 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeteroSwitch: Characterizing and Taming System-Induced Data Heterogeneity in Federated Learning
Mar 07, 2024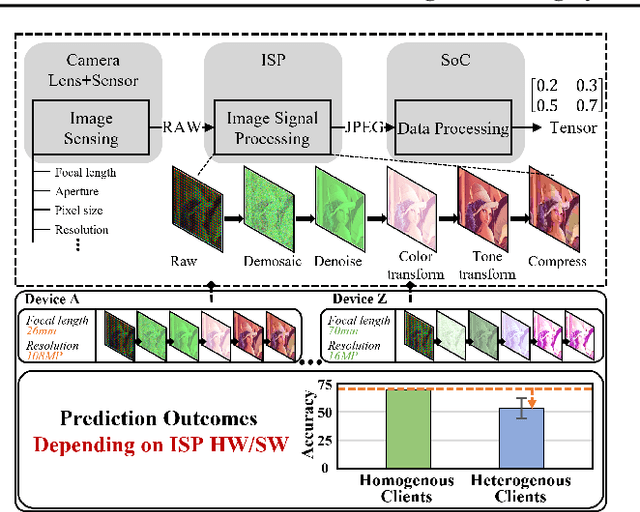

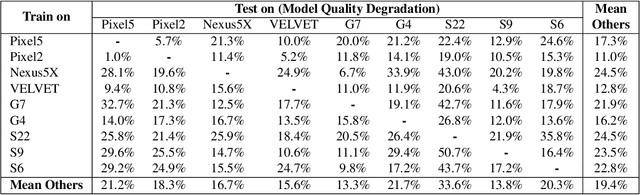
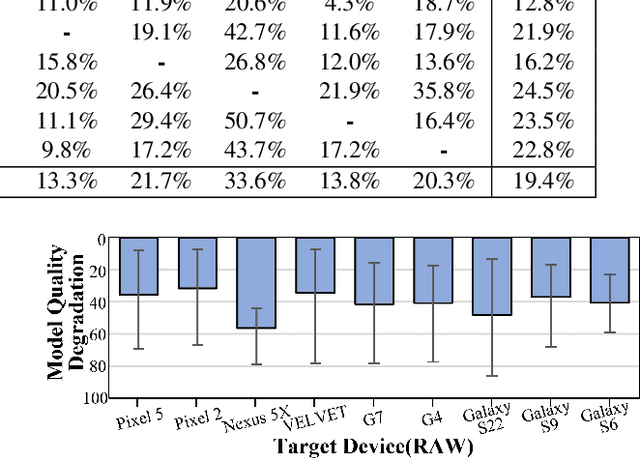
Federated Learning (FL) is a practical approach to train deep learning models collaboratively across user-end devices, protecting user privacy by retaining raw data on-device. In FL, participating user-end devices are highly fragmented in terms of hardware and software configurations. Such fragmentation introduces a new type of data heterogeneity in FL, namely \textit{system-induced data heterogeneity}, as each device generates distinct data depending on its hardware and software configurations. In this paper, we first characterize the impact of system-induced data heterogeneity on FL model performance. We collect a dataset using heterogeneous devices with variations across vendors and performance tiers. By using this dataset, we demonstrate that \textit{system-induced data heterogeneity} negatively impacts accuracy, and deteriorates fairness and domain generalization problems in FL. To address these challenges, we propose HeteroSwitch, which adaptively adopts generalization techniques (i.e., ISP transformation and SWAD) depending on the level of bias caused by varying HW and SW configurations. In our evaluation with a realistic FL dataset (FLAIR), HeteroSwitch reduces the variance of averaged precision by 6.3\% across device types.
Enabling Incremental Knowledge Transfer for Object Detection at the Edge
Apr 13, 2020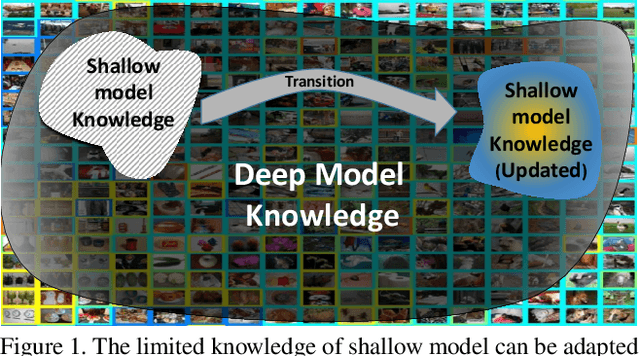
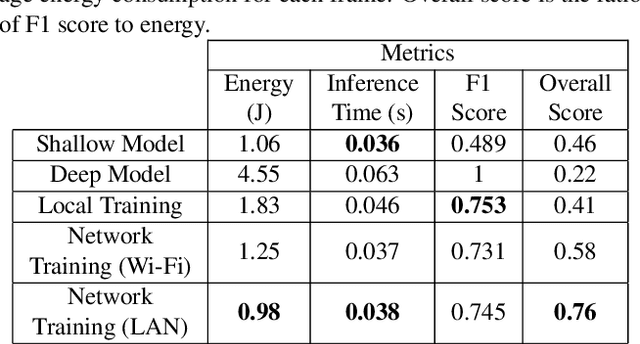
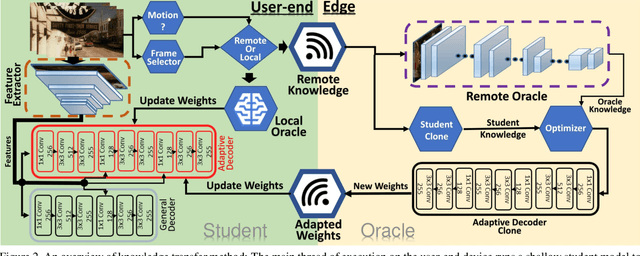

Object detection using deep neural networks (DNNs) involves a huge amount of computation which impedes its implementation on resource/energy-limited user-end devices. The reason for the success of DNNs is due to having knowledge over all different domains of observed environments. However, we need a limited knowledge of the observed environment at inference time which can be learned using a shallow neural network (SHNN). In this paper, a system-level design is proposed to improve the energy consumption of object detection on the user-end device. An SHNN is deployed on the user-end device to detect objects in the observing environment. Also, a knowledge transfer mechanism is implemented to update the SHNN model using the DNN knowledge when there is a change in the object domain. DNN knowledge can be obtained from a powerful edge device connected to the user-end device through LAN or Wi-Fi. Experiments demonstrate that the energy consumption of the user-end device and the inference time can be improved by 78% and 40% compared with running the deep model on the user-end device.
A Novel Design of Adaptive and Hierarchical Convolutional Neural Networks using Partial Reconfiguration on FPGA
Sep 05, 2019
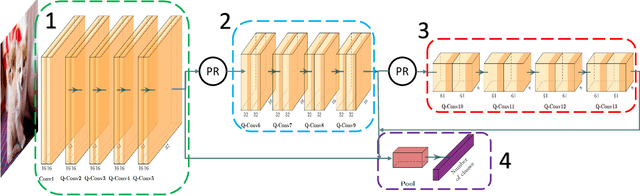
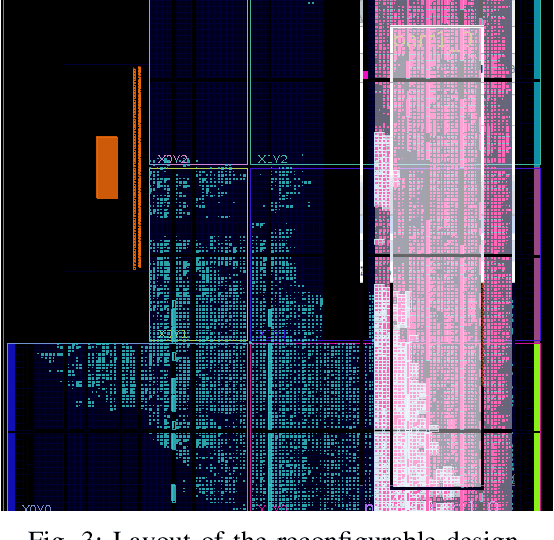
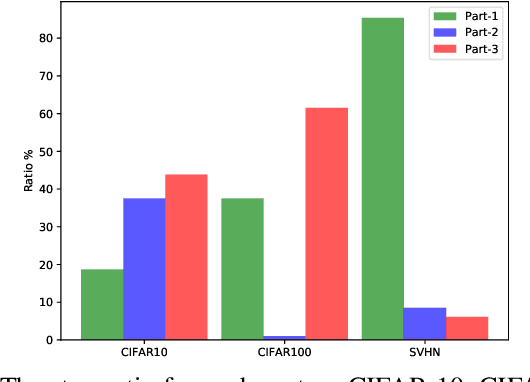
Nowadays most research in visual recognition using Convolutional Neural Networks (CNNs) follows the "deeper model with deeper confidence" belief to gain a higher recognition accuracy. At the same time, deeper model brings heavier computation. On the other hand, for a large chunk of recognition challenges, a system can classify images correctly using simple models or so-called shallow networks. Moreover, the implementation of CNNs faces with the size, weight, and energy constraints on the embedded devices. In this paper, we implement the adaptive switching between shallow and deep networks to reach the highest throughput on a resource-constrained MPSoC with CPU and FPGA. To this end, we develop and present a novel architecture for the CNNs where a gate makes the decision whether using the deeper model is beneficial or not. Due to resource limitation on FPGA, the idea of partial reconfiguration has been used to accommodate deep CNNs on the FPGA resources. We report experimental results on CIFAR-10, CIFAR-100, and SVHN datasets to validate our approach. Using confidence metric as the decision making factor, only 69.8%, 71.8%, and 43.8% of the computation in the deepest network is done for CIFAR-10, CIFAR-100, and SVHN while it can maintain the desired accuracy with the throughput of around 400 images per second for SVHN dataset.
Exploring Diseases and Syndromes in Neurology Case Reports from 1955 to 2017 with Text Mining
May 23, 2019
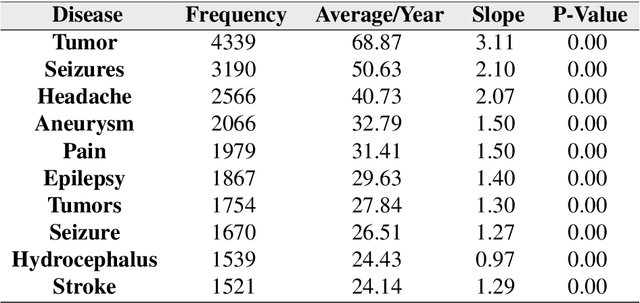
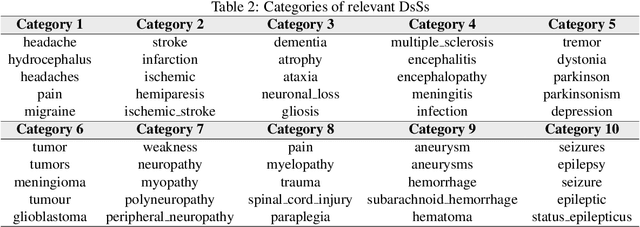
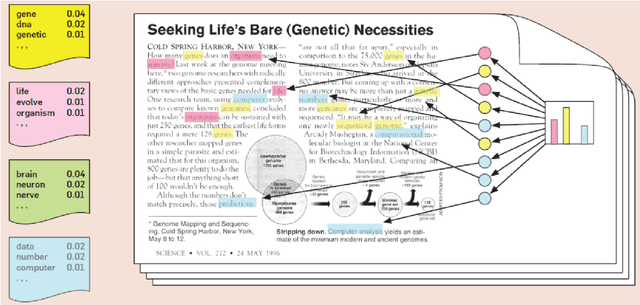
Background: A large number of neurology case reports have been published, but it is a challenging task for human medical experts to explore all of these publications. Text mining offers a computational approach to investigate neurology literature and capture meaningful patterns. The overarching goal of this study is to provide a new perspective on case reports of neurological disease and syndrome analysis over the last six decades using text mining. Methods: We extracted diseases and syndromes (DsSs) from more than 65,000 neurology case reports from 66 journals in PubMed over the last six decades from 1955 to 2017. Text mining was applied to reports on the detected DsSs to investigate high-frequency DsSs, categorize them, and explore the linear trends over the 63-year time frame. Results: The text mining methods explored high-frequency neurologic DsSs and their trends and the relationships between them from 1955 to 2017. We detected more than 18,000 unique DsSs and found 10 categories of neurologic DsSs. While the trend analysis showed the increasing trends in the case reports for top-10 high-frequency DsSs, the categories had mixed trends. Conclusion: Our study provided new insights into the application of text mining methods to investigate DsSs in a large number of medical case reports that occur over several decades. The proposed approach can be used to provide a macro level analysis of medical literature by discovering interesting patterns and tracking them over several years to help physicians explore these case reports more efficiently.
CryptoDL: Deep Neural Networks over Encrypted Data
Nov 14, 2017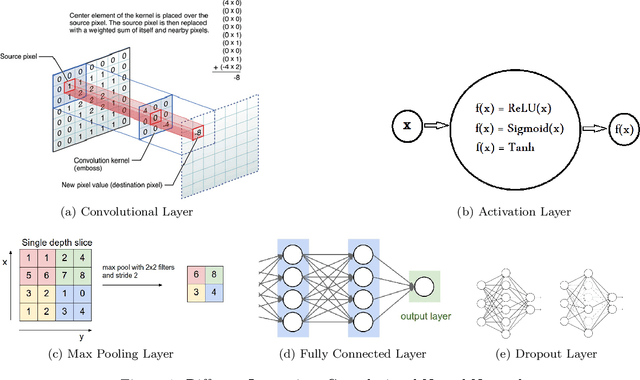
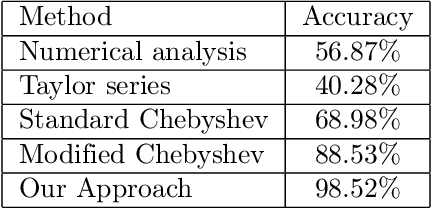
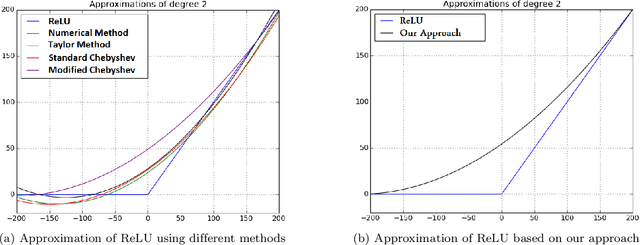

Machine learning algorithms based on deep neural networks have achieved remarkable results and are being extensively used in different domains. However, the machine learning algorithms requires access to raw data which is often privacy sensitive. To address this issue, we develop new techniques to provide solutions for running deep neural networks over encrypted data. In this paper, we develop new techniques to adopt deep neural networks within the practical limitation of current homomorphic encryption schemes. More specifically, we focus on classification of the well-known convolutional neural networks (CNN). First, we design methods for approximation of the activation functions commonly used in CNNs (i.e. ReLU, Sigmoid, and Tanh) with low degree polynomials which is essential for efficient homomorphic encryption schemes. Then, we train convolutional neural networks with the approximation polynomials instead of original activation functions and analyze the performance of the models. Finally, we implement convolutional neural networks over encrypted data and measure performance of the models. Our experimental results validate the soundness of our approach with several convolutional neural networks with varying number of layers and structures. When applied to the MNIST optical character recognition tasks, our approach achieves 99.52\% accuracy which significantly outperforms the state-of-the-art solutions and is very close to the accuracy of the best non-private version, 99.77\%. Also, it can make close to 164000 predictions per hour. We also applied our approach to CIFAR-10, which is much more complex compared to MNIST, and were able to achieve 91.5\% accuracy with approximation polynomials used as activation functions. These results show that CryptoDL provides efficient, accurate and scalable privacy-preserving predictions.