.u-tokyo.ac.jp/~akasaki/ijcai19.html
Learning to Describe Phrases with Local and Global Contexts
Nov 01, 2018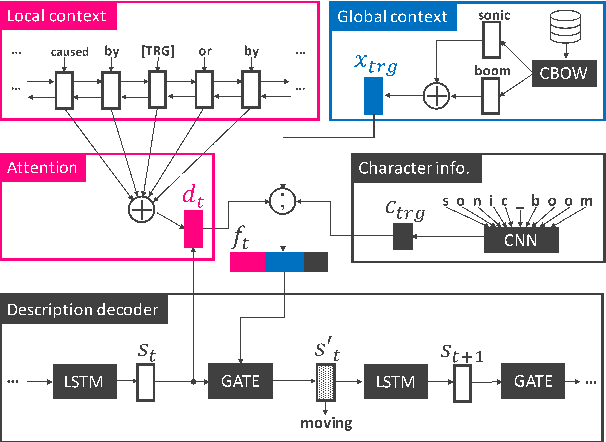
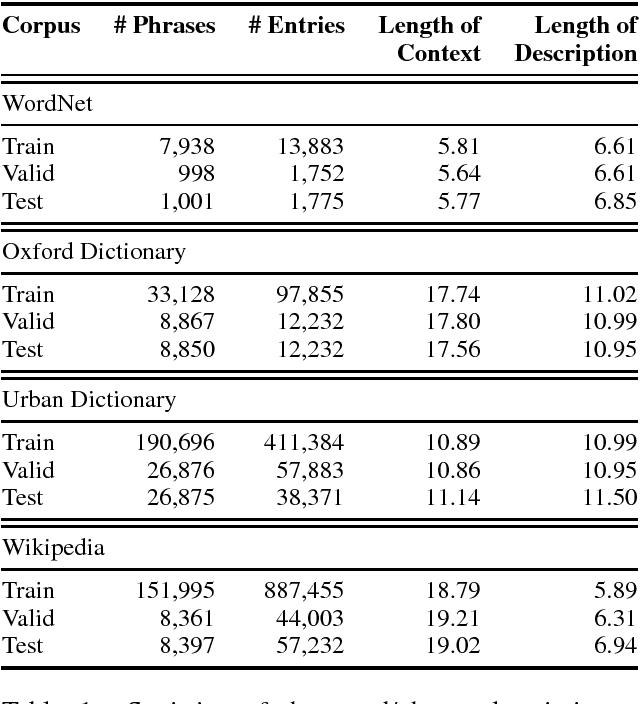

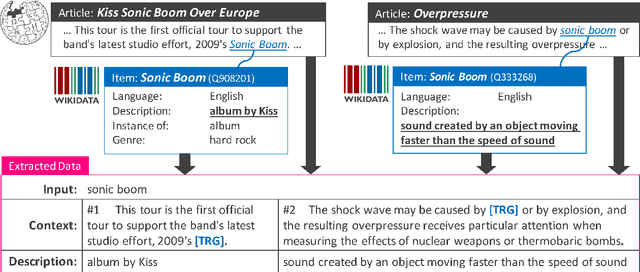
When reading a text, it is common to become stuck on unfamiliar words and phrases, such as polysemous words with novel senses, rarely used idioms, Internet slang, or emerging entities. At first, we attempt to figure out the meaning of those expressions from their context, and ultimately we may consult a dictionary for their definitions. However, rarely-used senses or emerging entities are not always covered by the hand-crafted definitions in existing dictionaries, which can cause problems in text comprehension. This paper undertakes a task of describing (or defining) a given expression (word or phrase) based on its usage contexts, and presents a novel neural-network generator for expressing its meaning as a natural language description. Experimental results on four datasets (including WordNet, Oxford and Urban Dictionaries, non-standard English, and Wikipedia) demonstrate the effectiveness of our method over previous methods for definition generation[Noraset+17; Gadetsky+18; Ni+17].