 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022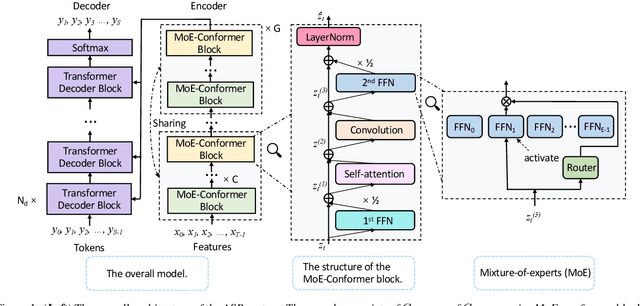
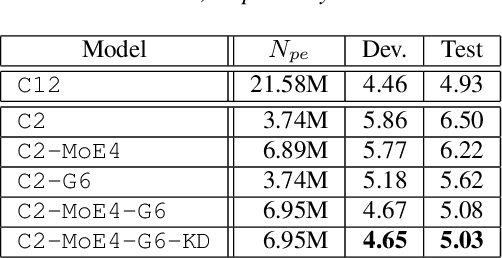

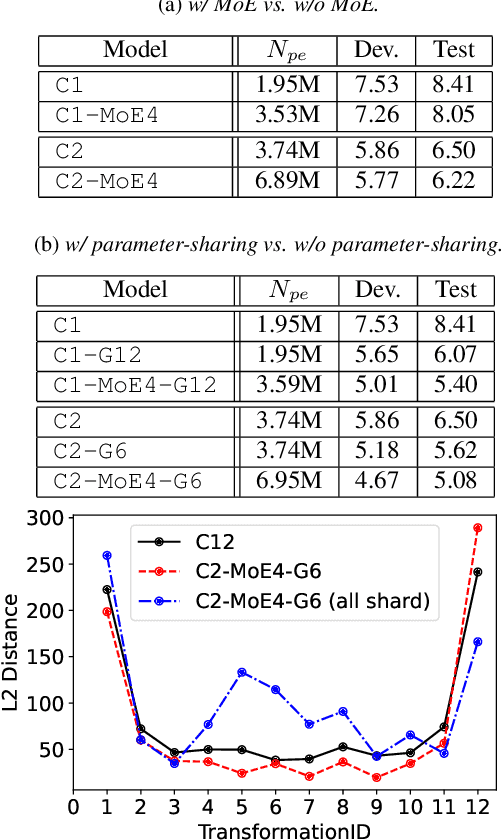
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.
CPED: A Large-Scale Chinese Personalized and Emotional Dialogue Dataset for Conversational AI
May 29, 2022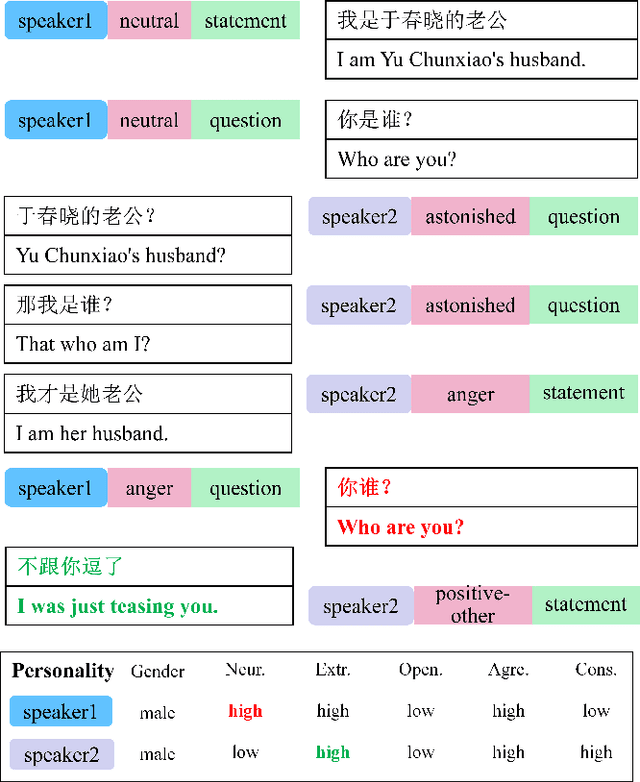

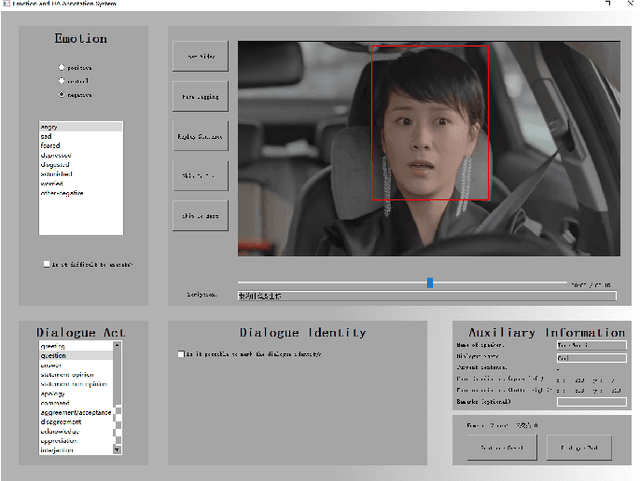
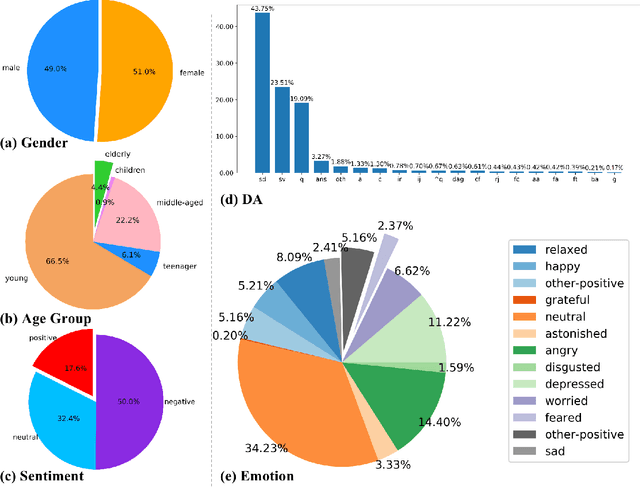
Human language expression is based on the subjective construal of the situation instead of the objective truth conditions, which means that speakers' personalities and emotions after cognitive processing have an important influence on conversation. However, most existing datasets for conversational AI ignore human personalities and emotions, or only consider part of them. It's difficult for dialogue systems to understand speakers' personalities and emotions although large-scale pre-training language models have been widely used. In order to consider both personalities and emotions in the process of conversation generation, we propose CPED, a large-scale Chinese personalized and emotional dialogue dataset, which consists of multi-source knowledge related to empathy and personal characteristic. These knowledge covers gender, Big Five personality traits, 13 emotions, 19 dialogue acts and 10 scenes. CPED contains more than 12K dialogues of 392 speakers from 40 TV shows. We release the textual dataset with audio features and video features according to the copyright claims, privacy issues, terms of service of video platforms. We provide detailed description of the CPED construction process and introduce three tasks for conversational AI, including personality recognition, emotion recognition in conversations as well as personalized and emotional conversation generation. Finally, we provide baseline systems for these tasks and consider the function of speakers' personalities and emotions on conversation. Our motivation is to propose a dataset to be widely adopted by the NLP community as a new open benchmark for conversational AI research. The full dataset is available at https://github.com/scutcyr/CPED.
Leveraging both Lesion Features and Procedural Bias in Neuroimaging: An Dual-Task Split dynamics of inverse scale space
Jul 17, 2020
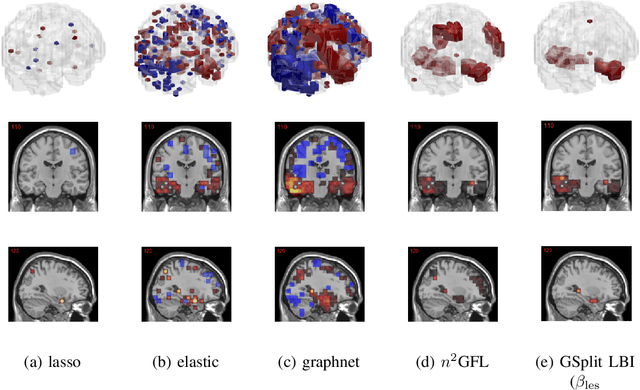

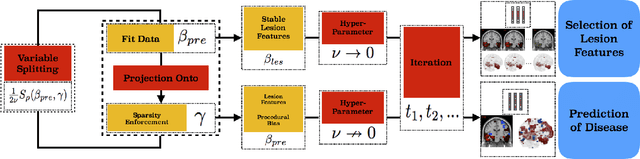
The prediction and selection of lesion features are two important tasks in voxel-based neuroimage analysis. Existing multivariate learning models take two tasks equivalently and optimize simultaneously. However, in addition to lesion features, we observe that there is another type of feature, which is commonly introduced during the procedure of preprocessing steps, which can improve the prediction result. We call such a type of feature as procedural bias. Therefore, in this paper, we propose that the features/voxels in neuroimage data are consist of three orthogonal parts: lesion features, procedural bias, and null features. To stably select lesion features and leverage procedural bias into prediction, we propose an iterative algorithm (termed GSplit LBI) as a discretization of differential inclusion of inverse scale space, which is the combination of Variable Splitting scheme and Linearized Bregman Iteration (LBI). Specifically, with a variable the splitting term, two estimators are introduced and split apart, i.e. one is for feature selection (the sparse estimator) and the other is for prediction (the dense estimator). Implemented with Linearized Bregman Iteration (LBI), the solution path of both estimators can be returned with different sparsity levels on the sparse estimator for the selection of lesion features. Besides, the dense the estimator can additionally leverage procedural bias to further improve prediction results. To test the efficacy of our method, we conduct experiments on the simulated study and Alzheimer's Disease Neuroimaging Initiative (ADNI) database. The validity and the benefit of our model can be shown by the improvement of prediction results and the interpretability of visualized procedural bias and lesion features.