 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery from Subsampled Time Series with Proxy Variables
May 24, 2023

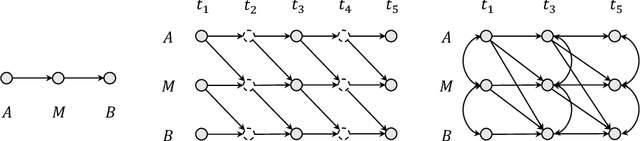

Inferring causal structures from time series data is the central interest of many scientific inquiries. A major barrier to such inference is the problem of subsampling, i.e., the frequency of measurement is much lower than that of causal influence. To overcome this problem, numerous methods have been proposed, yet either was limited to the linear case or failed to achieve identifiability. In this paper, we propose a constraint-based algorithm that can identify the entire causal structure from subsampled time series, without any parametric constraint. Our observation is that the challenge of subsampling arises mainly from hidden variables at the unobserved time steps. Meanwhile, every hidden variable has an observed proxy, which is essentially itself at some observable time in the future, benefiting from the temporal structure. Based on these, we can leverage the proxies to remove the bias induced by the hidden variables and hence achieve identifiability. Following this intuition, we propose a proxy-based causal discovery algorithm. Our algorithm is nonparametric and can achieve full causal identification. Theoretical advantages are reflected in synthetic and real-world experiments.
Leveraging both Lesion Features and Procedural Bias in Neuroimaging: An Dual-Task Split dynamics of inverse scale space
Jul 17, 2020
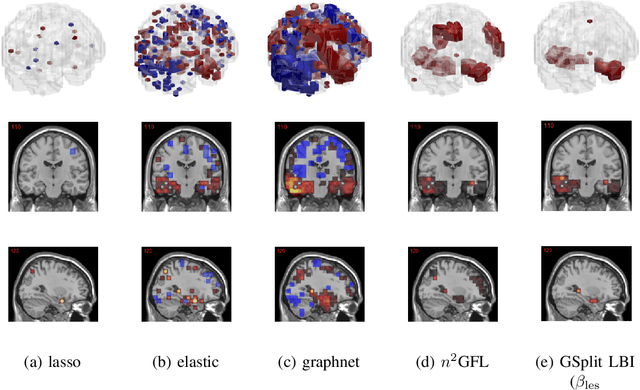

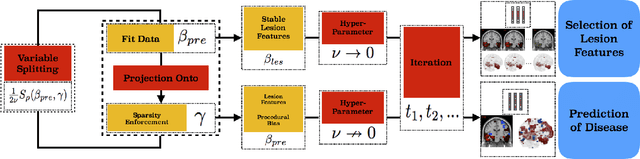
The prediction and selection of lesion features are two important tasks in voxel-based neuroimage analysis. Existing multivariate learning models take two tasks equivalently and optimize simultaneously. However, in addition to lesion features, we observe that there is another type of feature, which is commonly introduced during the procedure of preprocessing steps, which can improve the prediction result. We call such a type of feature as procedural bias. Therefore, in this paper, we propose that the features/voxels in neuroimage data are consist of three orthogonal parts: lesion features, procedural bias, and null features. To stably select lesion features and leverage procedural bias into prediction, we propose an iterative algorithm (termed GSplit LBI) as a discretization of differential inclusion of inverse scale space, which is the combination of Variable Splitting scheme and Linearized Bregman Iteration (LBI). Specifically, with a variable the splitting term, two estimators are introduced and split apart, i.e. one is for feature selection (the sparse estimator) and the other is for prediction (the dense estimator). Implemented with Linearized Bregman Iteration (LBI), the solution path of both estimators can be returned with different sparsity levels on the sparse estimator for the selection of lesion features. Besides, the dense the estimator can additionally leverage procedural bias to further improve prediction results. To test the efficacy of our method, we conduct experiments on the simulated study and Alzheimer's Disease Neuroimaging Initiative (ADNI) database. The validity and the benefit of our model can be shown by the improvement of prediction results and the interpretability of visualized procedural bias and lesion features.
TCGM: An Information-Theoretic Framework for Semi-Supervised Multi-Modality Learning
Jul 14, 2020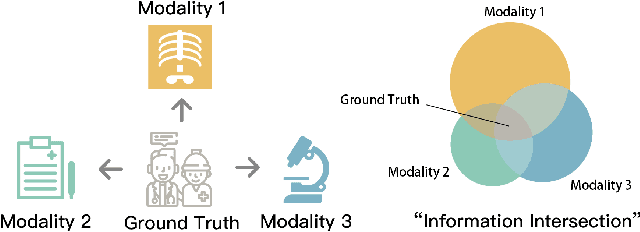
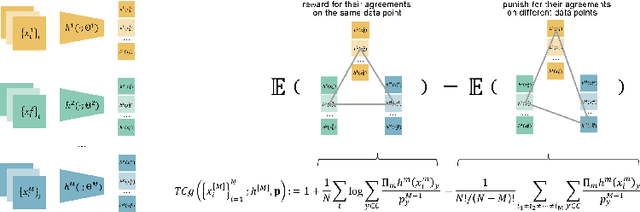
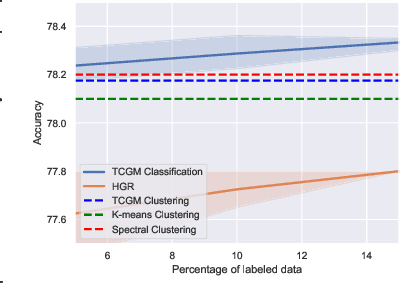
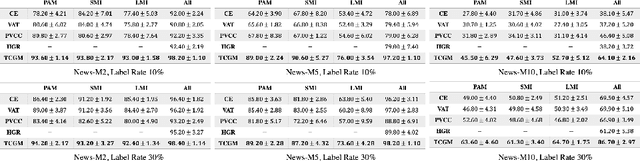
Fusing data from multiple modalities provides more information to train machine learning systems. However, it is prohibitively expensive and time-consuming to label each modality with a large amount of data, which leads to a crucial problem of semi-supervised multi-modal learning. Existing methods suffer from either ineffective fusion across modalities or lack of theoretical guarantees under proper assumptions. In this paper, we propose a novel information-theoretic approach, namely \textbf{T}otal \textbf{C}orrelation \textbf{G}ain \textbf{M}aximization (TCGM), for semi-supervised multi-modal learning, which is endowed with promising properties: (i) it can utilize effectively the information across different modalities of unlabeled data points to facilitate training classifiers of each modality (ii) it has theoretical guarantee to identify Bayesian classifiers, i.e., the ground truth posteriors of all modalities. Specifically, by maximizing TC-induced loss (namely TC gain) over classifiers of all modalities, these classifiers can cooperatively discover the equivalent class of ground-truth classifiers; and identify the unique ones by leveraging limited percentage of labeled data. We apply our method to various tasks and achieve state-of-the-art results, including news classification, emotion recognition and disease prediction.
Stable Feature Selection from Brain sMRI
Mar 25, 2015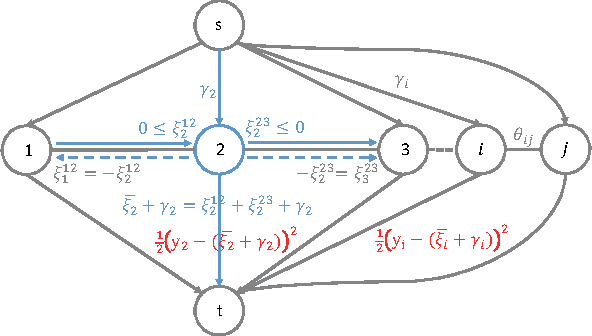
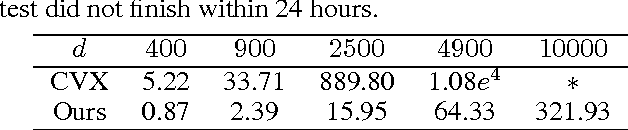
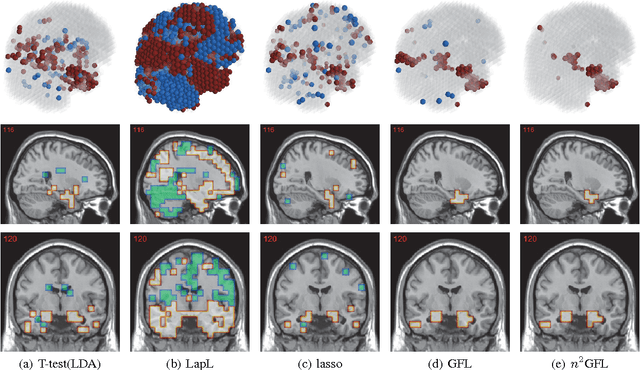
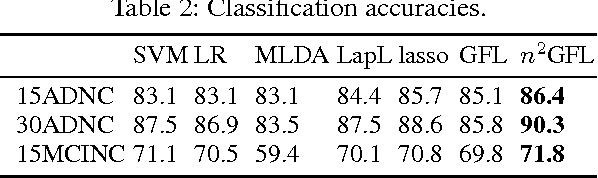
Neuroimage analysis usually involves learning thousands or even millions of variables using only a limited number of samples. In this regard, sparse models, e.g. the lasso, are applied to select the optimal features and achieve high diagnosis accuracy. The lasso, however, usually results in independent unstable features. Stability, a manifest of reproducibility of statistical results subject to reasonable perturbations to data and the model, is an important focus in statistics, especially in the analysis of high dimensional data. In this paper, we explore a nonnegative generalized fused lasso model for stable feature selection in the diagnosis of Alzheimer's disease. In addition to sparsity, our model incorporates two important pathological priors: the spatial cohesion of lesion voxels and the positive correlation between the features and the disease labels. To optimize the model, we propose an efficient algorithm by proving a novel link between total variation and fast network flow algorithms via conic duality. Experiments show that the proposed nonnegative model performs much better in exploring the intrinsic structure of data via selecting stable features compared with other state-of-the-arts.