 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBABE: Biology Arena BEnchmark
Feb 05, 2026The rapid evolution of large language models (LLMs) has expanded their capabilities from basic dialogue to advanced scientific reasoning. However, existing benchmarks in biology often fail to assess a critical skill required of researchers: the ability to integrate experimental results with contextual knowledge to derive meaningful conclusions. To address this gap, we introduce BABE(Biology Arena BEnchmark), a comprehensive benchmark designed to evaluate the experimental reasoning capabilities of biological AI systems. BABE is uniquely constructed from peer-reviewed research papers and real-world biological studies, ensuring that tasks reflect the complexity and interdisciplinary nature of actual scientific inquiry. BABE challenges models to perform causal reasoning and cross-scale inference. Our benchmark provides a robust framework for assessing how well AI systems can reason like practicing scientists, offering a more authentic measure of their potential to contribute to biological research.
OMG-Agent: Toward Robust Missing Modality Generation with Decoupled Coarse-to-Fine Agentic Workflows
Feb 04, 2026Data incompleteness severely impedes the reliability of multimodal systems. Existing reconstruction methods face distinct bottlenecks: conventional parametric/generative models are prone to hallucinations due to over-reliance on internal memory, while retrieval-augmented frameworks struggle with retrieval rigidity. Critically, these end-to-end architectures are fundamentally constrained by Semantic-Detail Entanglement -- a structural conflict between logical reasoning and signal synthesis that compromises fidelity. In this paper, we present \textbf{\underline{O}}mni-\textbf{\underline{M}}odality \textbf{\underline{G}}eneration Agent (\textbf{OMG-Agent}), a novel framework that shifts the paradigm from static mapping to a dynamic coarse-to-fine Agentic Workflow. By mimicking a \textit{deliberate-then-act} cognitive process, OMG-Agent explicitly decouples the task into three synergistic stages: (1) an MLLM-driven Semantic Planner that resolves input ambiguity via Progressive Contextual Reasoning, creating a deterministic structured semantic plan; (2) a non-parametric Evidence Retriever that grounds abstract semantics in external knowledge; and (3) a Retrieval-Injected Executor that utilizes retrieved evidence as flexible feature prompts to overcome rigidity and synthesize high-fidelity details. Extensive experiments on multiple benchmarks demonstrate that OMG-Agent consistently surpasses state-of-the-art methods, maintaining robustness under extreme missingness, e.g., a $2.6$-point gain on CMU-MOSI at $70$\% missing rates.
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?
Apr 01, 2025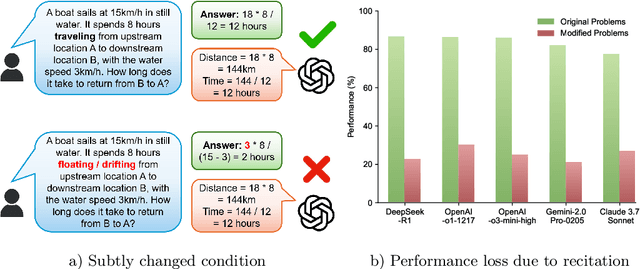
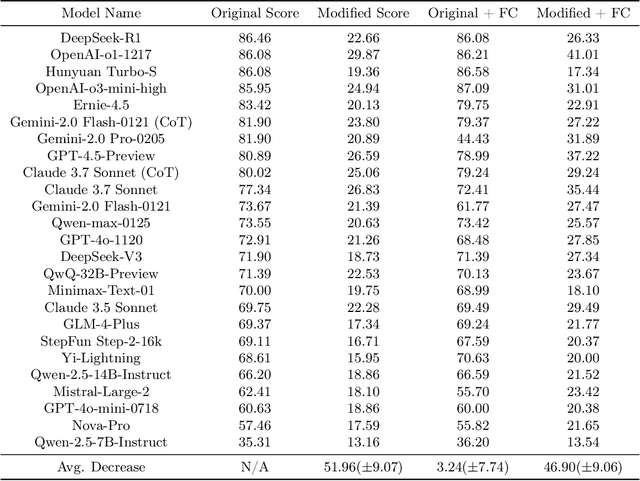

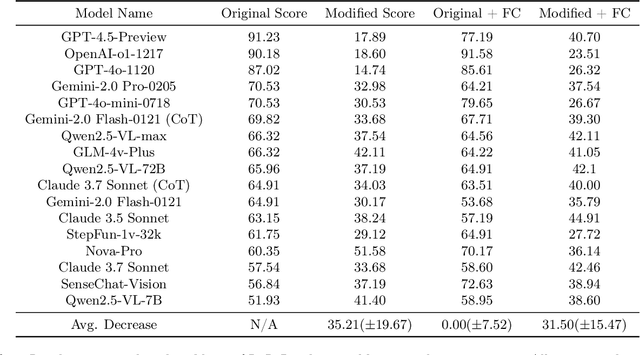
The rapid escalation from elementary school-level to frontier problems of the difficulty for LLM benchmarks in recent years have weaved a miracle for researchers that we are only inches away from surpassing human intelligence. However, is the LLMs' remarkable reasoning ability indeed comes from true intelligence by human standards, or are they simply reciting solutions witnessed during training at an Internet level? To study this problem, we propose RoR-Bench, a novel, multi-modal benchmark for detecting LLM's recitation behavior when asked simple reasoning problems but with conditions subtly shifted, and conduct empirical analysis on our benchmark. Surprisingly, we found existing cutting-edge LLMs unanimously exhibits extremely severe recitation behavior; by changing one phrase in the condition, top models such as OpenAI-o1 and DeepSeek-R1 can suffer $60\%$ performance loss on elementary school-level arithmetic and reasoning problems. Such findings are a wake-up call to the LLM community that compels us to re-evaluate the true intelligence level of cutting-edge LLMs.
ProtoBERT-LoRA: Parameter-Efficient Prototypical Finetuning for Immunotherapy Study Identification
Mar 26, 2025Identifying immune checkpoint inhibitor (ICI) studies in genomic repositories like Gene Expression Omnibus (GEO) is vital for cancer research yet remains challenging due to semantic ambiguity, extreme class imbalance, and limited labeled data in low-resource settings. We present ProtoBERT-LoRA, a hybrid framework that combines PubMedBERT with prototypical networks and Low-Rank Adaptation (LoRA) for efficient fine-tuning. The model enforces class-separable embeddings via episodic prototype training while preserving biomedical domain knowledge. Our dataset was divided as: Training (20 positive, 20 negative), Prototype Set (10 positive, 10 negative), Validation (20 positive, 200 negative), and Test (71 positive, 765 negative). Evaluated on test dataset, ProtoBERT-LoRA achieved F1-score of 0.624 (precision: 0.481, recall: 0.887), outperforming the rule-based system, machine learning baselines and finetuned PubMedBERT. Application to 44,287 unlabeled studies reduced manual review efforts by 82%. Ablation studies confirmed that combining prototypes with LoRA improved performance by 29% over stand-alone LoRA.
Mamba-VA: A Mamba-based Approach for Continuous Emotion Recognition in Valence-Arousal Space
Mar 13, 2025Continuous Emotion Recognition (CER) plays a crucial role in intelligent human-computer interaction, mental health monitoring, and autonomous driving. Emotion modeling based on the Valence-Arousal (VA) space enables a more nuanced representation of emotional states. However, existing methods still face challenges in handling long-term dependencies and capturing complex temporal dynamics. To address these issues, this paper proposes a novel emotion recognition model, Mamba-VA, which leverages the Mamba architecture to efficiently model sequential emotional variations in video frames. First, the model employs a Masked Autoencoder (MAE) to extract deep visual features from video frames, enhancing the robustness of temporal information. Then, a Temporal Convolutional Network (TCN) is utilized for temporal modeling to capture local temporal dependencies. Subsequently, Mamba is applied for long-sequence modeling, enabling the learning of global emotional trends. Finally, a fully connected (FC) layer performs regression analysis to predict continuous valence and arousal values. Experimental results on the Valence-Arousal (VA) Estimation task of the 8th competition on Affective Behavior Analysis in-the-wild (ABAW) demonstrate that the proposed model achieves valence and arousal scores of 0.5362 (0.5036) and 0.4310 (0.4119) on the validation (test) set, respectively, outperforming the baseline. The source code is available on GitHub:https://github.com/FreedomPuppy77/Charon.