 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Cross-Lingual Summarization: A Corpus-based Study and A New Benchmark with Improved Annotation
Jul 08, 2023
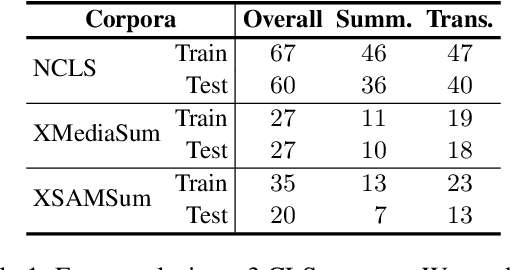
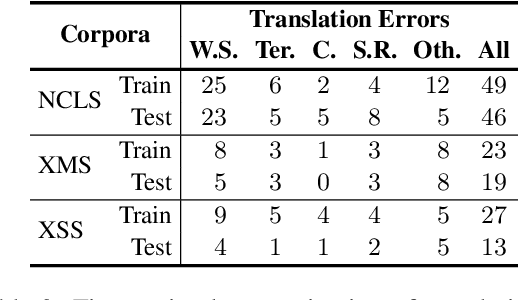
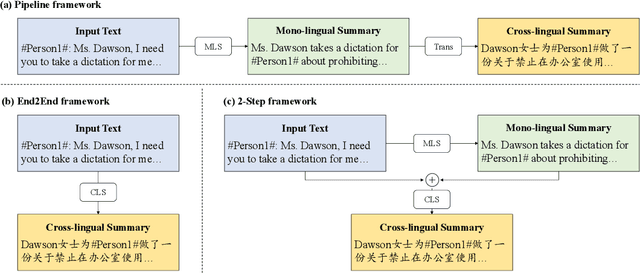
Most existing cross-lingual summarization (CLS) work constructs CLS corpora by simply and directly translating pre-annotated summaries from one language to another, which can contain errors from both summarization and translation processes. To address this issue, we propose ConvSumX, a cross-lingual conversation summarization benchmark, through a new annotation schema that explicitly considers source input context. ConvSumX consists of 2 sub-tasks under different real-world scenarios, with each covering 3 language directions. We conduct thorough analysis on ConvSumX and 3 widely-used manually annotated CLS corpora and empirically find that ConvSumX is more faithful towards input text. Additionally, based on the same intuition, we propose a 2-Step method, which takes both conversation and summary as input to simulate human annotation process. Experimental results show that 2-Step method surpasses strong baselines on ConvSumX under both automatic and human evaluation. Analysis shows that both source input text and summary are crucial for modeling cross-lingual summaries.
Recurrent Neural Networks with Mixed Hierarchical Structures and EM Algorithm for Natural Language Processing
Jan 21, 2022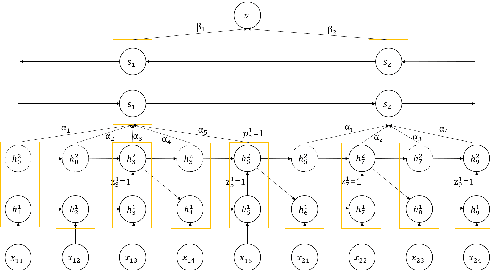

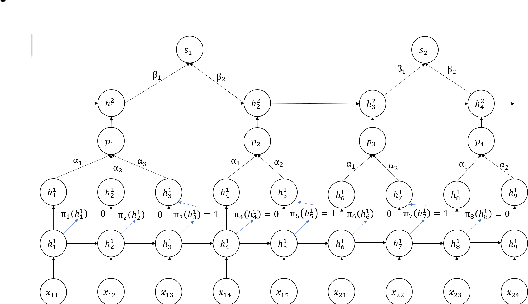
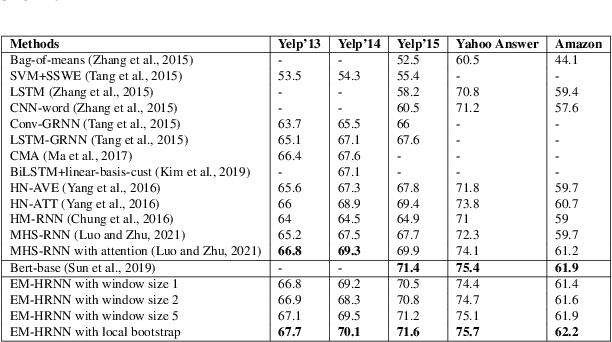
How to obtain hierarchical representations with an increasing level of abstraction becomes one of the key issues of learning with deep neural networks. A variety of RNN models have recently been proposed to incorporate both explicit and implicit hierarchical information in modeling languages in the literature. In this paper, we propose a novel approach called the latent indicator layer to identify and learn implicit hierarchical information (e.g., phrases), and further develop an EM algorithm to handle the latent indicator layer in training. The latent indicator layer further simplifies a text's hierarchical structure, which allows us to seamlessly integrate different levels of attention mechanisms into the structure. We called the resulting architecture as the EM-HRNN model. Furthermore, we develop two bootstrap strategies to effectively and efficiently train the EM-HRNN model on long text documents. Simulation studies and real data applications demonstrate that the EM-HRNN model with bootstrap training outperforms other RNN-based models in document classification tasks. The performance of the EM-HRNN model is comparable to a Transformer-based method called Bert-base, though the former is much smaller model and does not require pre-training.
2020 U.S. Presidential Election: Analysis of Female and Male Users on Twitter
Aug 21, 2021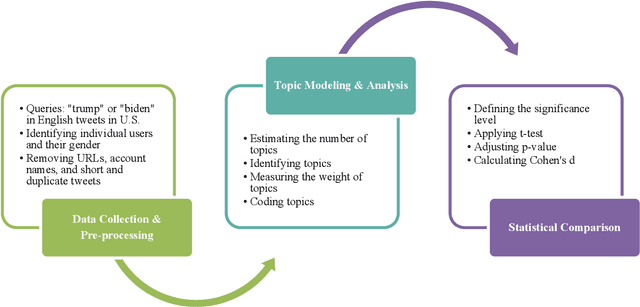
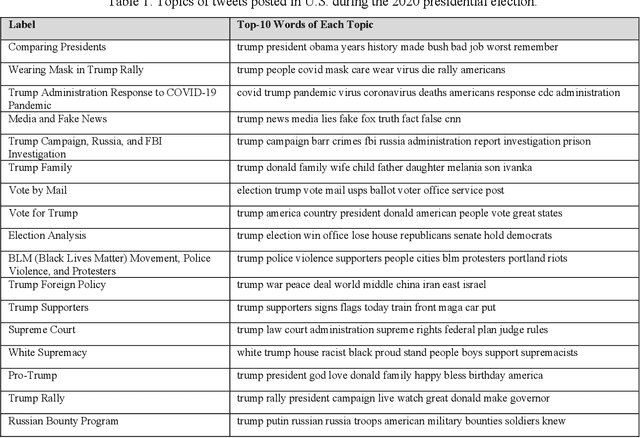
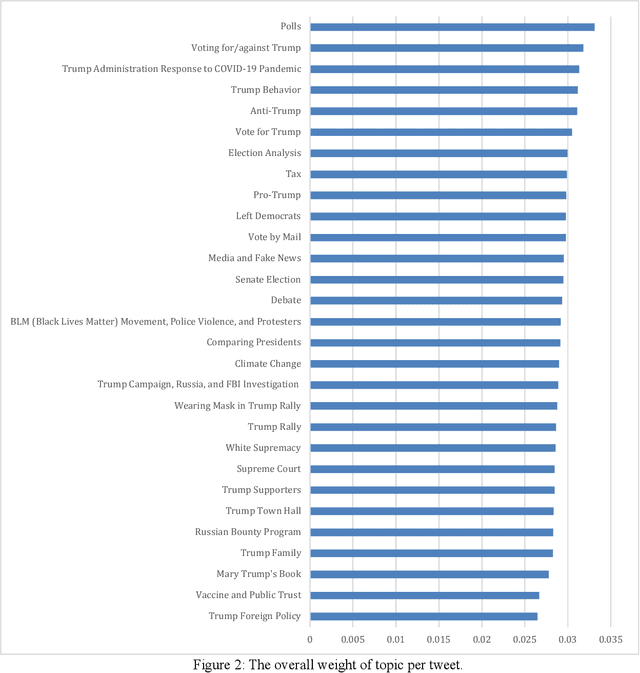
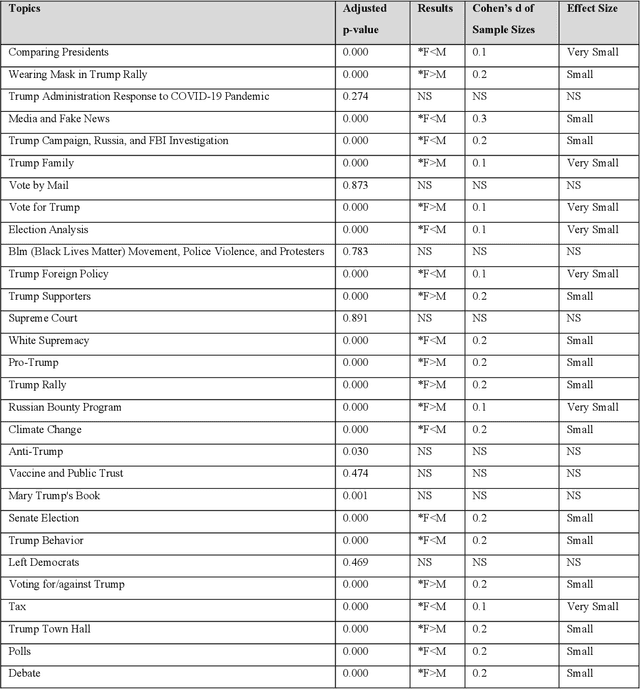
Social media is commonly used by the public during election campaigns to express their opinions regarding different issues. Among various social media channels, Twitter provides an efficient platform for researchers and politicians to explore public opinion regarding a wide range of topics such as economy and foreign policy. Current literature mainly focuses on analyzing the content of tweets without considering the gender of users. This research collects and analyzes a large number of tweets and uses computational, human coding, and statistical analyses to identify topics in more than 300,000 tweets posted during the 2020 U.S. presidential election and to compare female and male users regarding the average weight of the topics. Our findings are based upon a wide range of topics, such as tax, climate change, and the COVID-19 pandemic. Out of the topics, there exists a significant difference between female and male users for more than 70% of topics. Our research approach can inform studies in the areas of informatics, politics, and communication, and it can be used by political campaigns to obtain a gender-based understanding of public opinion.
COVID-19 Vaccine and Social Media: Exploring Emotions and Discussions on Twitter
Jul 29, 2021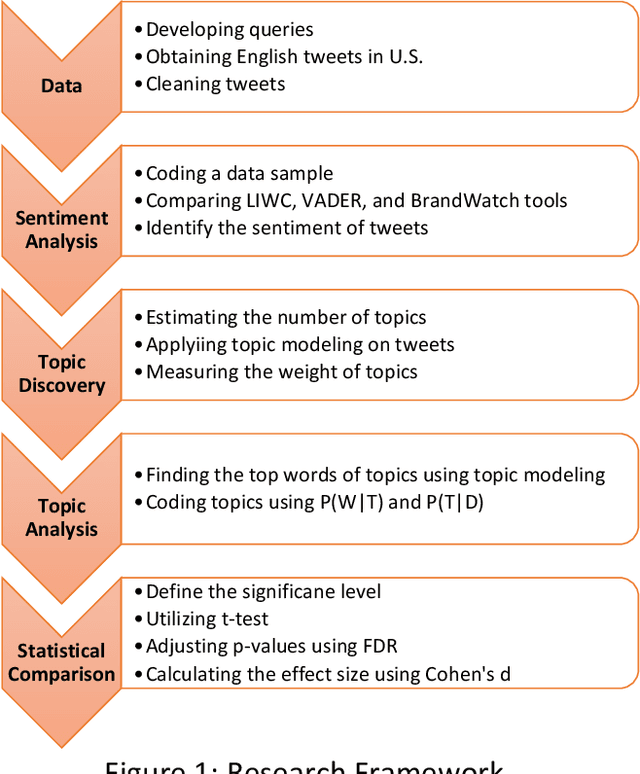
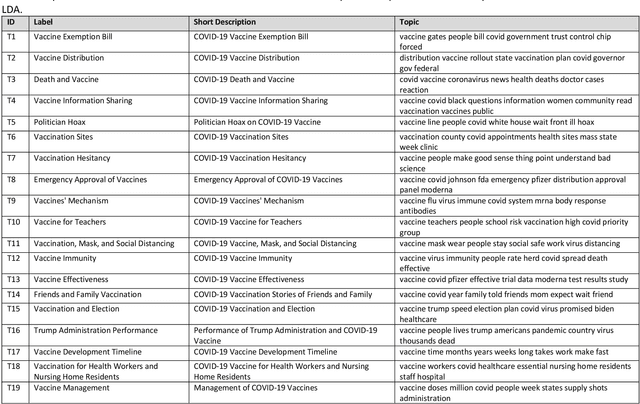
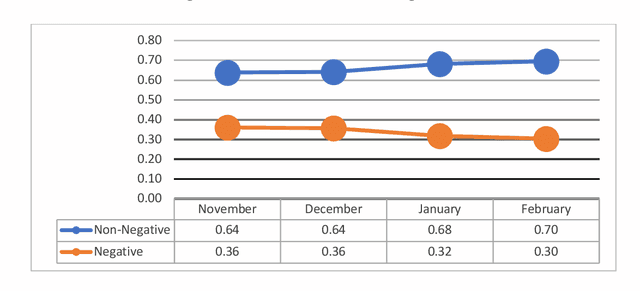
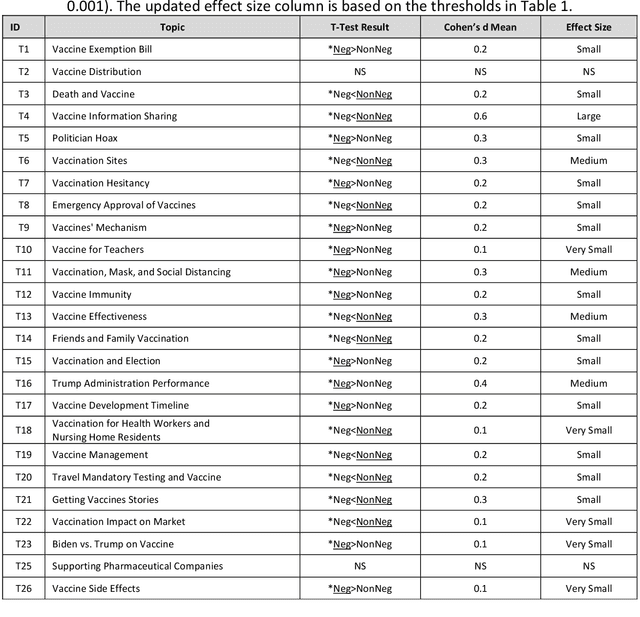
Public response to COVID-19 vaccines is the key success factor to control the COVID-19 pandemic. To understand the public response, there is a need to explore public opinion. Traditional surveys are expensive and time-consuming, address limited health topics, and obtain small-scale data. Twitter can provide a great opportunity to understand public opinion regarding COVID-19 vaccines. The current study proposes an approach using computational and human coding methods to collect and analyze a large number of tweets to provide a wider perspective on the COVID-19 vaccine. This study identifies the sentiment of tweets and their temporal trend, discovers major topics, compares topics of negative and non-negative tweets, and discloses top topics of negative and non-negative tweets. Our findings show that the negative sentiment regarding the COVID-19 vaccine had a decreasing trend between November 2020 and February 2021. We found Twitter users have discussed a wide range of topics from vaccination sites to the 2020 U.S. election between November 2020 and February 2021. The findings show that there was a significant difference between negative and non-negative tweets regarding the weight of most topics. Our results also indicate that the negative and non-negative tweets had different topic priorities and focuses.
Recurrent Neural Networks with Mixed Hierarchical Structures for Natural Language Processing
Jun 04, 2021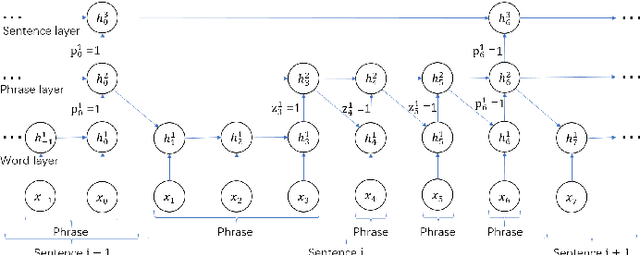
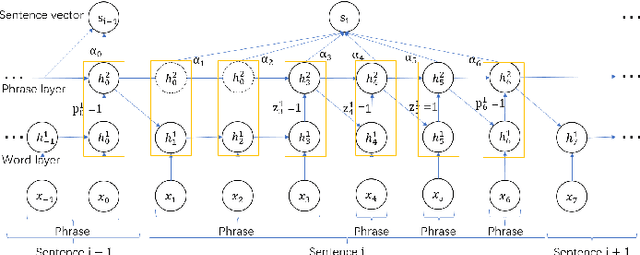

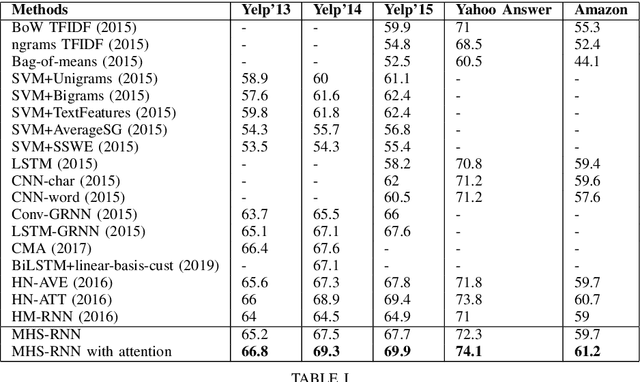
Hierarchical structures exist in both linguistics and Natural Language Processing (NLP) tasks. How to design RNNs to learn hierarchical representations of natural languages remains a long-standing challenge. In this paper, we define two different types of boundaries referred to as static and dynamic boundaries, respectively, and then use them to construct a multi-layer hierarchical structure for document classification tasks. In particular, we focus on a three-layer hierarchical structure with static word- and sentence- layers and a dynamic phrase-layer. LSTM cells and two boundary detectors are used to implement the proposed structure, and the resulting network is called the {\em Recurrent Neural Network with Mixed Hierarchical Structures} (MHS-RNN). We further add three layers of attention mechanisms to the MHS-RNN model. Incorporating attention mechanisms allows our model to use more important content to construct document representation and enhance its performance on document classification tasks. Experiments on five different datasets show that the proposed architecture outperforms previous methods on all the five tasks.
Multi-level Training and Bayesian Optimization for Economical Hyperparameter Optimization
Jul 20, 2020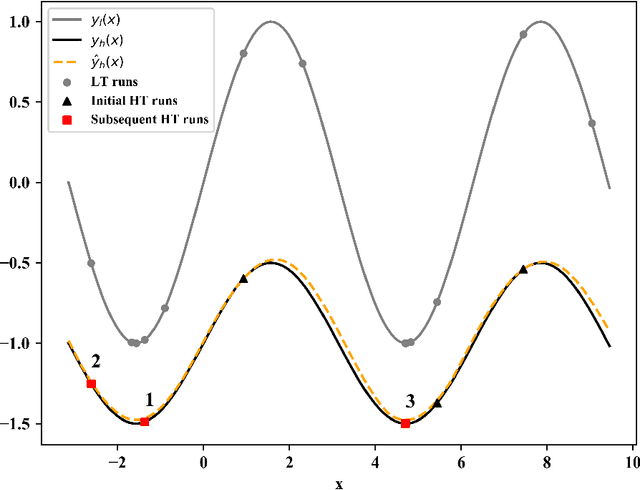


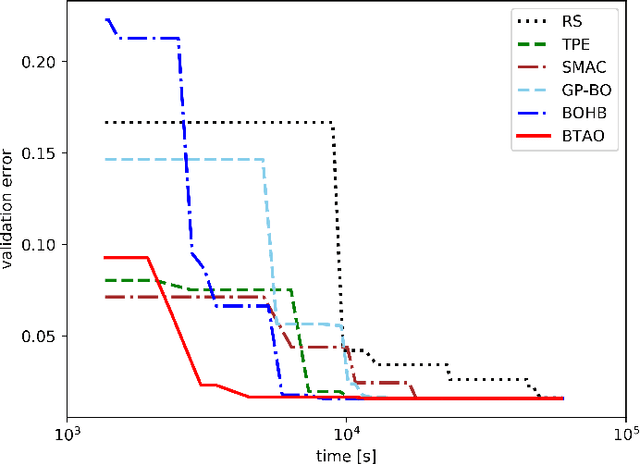
Hyperparameters play a critical role in the performances of many machine learning methods. Determining their best settings or Hyperparameter Optimization (HPO) faces difficulties presented by the large number of hyperparameters as well as the excessive training time. In this paper, we develop an effective approach to reducing the total amount of required training time for HPO. In the initialization, the nested Latin hypercube design is used to select hyperparameter configurations for two types of training, which are, respectively, heavy training and light training. We propose a truncated additive Gaussian process model to calibrate approximate performance measurements generated by light training, using accurate performance measurements generated by heavy training. Based on the model, a sequential model-based algorithm is developed to generate the performance profile of the configuration space as well as find optimal ones. Our proposed approach demonstrates competitive performance when applied to optimize synthetic examples, support vector machines, fully connected networks and convolutional neural networks.
Towards Differentiable Resampling
Apr 24, 2020

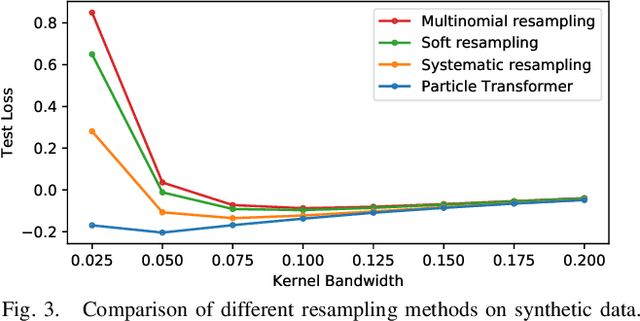

Resampling is a key component of sample-based recursive state estimation in particle filters. Recent work explores differentiable particle filters for end-to-end learning. However, resampling remains a challenge in these works, as it is inherently non-differentiable. We address this challenge by replacing traditional resampling with a learned neural network resampler. We present a novel network architecture, the particle transformer, and train it for particle resampling using a likelihood-based loss function over sets of particles. Incorporated into a differentiable particle filter, our model can be end-to-end optimized jointly with the other particle filter components via gradient descent. Our results show that our learned resampler outperforms traditional resampling techniques on synthetic data and in a simulated robot localization task.
To prune, or not to prune: exploring the efficacy of pruning for model compression
Nov 13, 2017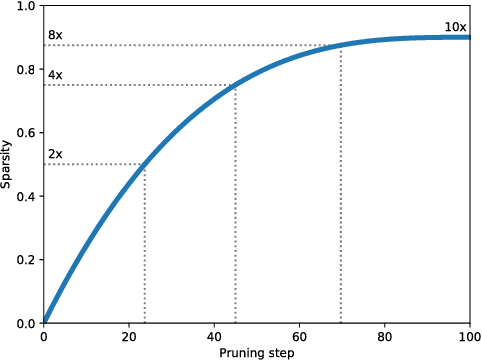
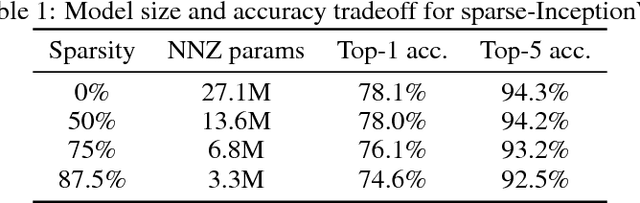
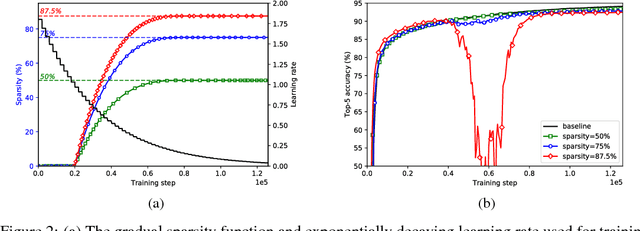
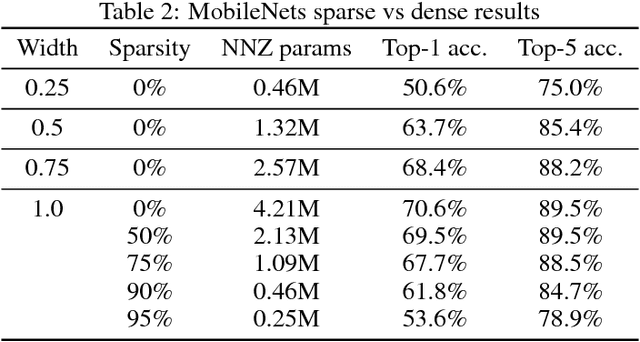
Model pruning seeks to induce sparsity in a deep neural network's various connection matrices, thereby reducing the number of nonzero-valued parameters in the model. Recent reports (Han et al., 2015; Narang et al., 2017) prune deep networks at the cost of only a marginal loss in accuracy and achieve a sizable reduction in model size. This hints at the possibility that the baseline models in these experiments are perhaps severely over-parameterized at the outset and a viable alternative for model compression might be to simply reduce the number of hidden units while maintaining the model's dense connection structure, exposing a similar trade-off in model size and accuracy. We investigate these two distinct paths for model compression within the context of energy-efficient inference in resource-constrained environments and propose a new gradual pruning technique that is simple and straightforward to apply across a variety of models/datasets with minimal tuning and can be seamlessly incorporated within the training process. We compare the accuracy of large, but pruned models (large-sparse) and their smaller, but dense (small-dense) counterparts with identical memory footprint. Across a broad range of neural network architectures (deep CNNs, stacked LSTM, and seq2seq LSTM models), we find large-sparse models to consistently outperform small-dense models and achieve up to 10x reduction in number of non-zero parameters with minimal loss in accuracy.
A Practical Algorithm for Topic Modeling with Provable Guarantees
Dec 19, 2012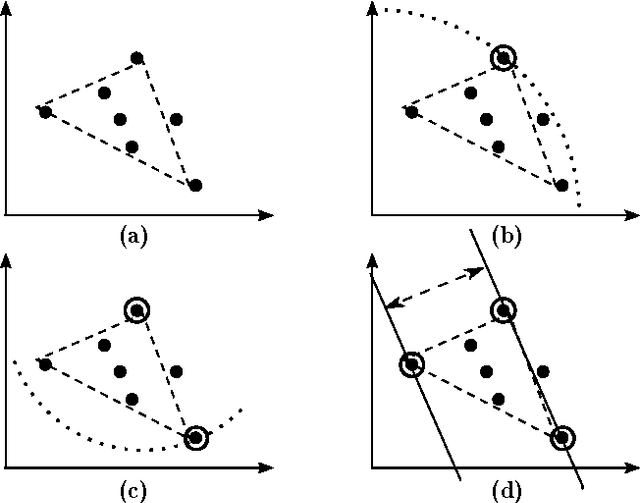
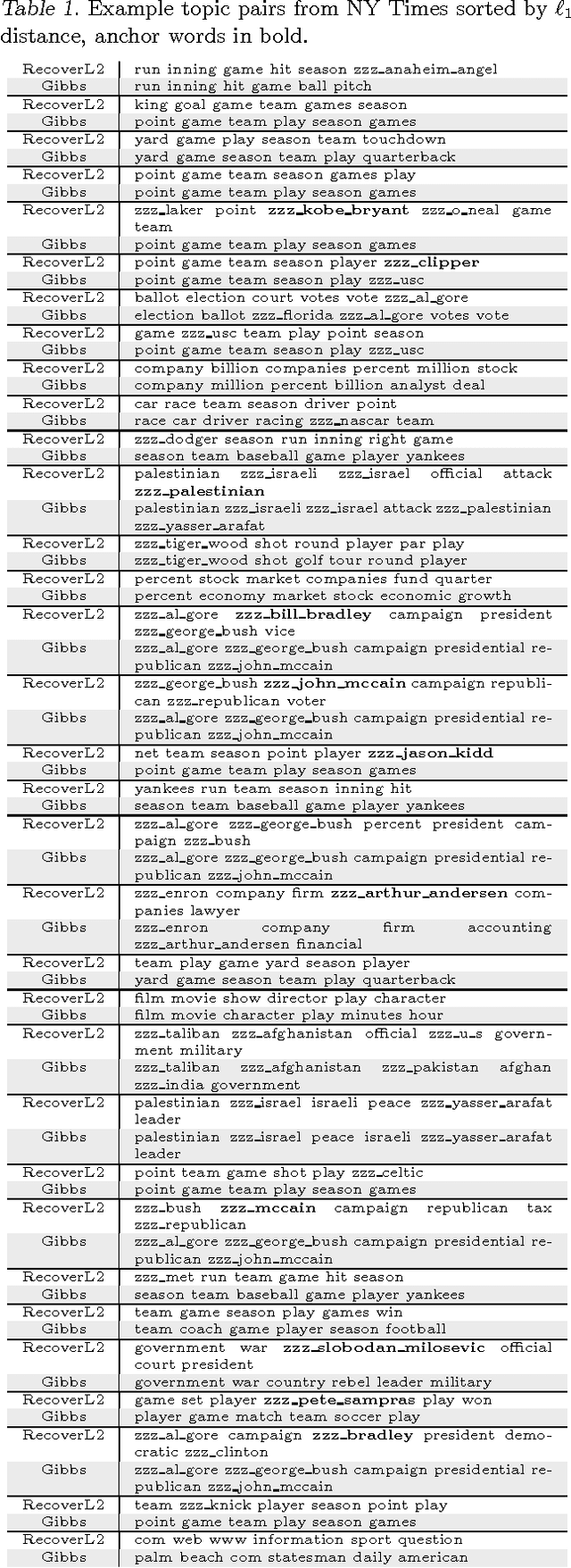
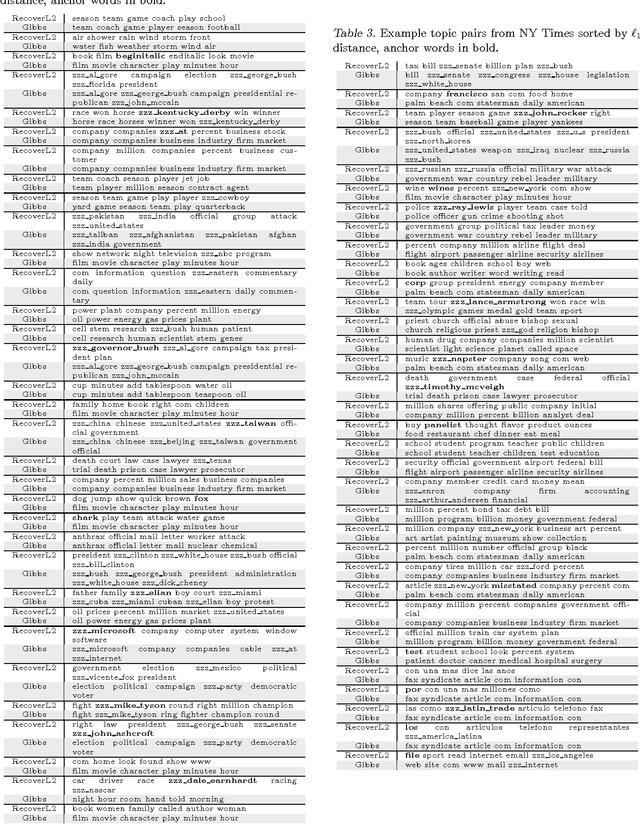
Topic models provide a useful method for dimensionality reduction and exploratory data analysis in large text corpora. Most approaches to topic model inference have been based on a maximum likelihood objective. Efficient algorithms exist that approximate this objective, but they have no provable guarantees. Recently, algorithms have been introduced that provide provable bounds, but these algorithms are not practical because they are inefficient and not robust to violations of model assumptions. In this paper we present an algorithm for topic model inference that is both provable and practical. The algorithm produces results comparable to the best MCMC implementations while running orders of magnitude faster.