 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Networks with Mixed Hierarchical Structures and EM Algorithm for Natural Language Processing
Jan 21, 2022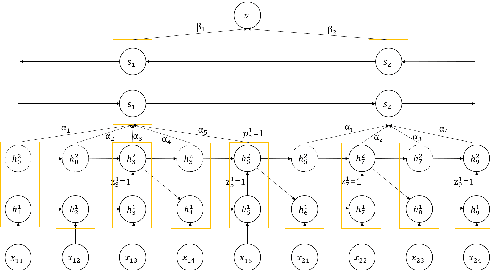

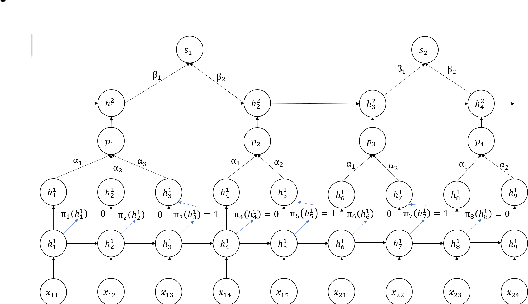
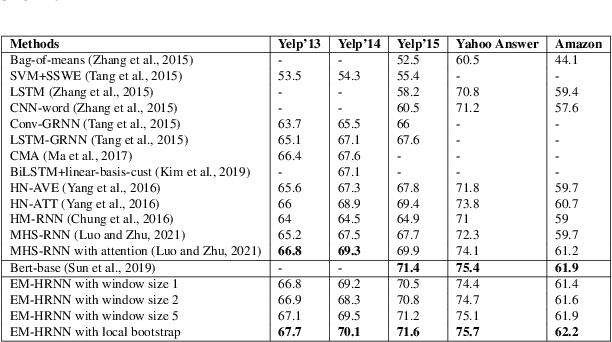
How to obtain hierarchical representations with an increasing level of abstraction becomes one of the key issues of learning with deep neural networks. A variety of RNN models have recently been proposed to incorporate both explicit and implicit hierarchical information in modeling languages in the literature. In this paper, we propose a novel approach called the latent indicator layer to identify and learn implicit hierarchical information (e.g., phrases), and further develop an EM algorithm to handle the latent indicator layer in training. The latent indicator layer further simplifies a text's hierarchical structure, which allows us to seamlessly integrate different levels of attention mechanisms into the structure. We called the resulting architecture as the EM-HRNN model. Furthermore, we develop two bootstrap strategies to effectively and efficiently train the EM-HRNN model on long text documents. Simulation studies and real data applications demonstrate that the EM-HRNN model with bootstrap training outperforms other RNN-based models in document classification tasks. The performance of the EM-HRNN model is comparable to a Transformer-based method called Bert-base, though the former is much smaller model and does not require pre-training.
Recurrent Neural Networks with Mixed Hierarchical Structures for Natural Language Processing
Jun 04, 2021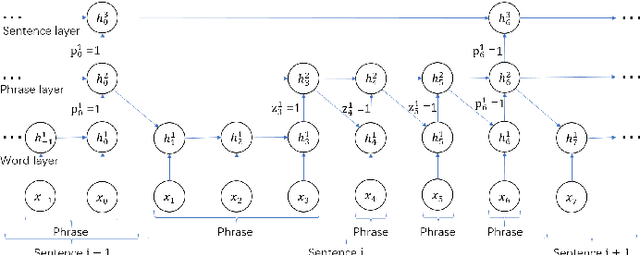
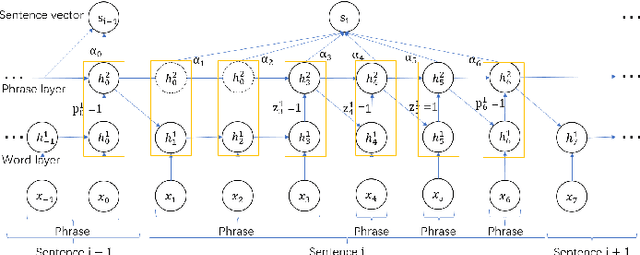

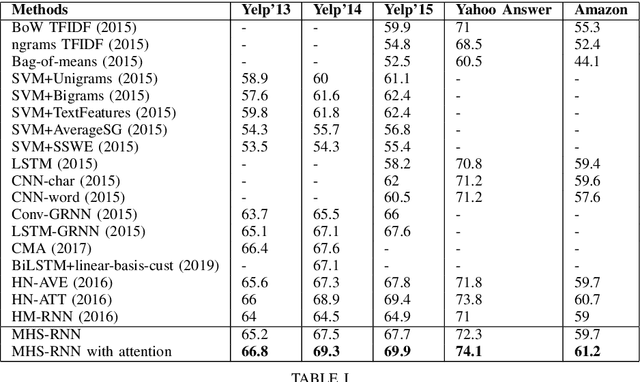
Hierarchical structures exist in both linguistics and Natural Language Processing (NLP) tasks. How to design RNNs to learn hierarchical representations of natural languages remains a long-standing challenge. In this paper, we define two different types of boundaries referred to as static and dynamic boundaries, respectively, and then use them to construct a multi-layer hierarchical structure for document classification tasks. In particular, we focus on a three-layer hierarchical structure with static word- and sentence- layers and a dynamic phrase-layer. LSTM cells and two boundary detectors are used to implement the proposed structure, and the resulting network is called the {\em Recurrent Neural Network with Mixed Hierarchical Structures} (MHS-RNN). We further add three layers of attention mechanisms to the MHS-RNN model. Incorporating attention mechanisms allows our model to use more important content to construct document representation and enhance its performance on document classification tasks. Experiments on five different datasets show that the proposed architecture outperforms previous methods on all the five tasks.