 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Fuzzy Clustering for Text Data Dimensionality Reduction
Paper and Code
Sep 21, 2019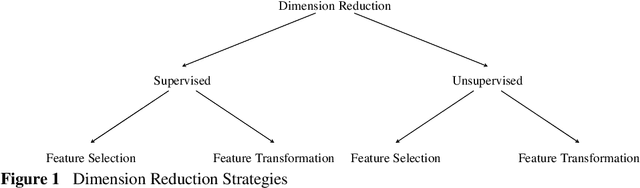


Large textual corpora are often represented by the document-term frequency matrix whose elements are the frequency of terms; however, this matrix has two problems: sparsity and high dimensionality. Four dimension reduction strategies are used to address these problems. Of the four strategies, unsupervised feature transformation (UFT) is a popular and efficient strategy to map the terms to a new basis in the document-term frequency matrix. Although several UFT-based methods have been developed, fuzzy clustering has not been considered for dimensionality reduction. This research explores fuzzy clustering as a new UFT-based approach to create a lower-dimensional representation of documents. Performance of fuzzy clustering with and without using global term weighting methods is shown to exceed principal component analysis and singular value decomposition. This study also explores the effect of applying different fuzzifier values on fuzzy clustering for dimensionality reduction purpose.