 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2020 U.S. Presidential Election: Analysis of Female and Male Users on Twitter
Aug 21, 2021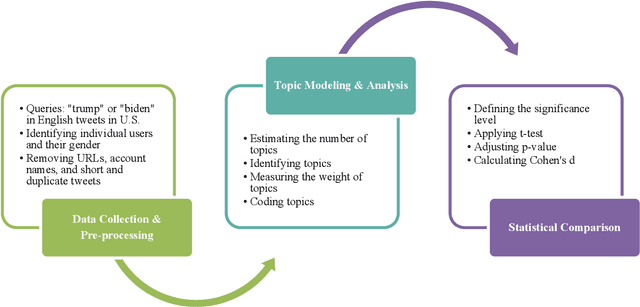
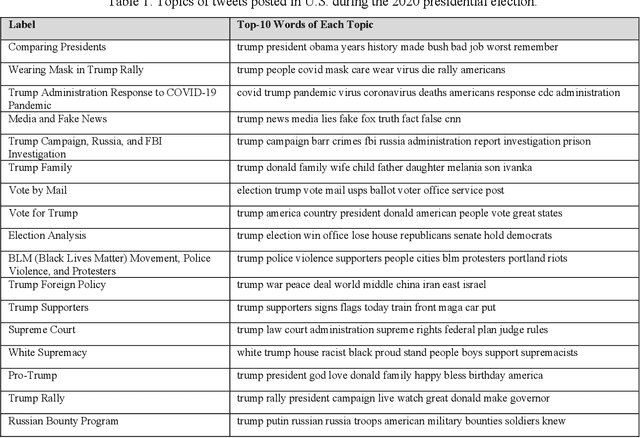
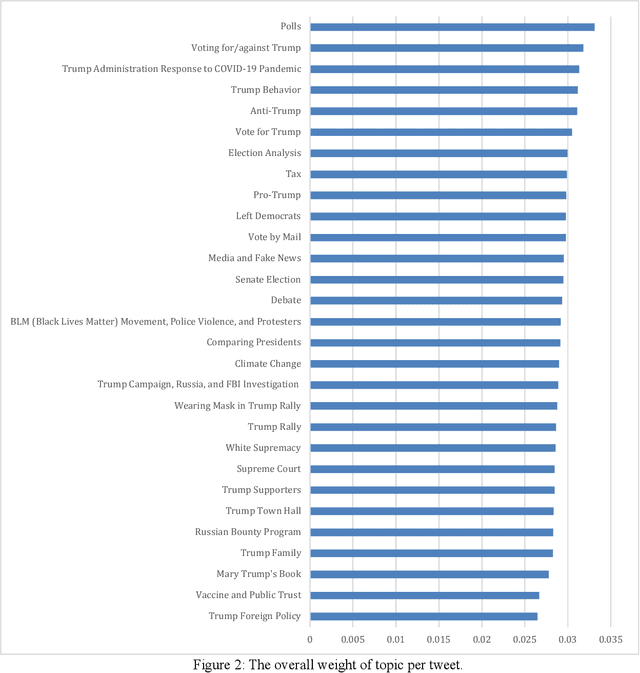
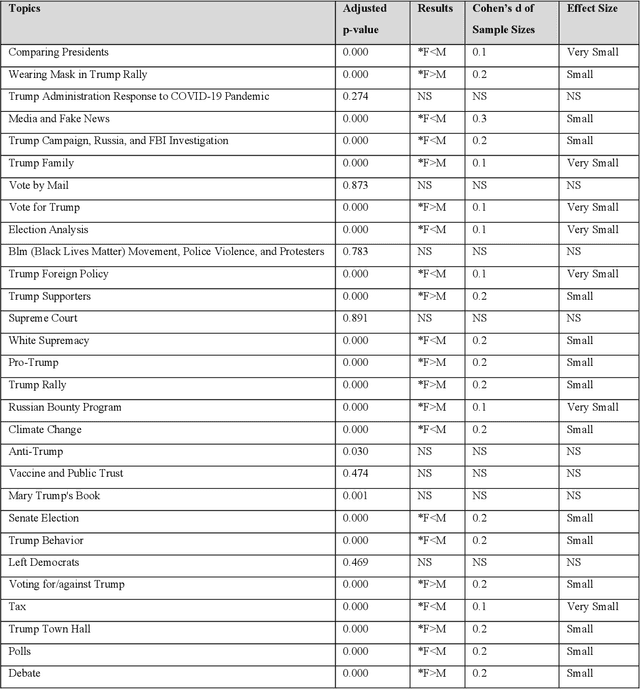
Social media is commonly used by the public during election campaigns to express their opinions regarding different issues. Among various social media channels, Twitter provides an efficient platform for researchers and politicians to explore public opinion regarding a wide range of topics such as economy and foreign policy. Current literature mainly focuses on analyzing the content of tweets without considering the gender of users. This research collects and analyzes a large number of tweets and uses computational, human coding, and statistical analyses to identify topics in more than 300,000 tweets posted during the 2020 U.S. presidential election and to compare female and male users regarding the average weight of the topics. Our findings are based upon a wide range of topics, such as tax, climate change, and the COVID-19 pandemic. Out of the topics, there exists a significant difference between female and male users for more than 70% of topics. Our research approach can inform studies in the areas of informatics, politics, and communication, and it can be used by political campaigns to obtain a gender-based understanding of public opinion.
COVID-19 Vaccine and Social Media: Exploring Emotions and Discussions on Twitter
Jul 29, 2021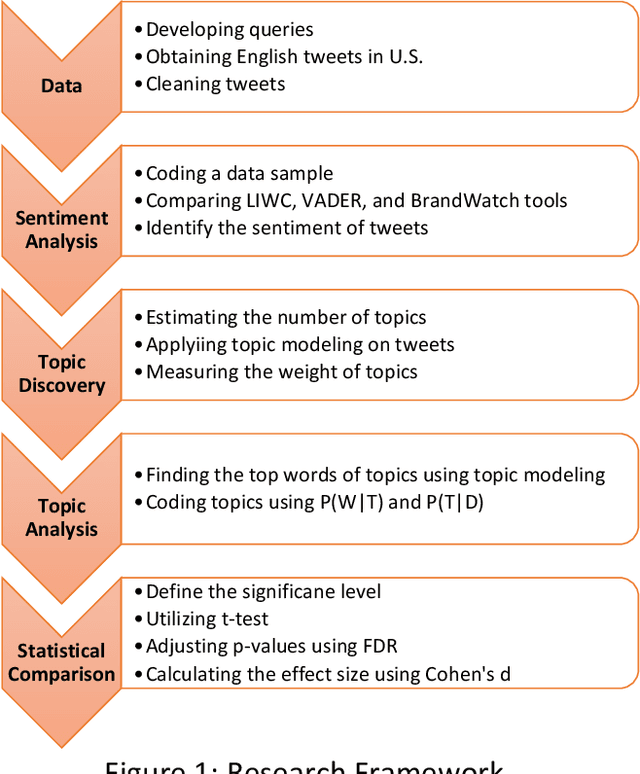
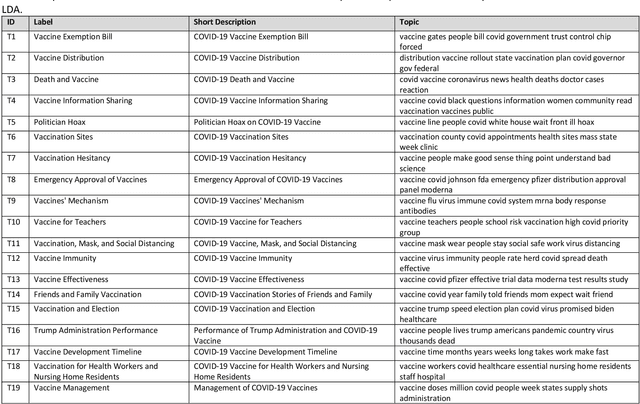
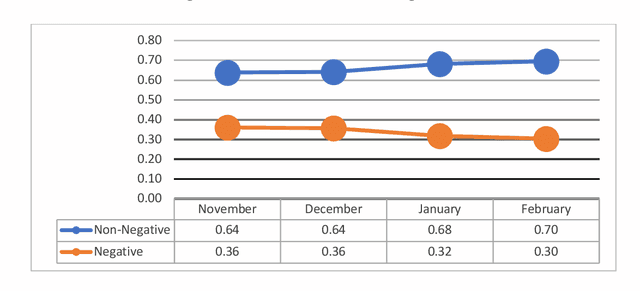
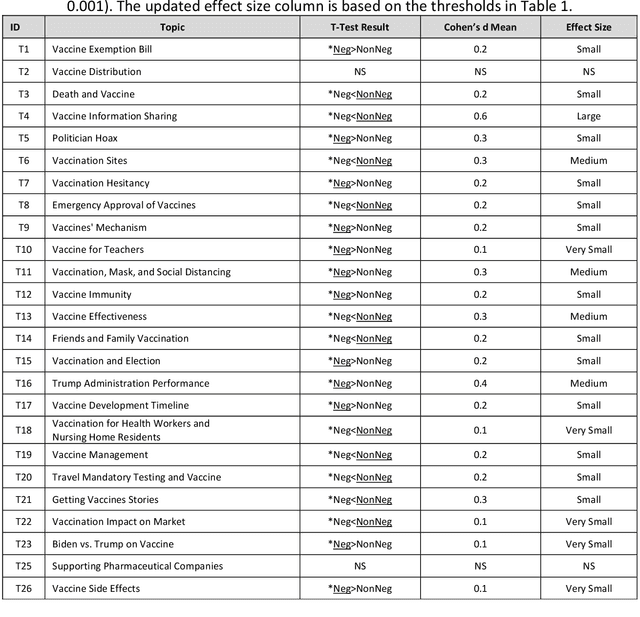
Public response to COVID-19 vaccines is the key success factor to control the COVID-19 pandemic. To understand the public response, there is a need to explore public opinion. Traditional surveys are expensive and time-consuming, address limited health topics, and obtain small-scale data. Twitter can provide a great opportunity to understand public opinion regarding COVID-19 vaccines. The current study proposes an approach using computational and human coding methods to collect and analyze a large number of tweets to provide a wider perspective on the COVID-19 vaccine. This study identifies the sentiment of tweets and their temporal trend, discovers major topics, compares topics of negative and non-negative tweets, and discloses top topics of negative and non-negative tweets. Our findings show that the negative sentiment regarding the COVID-19 vaccine had a decreasing trend between November 2020 and February 2021. We found Twitter users have discussed a wide range of topics from vaccination sites to the 2020 U.S. election between November 2020 and February 2021. The findings show that there was a significant difference between negative and non-negative tweets regarding the weight of most topics. Our results also indicate that the negative and non-negative tweets had different topic priorities and focuses.
Unwanted Advances in Higher Education: Uncovering Sexual Harassment Experiences in Academia with Text Mining
Dec 11, 2019Sexual harassment in academia is often a hidden problem because victims are usually reluctant to report their experiences. Recently, a web survey was developed to provide an opportunity to share thousands of sexual harassment experiences in academia. Using an efficient approach, this study collected and investigated more than 2,000 sexual harassment experiences to better understand these unwanted advances in higher education. This paper utilized text mining to disclose hidden topics and explore their weight across three variables: harasser gender, institution type, and victim's field of study. We mapped the topics on five themes drawn from the sexual harassment literature and found that more than 50% of the topics were assigned to the unwanted sexual attention theme. Fourteen percent of the topics were in the gender harassment theme, in which insulting, sexist, or degrading comments or behavior was directed towards women. Five percent of the topics involved sexual coercion (a benefit is offered in exchange for sexual favors), 5% involved sex discrimination, and 7% of the topics discussed retaliation against the victim for reporting the harassment, or for simply not complying with the harasser. Findings highlight the power differential between faculty and students, and the toll on students when professors abuse their power. While some topics did differ based on type of institution, there were no differences between the topics based on gender of harasser or field of study. This research can be beneficial to researchers in further investigation of this paper's dataset, and to policymakers in improving existing policies to create a safe and supportive environment in academia.
FLATM: A Fuzzy Logic Approach Topic Model for Medical Documents
Nov 25, 2019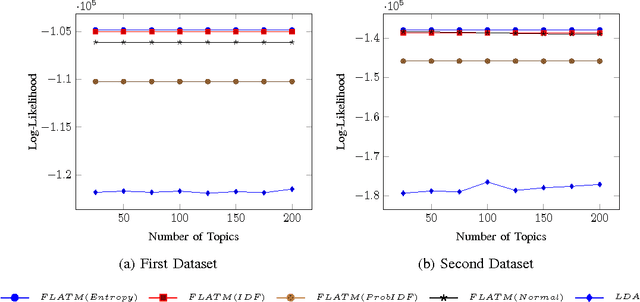
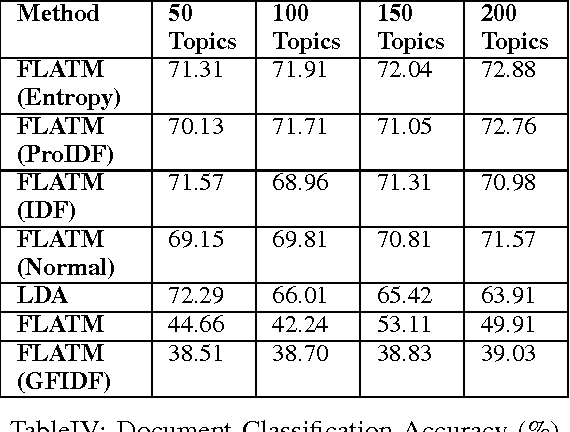
One of the challenges for text analysis in medical domains is analyzing large-scale medical documents. As a consequence, finding relevant documents has become more difficult. One of the popular methods to retrieve information based on discovering the themes in the documents is topic modeling. The themes in the documents help to retrieve documents on the same topic with and without a query. In this paper, we present a novel approach to topic modeling using fuzzy clustering. To evaluate our model, we experiment with two text datasets of medical documents. The evaluation metrics carried out through document classification and document modeling show that our model produces better performance than LDA, indicating that fuzzy set theory can improve the performance of topic models in medical domains.
Application of Fuzzy Clustering for Text Data Dimensionality Reduction
Sep 21, 2019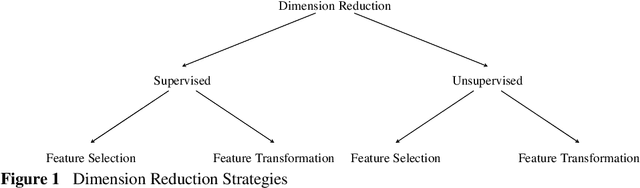

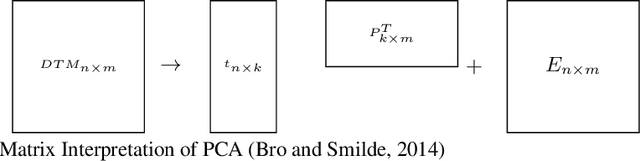

Large textual corpora are often represented by the document-term frequency matrix whose elements are the frequency of terms; however, this matrix has two problems: sparsity and high dimensionality. Four dimension reduction strategies are used to address these problems. Of the four strategies, unsupervised feature transformation (UFT) is a popular and efficient strategy to map the terms to a new basis in the document-term frequency matrix. Although several UFT-based methods have been developed, fuzzy clustering has not been considered for dimensionality reduction. This research explores fuzzy clustering as a new UFT-based approach to create a lower-dimensional representation of documents. Performance of fuzzy clustering with and without using global term weighting methods is shown to exceed principal component analysis and singular value decomposition. This study also explores the effect of applying different fuzzifier values on fuzzy clustering for dimensionality reduction purpose.
Hidden in Plain Sight For Too Long: Using Text Mining Techniques to Shine a Light on Workplace Sexism and Sexual Harassment
Jul 01, 2019
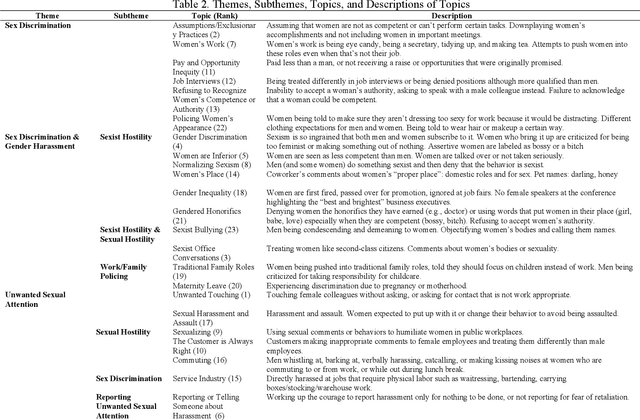
Objective: The goal of this study is to understand how people experience sexism and sexual harassment in the workplace by discovering themes in 2,362 experiences posted on the Everyday Sexism Project's website everydaysexism.com. Method: This study used both quantitative and qualitative methods. The quantitative method was a computational framework to collect and analyze a large number of workplace sexual harassment experiences. The qualitative method was the analysis of the topics generated by a text mining method. Results: Twenty-three topics were coded and then grouped into three overarching themes from the sex discrimination and sexual harassment literature. The Sex Discrimination theme included experiences in which women were treated unfavorably due to their sex, such as being passed over for promotion, denied opportunities, paid less than men, and ignored or talked over in meetings. The Sex Discrimination and Gender harassment theme included stories about sex discrimination and gender harassment, such as sexist hostility behaviors ranging from insults and jokes invoking misogynistic stereotypes to bullying behavior. The last theme, Unwanted Sexual Attention, contained stories describing sexual comments and behaviors used to degrade women. Unwanted touching was the highest weighted topic, indicating how common it was for website users to endure being touched, hugged or kissed, groped, and grabbed. Conclusions: This study illustrates how researchers can use automatic processes to go beyond the limits of traditional research methods and investigate naturally occurring large scale datasets on the internet to achieve a better understanding of everyday workplace sexism experiences.
Exploring Diseases and Syndromes in Neurology Case Reports from 1955 to 2017 with Text Mining
May 23, 2019
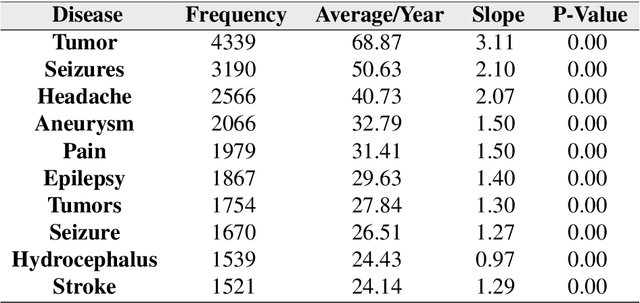
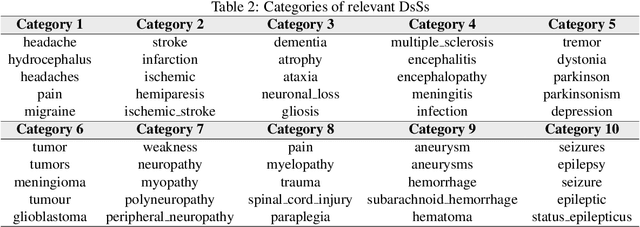
Background: A large number of neurology case reports have been published, but it is a challenging task for human medical experts to explore all of these publications. Text mining offers a computational approach to investigate neurology literature and capture meaningful patterns. The overarching goal of this study is to provide a new perspective on case reports of neurological disease and syndrome analysis over the last six decades using text mining. Methods: We extracted diseases and syndromes (DsSs) from more than 65,000 neurology case reports from 66 journals in PubMed over the last six decades from 1955 to 2017. Text mining was applied to reports on the detected DsSs to investigate high-frequency DsSs, categorize them, and explore the linear trends over the 63-year time frame. Results: The text mining methods explored high-frequency neurologic DsSs and their trends and the relationships between them from 1955 to 2017. We detected more than 18,000 unique DsSs and found 10 categories of neurologic DsSs. While the trend analysis showed the increasing trends in the case reports for top-10 high-frequency DsSs, the categories had mixed trends. Conclusion: Our study provided new insights into the application of text mining methods to investigate DsSs in a large number of medical case reports that occur over several decades. The proposed approach can be used to provide a macro level analysis of medical literature by discovering interesting patterns and tracking them over several years to help physicians explore these case reports more efficiently.
Twitter Speaks: A Case of National Disaster Situational Awareness
Mar 07, 2019

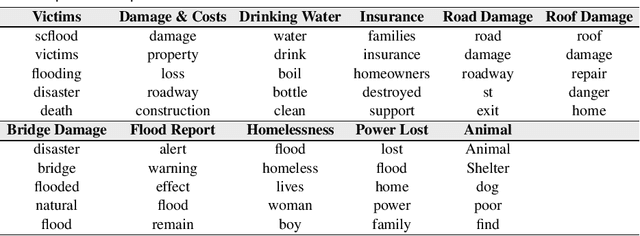
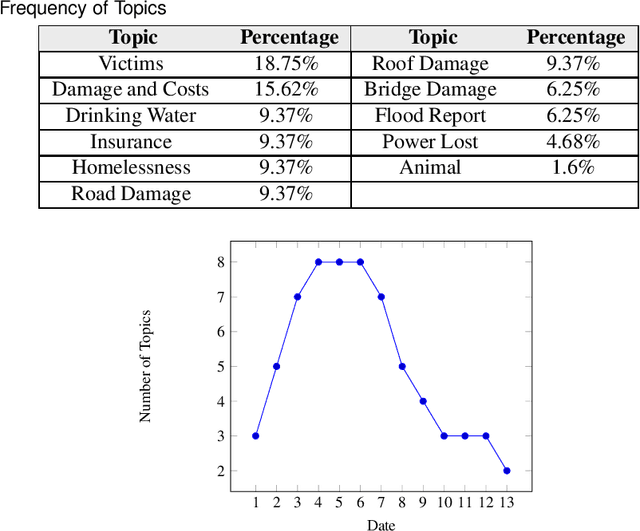
In recent years, we have been faced with a series of natural disasters causing a tremendous amount of financial, environmental, and human losses. The unpredictable nature of natural disasters' behavior makes it hard to have a comprehensive situational awareness (SA) to support disaster management. Using opinion surveys is a traditional approach to analyze public concerns during natural disasters; however, this approach is limited, expensive, and time-consuming. Luckily the advent of social media has provided scholars with an alternative means of analyzing public concerns. Social media enable users (people) to freely communicate their opinions and disperse information regarding current events including natural disasters. This research emphasizes the value of social media analysis and proposes an analytical framework: Twitter Situational Awareness (TwiSA). This framework uses text mining methods including sentiment analysis and topic modeling to create a better SA for disaster preparedness, response, and recovery. TwiSA has also effectively deployed on a large number of tweets and tracks the negative concerns of people during the 2015 South Carolina flood.
An Exploratory Study of Exercise in the Twittersphere
Dec 08, 2018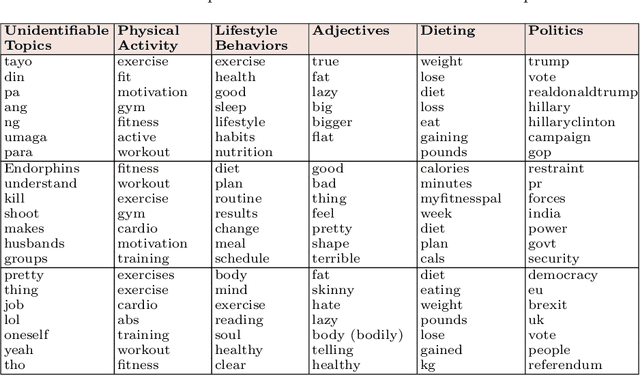

Social media analytics allows us to extract, analyze, and establish semantic from user-generated contents in social media platforms. This study utilized a mixed method including a three-step process of data collection, topic modeling, and data annotation for recognizing exercise related patterns. Based on the findings, 86% of the detected topics were identified as meaningful topics after conducting the data annotation process. The most discussed exercise-related topics were physical activity (18.7%), lifestyle behaviors (6.6%), and dieting (4%). The results from our experiment indicate that the exploratory data analysis is a practical approach to summarizing the various characteristics of text data for different health and medical applications.
Political Popularity Analysis in Social Media
Dec 08, 2018
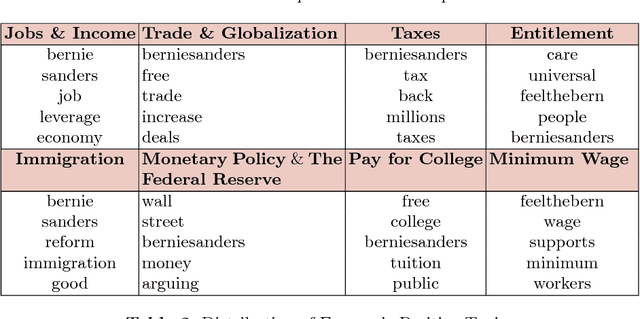
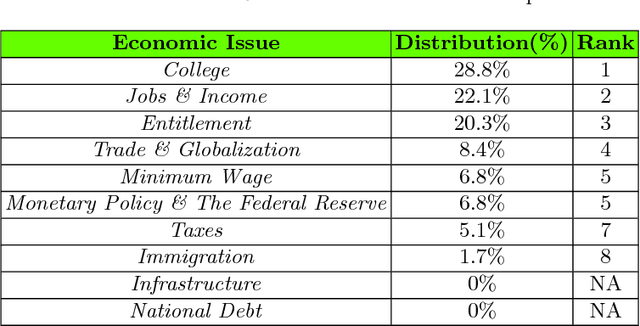
Popularity is a critical success factor for a politician and her/his party to win in elections and implement their plans. Finding the reasons behind the popularity can provide a stable political movement. This research attempts to measure popularity in Twitter using a mixed method. In recent years, Twitter data has provided an excellent opportunity for exploring public opinions by analyzing a large number of tweets. This study has collected and examined 4.5 million tweets related to a US politician, Senator Bernie Sanders. This study investigated eight economic reasons behind the senator's popularity in Twitter. This research has benefits for politicians, informatics experts, and policymakers to explore public opinion. The collected data will also be available for further investigation.