 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Discovery of Disappearing Entities in Microblogs
Oct 13, 2022
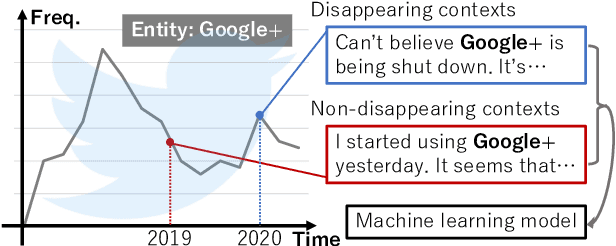
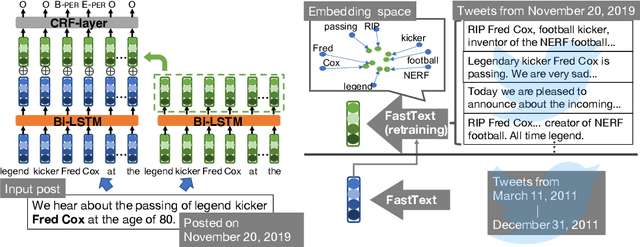
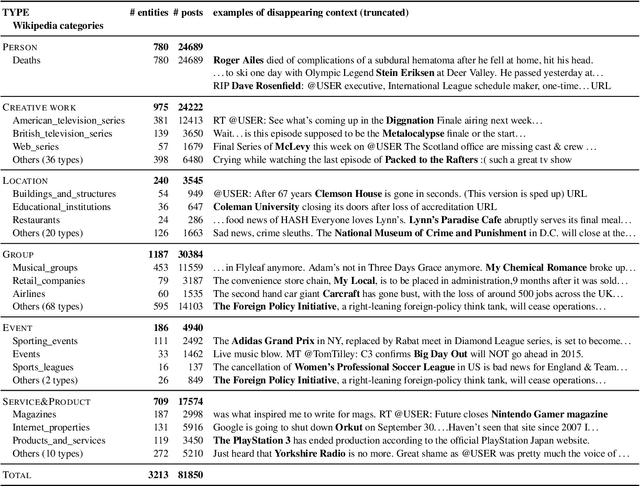
We make decisions by reacting to changes in the real world, in particular, the emergence and disappearance of impermanent entities such as events, restaurants, and services. Because we want to avoid missing out on opportunities or making fruitless actions after they have disappeared, it is important to know when entities disappear as early as possible. We thus tackle the task of detecting disappearing entities from microblogs, whose posts mention various entities, in a timely manner. The major challenge is detecting uncertain contexts of disappearing entities from noisy microblog posts. To collect these disappearing contexts, we design time-sensitive distant supervision, which utilizes entities from the knowledge base and time-series posts, for this task to build large-scale Twitter datasets\footnote{We will release the datasets (tweet IDs) used in the experiments to promote reproducibility.} for English and Japanese. To ensure robust detection in noisy environments, we refine pretrained word embeddings of the detection model on microblog streams of the target day. Experimental results on the Twitter datasets confirmed the effectiveness of the collected labeled data and refined word embeddings; more than 70\% of the detected disappearing entities in Wikipedia are discovered earlier than the update on Wikipedia, and the average lead-time is over one month.
Early Discovery of Emerging Entities in Microblogs
Jul 08, 2019


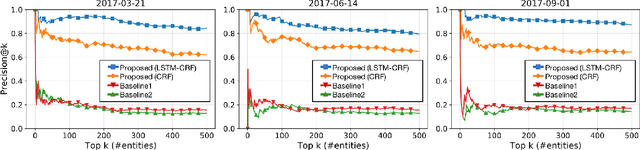
Keeping up to date on emerging entities that appear every day is indispensable for various applications, such as social-trend analysis and marketing research. Previous studies have attempted to detect unseen entities that are not registered in a particular knowledge base as emerging entities and consequently find non-emerging entities since the absence of entities in knowledge bases does not guarantee their emergence. We therefore introduce a novel task of discovering truly emerging entities when they have just been introduced to the public through microblogs and propose an effective method based on time-sensitive distant supervision, which exploits distinctive early-stage contexts of emerging entities. Experimental results with a large-scale Twitter archive show that the proposed method achieves 83.2% precision of the top 500 discovered emerging entities, which outperforms baselines based on unseen entity recognition with burst detection. Besides notable emerging entities, our method can discover massive long-tail and homographic emerging entities. An evaluation of relative recall shows that the method detects 80.4% emerging entities newly registered in Wikipedia; 92.4% of them are discovered earlier than their registration in Wikipedia, and the average lead-time is more than one year (571 days).
* Fixed errata in IJCAI paper. Dataset is available here:http://www.tkl.iis.u-tokyo.ac.jp/~akasaki/ijcai19.html
Chat Detection in an Intelligent Assistant: Combining Task-oriented and Non-task-oriented Spoken Dialogue Systems
Jul 24, 2018
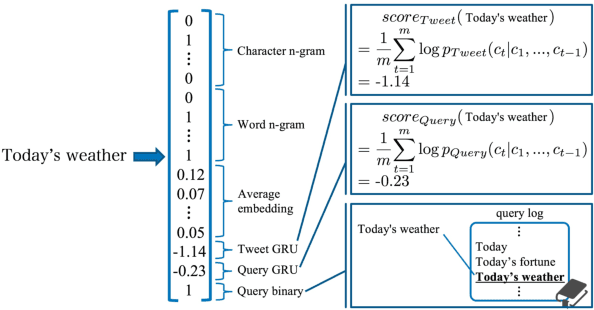

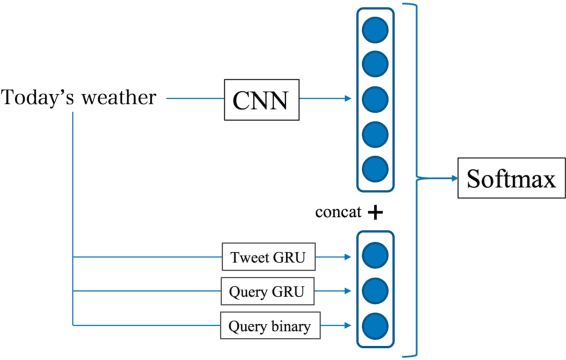
Recently emerged intelligent assistants on smartphones and home electronics (e.g., Siri and Alexa) can be seen as novel hybrids of domain-specific task-oriented spoken dialogue systems and open-domain non-task-oriented ones. To realize such hybrid dialogue systems, this paper investigates determining whether or not a user is going to have a chat with the system. To address the lack of benchmark datasets for this task, we construct a new dataset consisting of 15; 160 utterances collected from the real log data of a commercial intelligent assistant (and will release the dataset to facilitate future research activity). In addition, we investigate using tweets and Web search queries for handling open-domain user utterances, which characterize the task of chat detection. Experiments demonstrated that, while simple supervised methods are effective, the use of the tweets and search queries further improves the F1-score from 86.21 to 87.53.