 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoBERT-LoRA: Parameter-Efficient Prototypical Finetuning for Immunotherapy Study Identification
Mar 26, 2025Identifying immune checkpoint inhibitor (ICI) studies in genomic repositories like Gene Expression Omnibus (GEO) is vital for cancer research yet remains challenging due to semantic ambiguity, extreme class imbalance, and limited labeled data in low-resource settings. We present ProtoBERT-LoRA, a hybrid framework that combines PubMedBERT with prototypical networks and Low-Rank Adaptation (LoRA) for efficient fine-tuning. The model enforces class-separable embeddings via episodic prototype training while preserving biomedical domain knowledge. Our dataset was divided as: Training (20 positive, 20 negative), Prototype Set (10 positive, 10 negative), Validation (20 positive, 200 negative), and Test (71 positive, 765 negative). Evaluated on test dataset, ProtoBERT-LoRA achieved F1-score of 0.624 (precision: 0.481, recall: 0.887), outperforming the rule-based system, machine learning baselines and finetuned PubMedBERT. Application to 44,287 unlabeled studies reduced manual review efforts by 82%. Ablation studies confirmed that combining prototypes with LoRA improved performance by 29% over stand-alone LoRA.
FLATM: A Fuzzy Logic Approach Topic Model for Medical Documents
Nov 25, 2019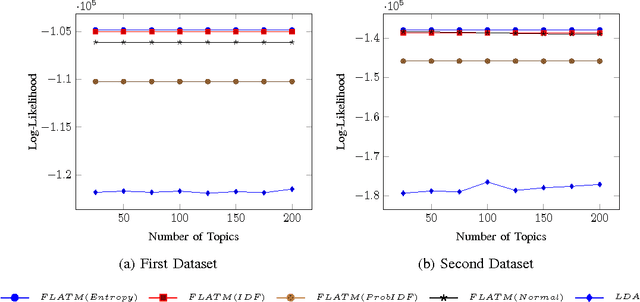
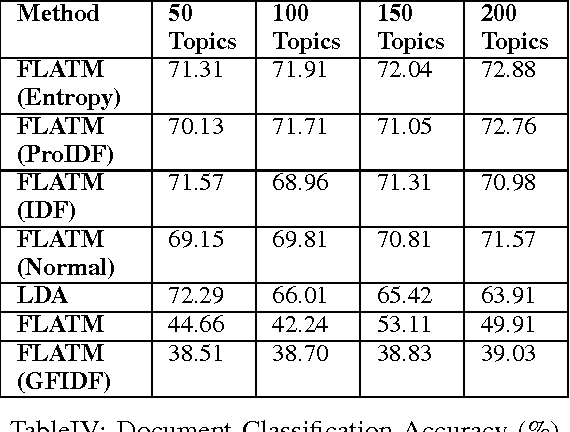
One of the challenges for text analysis in medical domains is analyzing large-scale medical documents. As a consequence, finding relevant documents has become more difficult. One of the popular methods to retrieve information based on discovering the themes in the documents is topic modeling. The themes in the documents help to retrieve documents on the same topic with and without a query. In this paper, we present a novel approach to topic modeling using fuzzy clustering. To evaluate our model, we experiment with two text datasets of medical documents. The evaluation metrics carried out through document classification and document modeling show that our model produces better performance than LDA, indicating that fuzzy set theory can improve the performance of topic models in medical domains.
Characterizing Diabetes, Diet, Exercise, and Obesity Comments on Twitter
Sep 22, 2017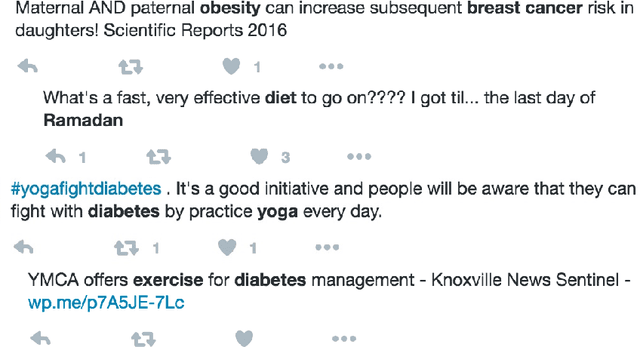

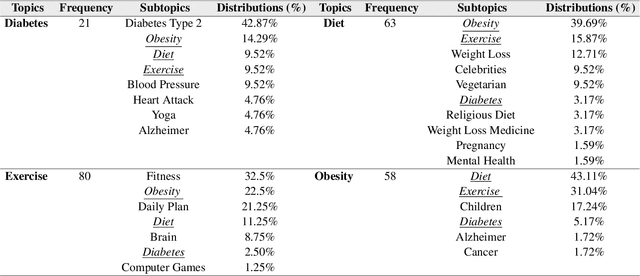
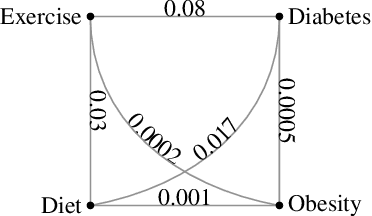
Social media provide a platform for users to express their opinions and share information. Understanding public health opinions on social media, such as Twitter, offers a unique approach to characterizing common health issues such as diabetes, diet, exercise, and obesity (DDEO), however, collecting and analyzing a large scale conversational public health data set is a challenging research task. The goal of this research is to analyze the characteristics of the general public's opinions in regard to diabetes, diet, exercise and obesity (DDEO) as expressed on Twitter. A multi-component semantic and linguistic framework was developed to collect Twitter data, discover topics of interest about DDEO, and analyze the topics. From the extracted 4.5 million tweets, 8% of tweets discussed diabetes, 23.7% diet, 16.6% exercise, and 51.7% obesity. The strongest correlation among the topics was determined between exercise and obesity. Other notable correlations were: diabetes and obesity, and diet and obesity DDEO terms were also identified as subtopics of each of the DDEO topics. The frequent subtopics discussed along with Diabetes, excluding the DDEO terms themselves, were blood pressure, heart attack, yoga, and Alzheimer. The non-DDEO subtopics for Diet included vegetarian, pregnancy, celebrities, weight loss, religious, and mental health, while subtopics for Exercise included computer games, brain, fitness, and daily plan. Non-DDEO subtopics for Obesity included Alzheimer, cancer, and children. With 2.67 billion social media users in 2016, publicly available data such as Twitter posts can be utilized to support clinical providers, public health experts, and social scientists in better understanding common public opinions in regard to diabetes, diet, exercise, and obesity.
Fuzzy Approach Topic Discovery in Health and Medical Corpora
May 26, 2017
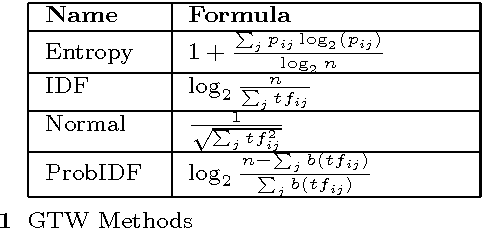
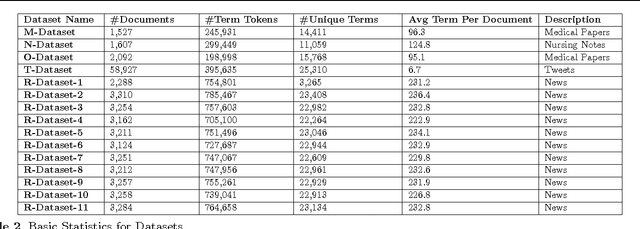

The majority of medical documents and electronic health records (EHRs) are in text format that poses a challenge for data processing and finding relevant documents. Looking for ways to automatically retrieve the enormous amount of health and medical knowledge has always been an intriguing topic. Powerful methods have been developed in recent years to make the text processing automatic. One of the popular approaches to retrieve information based on discovering the themes in health & medical corpora is topic modeling, however, this approach still needs new perspectives. In this research we describe fuzzy latent semantic analysis (FLSA), a novel approach in topic modeling using fuzzy perspective. FLSA can handle health & medical corpora redundancy issue and provides a new method to estimate the number of topics. The quantitative evaluations show that FLSA produces superior performance and features to latent Dirichlet allocation (LDA), the most popular topic model.