 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Local Independence Testing with Application to Dynamic Causal Discovery
Jun 09, 2025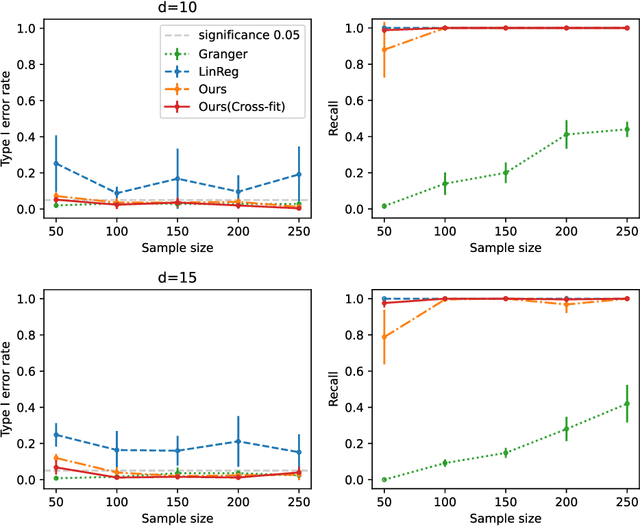
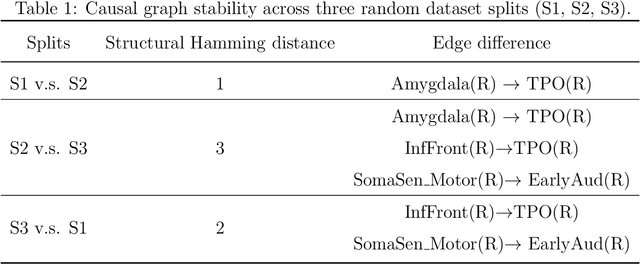
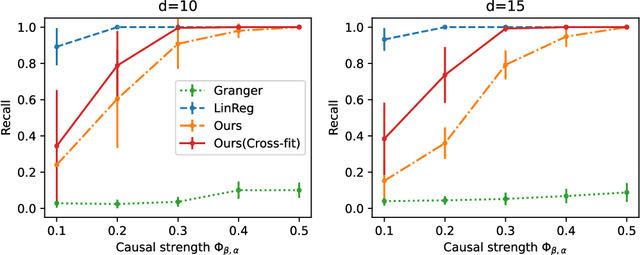
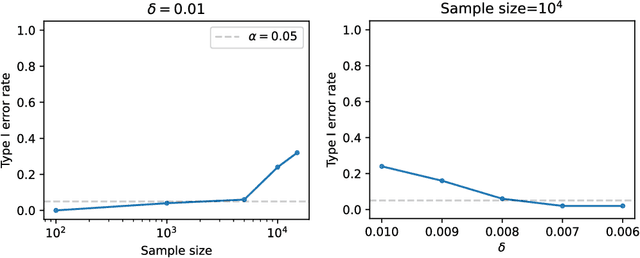
In this note, we extend the conditional local independence testing theory developed in Christgau et al. (2024) to Ito processes. The result can be applied to causal discovery in dynamic systems.
Mamba-VA: A Mamba-based Approach for Continuous Emotion Recognition in Valence-Arousal Space
Mar 13, 2025Continuous Emotion Recognition (CER) plays a crucial role in intelligent human-computer interaction, mental health monitoring, and autonomous driving. Emotion modeling based on the Valence-Arousal (VA) space enables a more nuanced representation of emotional states. However, existing methods still face challenges in handling long-term dependencies and capturing complex temporal dynamics. To address these issues, this paper proposes a novel emotion recognition model, Mamba-VA, which leverages the Mamba architecture to efficiently model sequential emotional variations in video frames. First, the model employs a Masked Autoencoder (MAE) to extract deep visual features from video frames, enhancing the robustness of temporal information. Then, a Temporal Convolutional Network (TCN) is utilized for temporal modeling to capture local temporal dependencies. Subsequently, Mamba is applied for long-sequence modeling, enabling the learning of global emotional trends. Finally, a fully connected (FC) layer performs regression analysis to predict continuous valence and arousal values. Experimental results on the Valence-Arousal (VA) Estimation task of the 8th competition on Affective Behavior Analysis in-the-wild (ABAW) demonstrate that the proposed model achieves valence and arousal scores of 0.5362 (0.5036) and 0.4310 (0.4119) on the validation (test) set, respectively, outperforming the baseline. The source code is available on GitHub:https://github.com/FreedomPuppy77/Charon.
Bayesian Intervention Optimization for Causal Discovery
Jun 16, 2024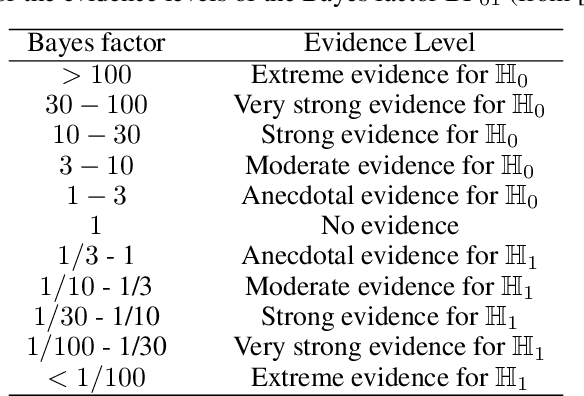
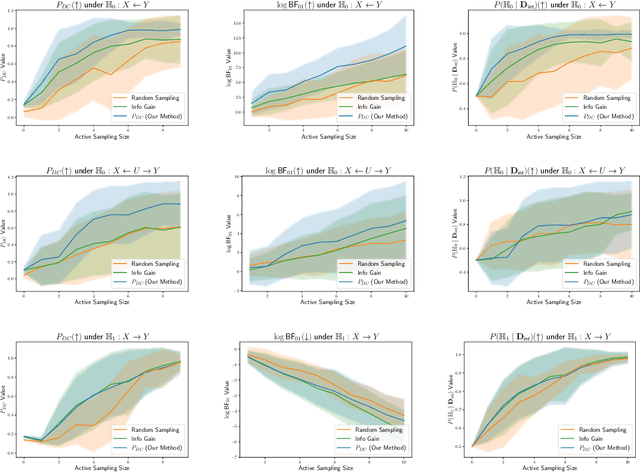
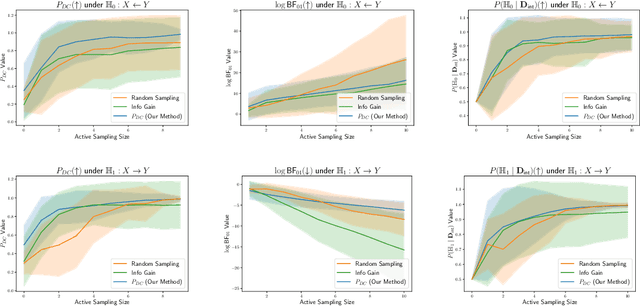
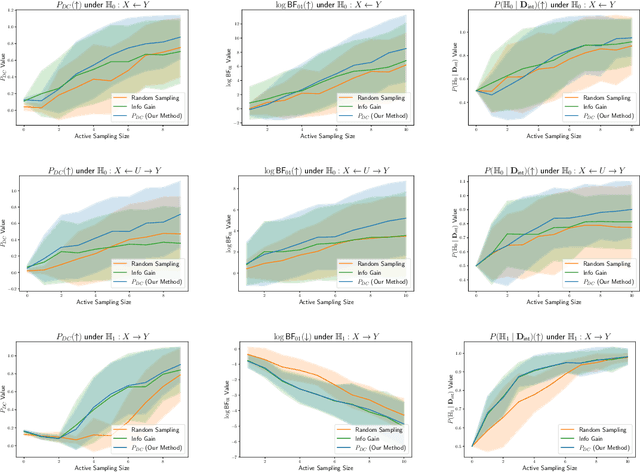
Causal discovery is crucial for understanding complex systems and informing decisions. While observational data can uncover causal relationships under certain assumptions, it often falls short, making active interventions necessary. Current methods, such as Bayesian and graph-theoretical approaches, do not prioritize decision-making and often rely on ideal conditions or information gain, which is not directly related to hypothesis testing. We propose a novel Bayesian optimization-based method inspired by Bayes factors that aims to maximize the probability of obtaining decisive and correct evidence. Our approach uses observational data to estimate causal models under different hypotheses, evaluates potential interventions pre-experimentally, and iteratively updates priors to refine interventions. We demonstrate the effectiveness of our method through various experiments. Our contributions provide a robust framework for efficient causal discovery through active interventions, enhancing the practical application of theoretical advancements.
The Blessings of Multiple Treatments and Outcomes in Treatment Effect Estimation
Oct 14, 2023



Assessing causal effects in the presence of unobserved confounding is a challenging problem. Existing studies leveraged proxy variables or multiple treatments to adjust for the confounding bias. In particular, the latter approach attributes the impact on a single outcome to multiple treatments, allowing estimating latent variables for confounding control. Nevertheless, these methods primarily focus on a single outcome, whereas in many real-world scenarios, there is greater interest in studying the effects on multiple outcomes. Besides, these outcomes are often coupled with multiple treatments. Examples include the intensive care unit (ICU), where health providers evaluate the effectiveness of therapies on multiple health indicators. To accommodate these scenarios, we consider a new setting dubbed as multiple treatments and multiple outcomes. We then show that parallel studies of multiple outcomes involved in this setting can assist each other in causal identification, in the sense that we can exploit other treatments and outcomes as proxies for each treatment effect under study. We proceed with a causal discovery method that can effectively identify such proxies for causal estimation. The utility of our method is demonstrated in synthetic data and sepsis disease.
Exploring Counterfactual Alignment Loss towards Human-centered AI
Oct 03, 2023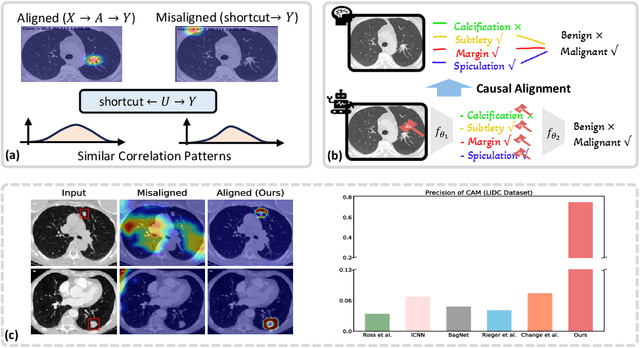
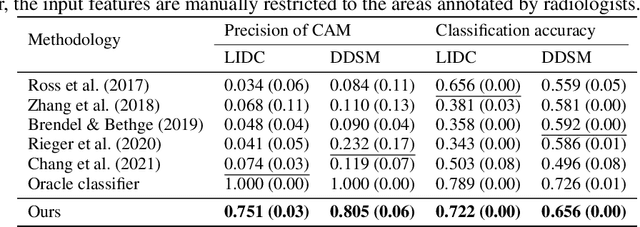
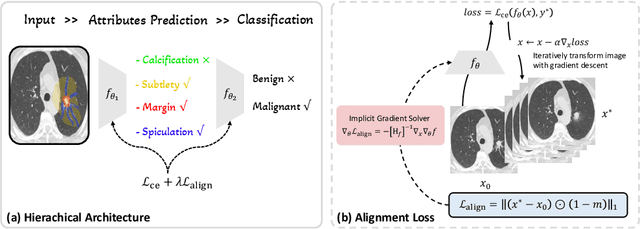

Deep neural networks have demonstrated impressive accuracy in supervised learning tasks. However, their lack of transparency makes it hard for humans to trust their results, especially in safe-critic domains such as healthcare. To address this issue, recent explanation-guided learning approaches proposed to align the gradient-based attention map to image regions annotated by human experts, thereby obtaining an intrinsically human-centered model. However, the attention map these methods are based on may fail to causally attribute the model predictions, thus compromising their validity for alignment. To address this issue, we propose a novel human-centered framework based on counterfactual generation. In particular, we utilize the counterfactual generation's ability for causal attribution to introduce a novel loss called the CounterFactual Alignment (CF-Align) loss. This loss guarantees that the features attributed by the counterfactual generation for the classifier align with the human annotations. To optimize the proposed loss that entails a counterfactual generation with an implicit function form, we leverage the implicit function theorem for backpropagation. Our method is architecture-agnostic and, therefore can be applied to any neural network. We demonstrate the effectiveness of our method on a lung cancer diagnosis dataset, showcasing faithful alignment to humans.
Causal Discovery from Subsampled Time Series with Proxy Variables
May 24, 2023

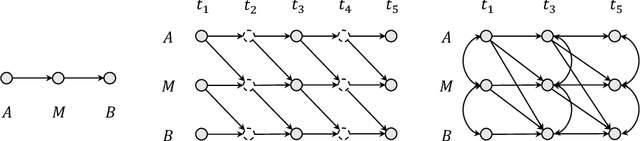

Inferring causal structures from time series data is the central interest of many scientific inquiries. A major barrier to such inference is the problem of subsampling, i.e., the frequency of measurement is much lower than that of causal influence. To overcome this problem, numerous methods have been proposed, yet either was limited to the linear case or failed to achieve identifiability. In this paper, we propose a constraint-based algorithm that can identify the entire causal structure from subsampled time series, without any parametric constraint. Our observation is that the challenge of subsampling arises mainly from hidden variables at the unobserved time steps. Meanwhile, every hidden variable has an observed proxy, which is essentially itself at some observable time in the future, benefiting from the temporal structure. Based on these, we can leverage the proxies to remove the bias induced by the hidden variables and hence achieve identifiability. Following this intuition, we propose a proxy-based causal discovery algorithm. Our algorithm is nonparametric and can achieve full causal identification. Theoretical advantages are reflected in synthetic and real-world experiments.
Causal Discovery with Unobserved Variables: A Proxy Variable Approach
May 24, 2023



Discovering causal relations from observational data is important. The existence of unobserved variables, such as latent confounders or mediators, can mislead the causal identification. To address this issue, proximal causal discovery methods proposed to adjust for the bias with the proxy of the unobserved variable. However, these methods presumed the data is discrete, which limits their real-world application. In this paper, we propose a proximal causal discovery method that can well handle the continuous variables. Our observation is that discretizing continuous variables can can lead to serious errors and comprise the power of the proxy. Therefore, to use proxy variables in the continuous case, the critical point is to control the discretization error. To this end, we identify mild regularity conditions on the conditional distributions, enabling us to control the discretization error to an infinitesimal level, as long as the proxy is discretized with sufficiently fine, finite bins. Based on this, we design a proxy-based hypothesis test for identifying causal relationships when unobserved variables are present. Our test is consistent, meaning it has ideal power when large samples are available. We demonstrate the effectiveness of our method using synthetic and real-world data.
Context-LGM: Leveraging Object-Context Relation for Context-Aware Object Recognition
Oct 08, 2021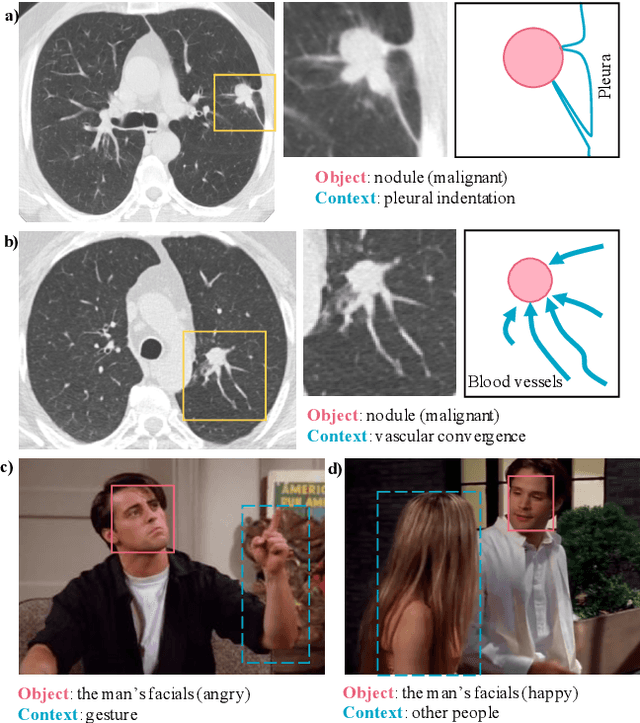
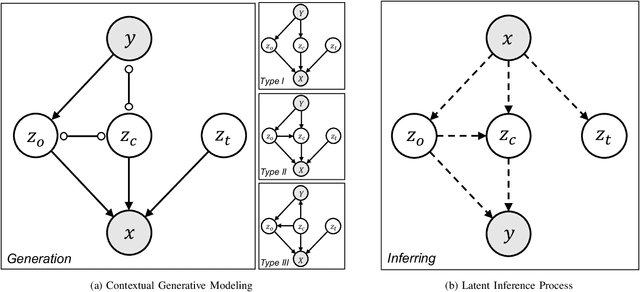
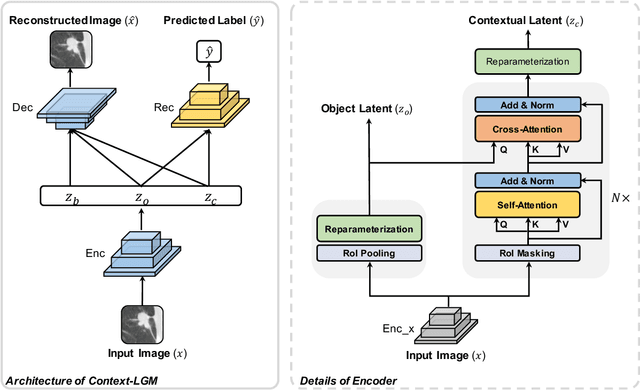
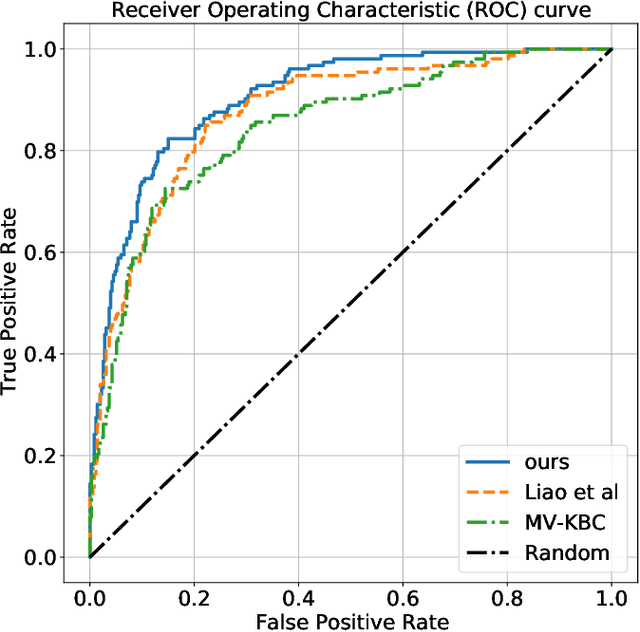
Context, as referred to situational factors related to the object of interest, can help infer the object's states or properties in visual recognition. As such contextual features are too diverse (across instances) to be annotated, existing attempts simply exploit image labels as supervision to learn them, resulting in various contextual tricks, such as features pyramid, context attention, etc. However, without carefully modeling the context's properties, especially its relation to the object, their estimated context can suffer from large inaccuracy. To amend this problem, we propose a novel Contextual Latent Generative Model (Context-LGM), which considers the object-context relation and models it in a hierarchical manner. Specifically, we firstly introduce a latent generative model with a pair of correlated latent variables to respectively model the object and context, and embed their correlation via the generative process. Then, to infer contextual features, we reformulate the objective function of Variational Auto-Encoder (VAE), where contextual features are learned as a posterior distribution conditioned on the object. Finally, to implement this contextual posterior, we introduce a Transformer that takes the object's information as a reference and locates correlated contextual factors. The effectiveness of our method is verified by state-of-the-art performance on two context-aware object recognition tasks, i.e. lung cancer prediction and emotion recognition.