 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAD-R1: Eliciting Consistent Reasoning in Interpretible Medical Anomaly Detection via Consistency-Reinforced Policy Optimization
Feb 01, 2026Medical Anomaly Detection (MedAD) presents a significant opportunity to enhance diagnostic accuracy using Large Multimodal Models (LMMs) to interpret and answer questions based on medical images. However, the reliance on Supervised Fine-Tuning (SFT) on simplistic and fragmented datasets has hindered the development of models capable of plausible reasoning and robust multimodal generalization. To overcome this, we introduce MedAD-38K, the first large-scale, multi-modal, and multi-center benchmark for MedAD featuring diagnostic Chain-of-Thought (CoT) annotations alongside structured Visual Question-Answering (VQA) pairs. On this foundation, we propose a two-stage training framework. The first stage, Cognitive Injection, uses SFT to instill foundational medical knowledge and align the model with a structured think-then-answer paradigm. Given that standard policy optimization can produce reasoning that is disconnected from the final answer, the second stage incorporates Consistency Group Relative Policy Optimization (Con-GRPO). This novel algorithm incorporates a crucial consistency reward to ensure the generated reasoning process is relevant and logically coherent with the final diagnosis. Our proposed model, MedAD-R1, achieves state-of-the-art (SOTA) performance on the MedAD-38K benchmark, outperforming strong baselines by more than 10\%. This superior performance stems from its ability to generate transparent and logically consistent reasoning pathways, offering a promising approach to enhancing the trustworthiness and interpretability of AI for clinical decision support.
EpiPlanAgent: Agentic Automated Epidemic Response Planning
Dec 12, 2025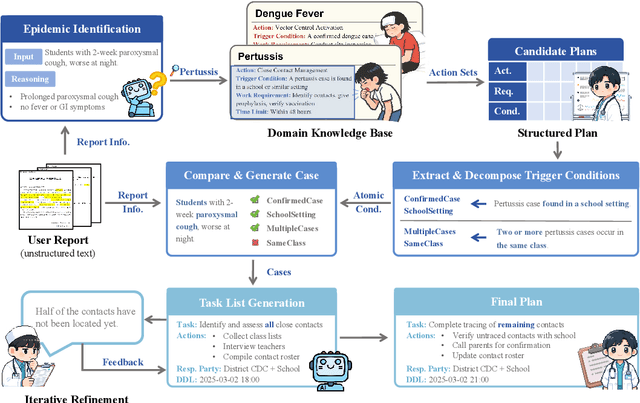

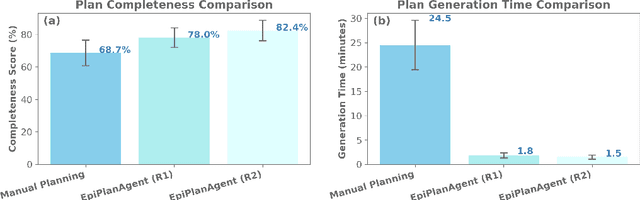

Epidemic response planning is essential yet traditionally reliant on labor-intensive manual methods. This study aimed to design and evaluate EpiPlanAgent, an agent-based system using large language models (LLMs) to automate the generation and validation of digital emergency response plans. The multi-agent framework integrated task decomposition, knowledge grounding, and simulation modules. Public health professionals tested the system using real-world outbreak scenarios in a controlled evaluation. Results demonstrated that EpiPlanAgent significantly improved the completeness and guideline alignment of plans while drastically reducing development time compared to manual workflows. Expert evaluation confirmed high consistency between AI-generated and human-authored content. User feedback indicated strong perceived utility. In conclusion, EpiPlanAgent provides an effective, scalable solution for intelligent epidemic response planning, demonstrating the potential of agentic AI to transform public health preparedness.
Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
Nov 09, 2025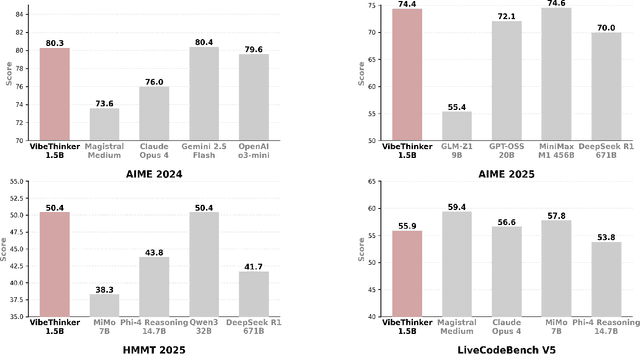

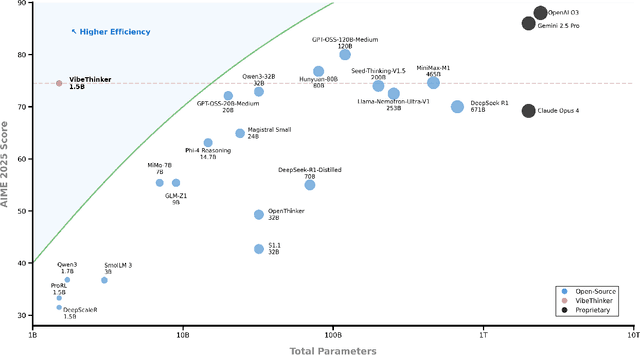
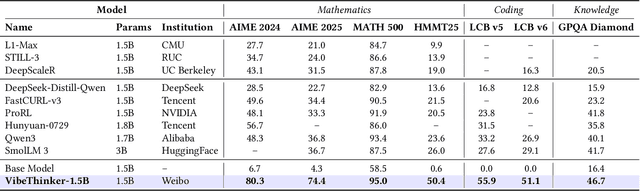
Challenging the prevailing consensus that small models inherently lack robust reasoning, this report introduces VibeThinker-1.5B, a 1.5B-parameter dense model developed via our Spectrum-to-Signal Principle (SSP). This challenges the prevailing approach of scaling model parameters to enhance capabilities, as seen in models like DeepSeek R1 (671B) and Kimi k2 (>1T). The SSP framework first employs a Two-Stage Diversity-Exploring Distillation (SFT) to generate a broad spectrum of solutions, followed by MaxEnt-Guided Policy Optimization (RL) to amplify the correct signal. With a total training cost of only $7,800, VibeThinker-1.5B demonstrates superior reasoning capabilities compared to closed-source models like Magistral Medium and Claude Opus 4, and performs on par with open-source models like GPT OSS-20B Medium. Remarkably, it surpasses the 400x larger DeepSeek R1 on three math benchmarks: AIME24 (80.3 vs. 79.8), AIME25 (74.4 vs. 70.0), and HMMT25 (50.4 vs. 41.7). This is a substantial improvement over its base model (6.7, 4.3, and 0.6, respectively). On LiveCodeBench V6, it scores 51.1, outperforming Magistral Medium's 50.3 and its base model's 0.0. These findings demonstrate that small models can achieve reasoning capabilities comparable to large models, drastically reducing training and inference costs and thereby democratizing advanced AI research.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Mosaic: Data-Free Knowledge Distillation via Mixture-of-Experts for Heterogeneous Distributed Environments
May 26, 2025



Federated Learning (FL) is a decentralized machine learning paradigm that enables clients to collaboratively train models while preserving data privacy. However, the coexistence of model and data heterogeneity gives rise to inconsistent representations and divergent optimization dynamics across clients, ultimately hindering robust global performance. To transcend these challenges, we propose Mosaic, a novel data-free knowledge distillation framework tailored for heterogeneous distributed environments. Mosaic first trains local generative models to approximate each client's personalized distribution, enabling synthetic data generation that safeguards privacy through strict separation from real data. Subsequently, Mosaic forms a Mixture-of-Experts (MoE) from client models based on their specialized knowledge, and distills it into a global model using the generated data. To further enhance the MoE architecture, Mosaic integrates expert predictions via a lightweight meta model trained on a few representative prototypes. Extensive experiments on standard image classification benchmarks demonstrate that Mosaic consistently outperforms state-of-the-art approaches under both model and data heterogeneity. The source code has been published at https://github.com/Wings-Of-Disaster/Mosaic.
VLMLight: Traffic Signal Control via Vision-Language Meta-Control and Dual-Branch Reasoning
May 26, 2025
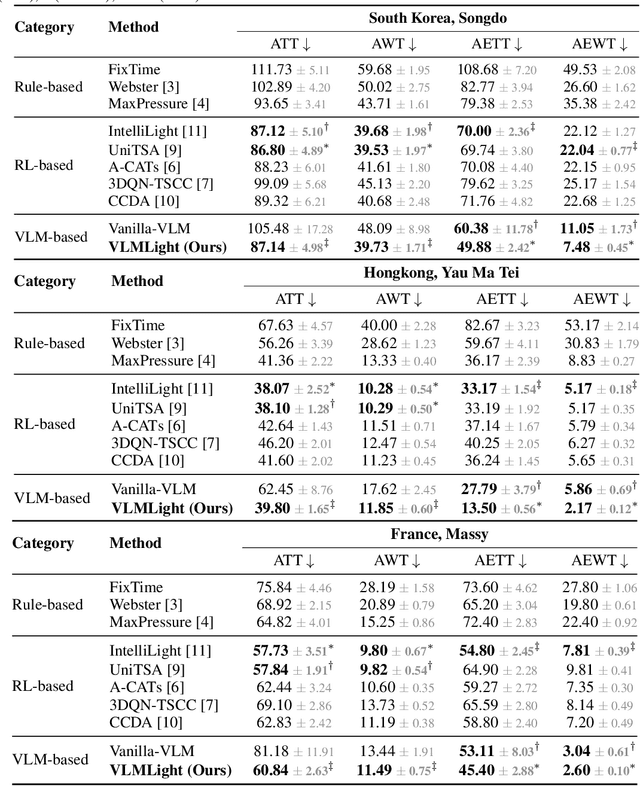
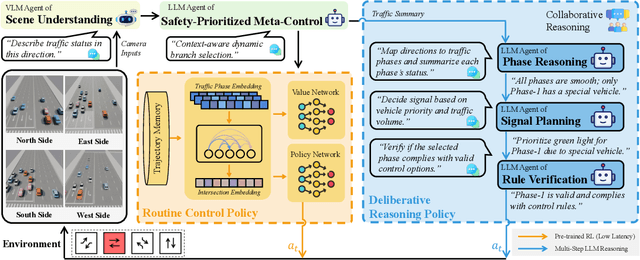

Traffic signal control (TSC) is a core challenge in urban mobility, where real-time decisions must balance efficiency and safety. Existing methods - ranging from rule-based heuristics to reinforcement learning (RL) - often struggle to generalize to complex, dynamic, and safety-critical scenarios. We introduce VLMLight, a novel TSC framework that integrates vision-language meta-control with dual-branch reasoning. At the core of VLMLight is the first image-based traffic simulator that enables multi-view visual perception at intersections, allowing policies to reason over rich cues such as vehicle type, motion, and spatial density. A large language model (LLM) serves as a safety-prioritized meta-controller, selecting between a fast RL policy for routine traffic and a structured reasoning branch for critical cases. In the latter, multiple LLM agents collaborate to assess traffic phases, prioritize emergency vehicles, and verify rule compliance. Experiments show that VLMLight reduces waiting times for emergency vehicles by up to 65% over RL-only systems, while preserving real-time performance in standard conditions with less than 1% degradation. VLMLight offers a scalable, interpretable, and safety-aware solution for next-generation traffic signal control.
Aligning Vision to Language: Text-Free Multimodal Knowledge Graph Construction for Enhanced LLMs Reasoning
Mar 17, 2025Multimodal reasoning in Large Language Models (LLMs) struggles with incomplete knowledge and hallucination artifacts, challenges that textual Knowledge Graphs (KGs) only partially mitigate due to their modality isolation. While Multimodal Knowledge Graphs (MMKGs) promise enhanced cross-modal understanding, their practical construction is impeded by semantic narrowness of manual text annotations and inherent noise in visual-semantic entity linkages. In this paper, we propose Vision-align-to-Language integrated Knowledge Graph (VaLiK), a novel approach for constructing MMKGs that enhances LLMs reasoning through cross-modal information supplementation. Specifically, we cascade pre-trained Vision-Language Models (VLMs) to align image features with text, transforming them into descriptions that encapsulate image-specific information. Furthermore, we developed a cross-modal similarity verification mechanism to quantify semantic consistency, effectively filtering out noise introduced during feature alignment. Even without manually annotated image captions, the refined descriptions alone suffice to construct the MMKG. Compared to conventional MMKGs construction paradigms, our approach achieves substantial storage efficiency gains while maintaining direct entity-to-image linkage capability. Experimental results on multimodal reasoning tasks demonstrate that LLMs augmented with VaLiK outperform previous state-of-the-art models. Our code is published at https://github.com/Wings-Of-Disaster/VaLiK.
PsyDT: Using LLMs to Construct the Digital Twin of Psychological Counselor with Personalized Counseling Style for Psychological Counseling
Dec 18, 2024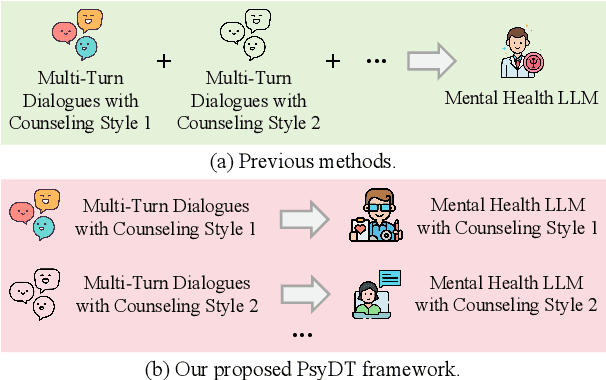
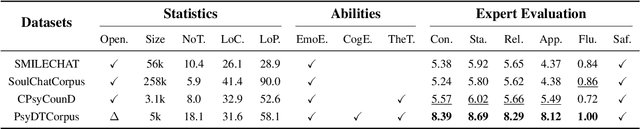
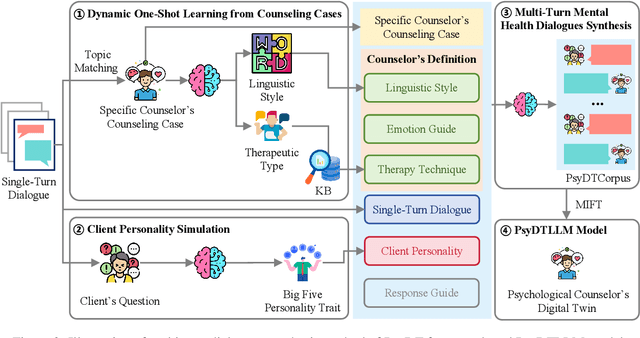
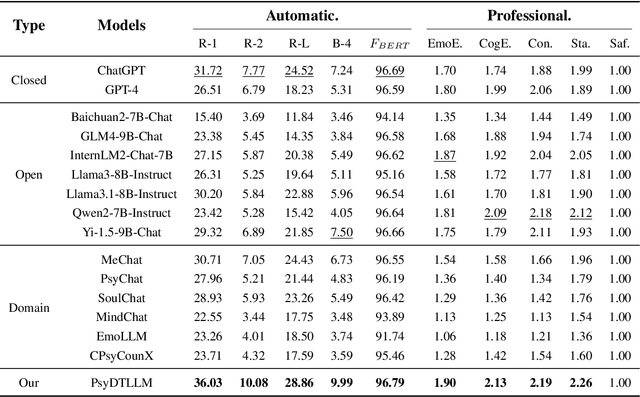
Currently, large language models (LLMs) have made significant progress in the field of psychological counseling. However, existing mental health LLMs overlook a critical issue where they do not consider the fact that different psychological counselors exhibit different personal styles, including linguistic style and therapy techniques, etc. As a result, these LLMs fail to satisfy the individual needs of clients who seek different counseling styles. To help bridge this gap, we propose PsyDT, a novel framework using LLMs to construct the Digital Twin of Psychological counselor with personalized counseling style. Compared to the time-consuming and costly approach of collecting a large number of real-world counseling cases to create a specific counselor's digital twin, our framework offers a faster and more cost-effective solution. To construct PsyDT, we utilize dynamic one-shot learning by using GPT-4 to capture counselor's unique counseling style, mainly focusing on linguistic style and therapy techniques. Subsequently, using existing single-turn long-text dialogues with client's questions, GPT-4 is guided to synthesize multi-turn dialogues of specific counselor. Finally, we fine-tune the LLMs on the synthetic dataset, PsyDTCorpus, to achieve the digital twin of psychological counselor with personalized counseling style. Experimental results indicate that our proposed PsyDT framework can synthesize multi-turn dialogues that closely resemble real-world counseling cases and demonstrate better performance compared to other baselines, thereby show that our framework can effectively construct the digital twin of psychological counselor with a specific counseling style.
SoulChat: Improving LLMs' Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations
Nov 01, 2023



Large language models (LLMs) have been widely applied in various fields due to their excellent capability for memorizing knowledge and chain of thought (CoT). When these language models are applied in the field of psychological counseling, they often rush to provide universal advice. However, when users seek psychological support, they need to gain empathy, trust, understanding and comfort, rather than just reasonable advice. To this end, we constructed a multi-turn empathetic conversation dataset of more than 2 million samples, in which the input is the multi-turn conversation context, and the target is empathetic responses that cover expressions such as questioning, comfort, recognition, listening, trust, emotional support, etc. Experiments have shown that the empathy ability of LLMs can be significantly enhanced when finetuning by using multi-turn dialogue history and responses that are closer to the expression of a psychological consultant.
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
Oct 24, 2023Large language models (LLMs) have performed well in providing general and extensive health suggestions in single-turn conversations, exemplified by systems such as ChatGPT, ChatGLM, ChatDoctor, DoctorGLM, and etc. However, the limited information provided by users during single turn results in inadequate personalization and targeting of the generated suggestions, which requires users to independently select the useful part. It is mainly caused by the missing ability to engage in multi-turn questioning. In real-world medical consultations, doctors usually employ a series of iterative inquiries to comprehend the patient's condition thoroughly, enabling them to provide effective and personalized suggestions subsequently, which can be defined as chain of questioning (CoQ) for LLMs. To improve the CoQ of LLMs, we propose BianQue, a ChatGLM-based LLM finetuned with the self-constructed health conversation dataset BianQueCorpus that is consist of multiple turns of questioning and health suggestions polished by ChatGPT. Experimental results demonstrate that the proposed BianQue can simultaneously balance the capabilities of both questioning and health suggestions, which will help promote the research and application of LLMs in the field of proactive health.