 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonLight: A Multimodal Foundation Model-Enhanced Reinforcement Learning Framework for Zero-Shot Traffic Signal Control
May 28, 2026Reinforcement learning (RL) has shown promise in traffic signal control (TSC). However, its reliance on predefined states limits responsiveness to observable open-world events that are absent from training data. IoT-enabled intersections provide heterogeneous observations from roadside sensors and cameras, creating opportunities to improve RL adaptability to such events. To this end, we propose ReasonLight, a multimodal foundation model-enhanced RL framework for zero-shot TSC. ReasonLight integrates three sources of information: structured traffic measurements, multi-view camera observations, and candidate phase decisions from a pre-trained RL controller. Given an RL-proposed phase, ReasonLight extracts visual semantics from multi-view images and aligns them with compact sensor-derived scene descriptions. This alignment enables a semantic-guided refinement module to either preserve or adjust the proposed action according to traffic rules and event semantics. To ensure operational reliability, refined actions are constrained by the set of available phases. Any invalid decision is rejected, and the system falls back to the original RL action. We evaluate ReasonLight on two types of rare events not seen during RL training: emergency vehicle priority and temporary traffic regulation. Experimental results show that ReasonLight achieves zero-shot adaptation without retraining. It reduces emergency vehicle waiting time by up to 88.7% compared with the RL-only backbone while preserving comparable routine traffic performance.
Heterogeneous Vertiport Selection Optimization for On-Demand Air Taxi Services: A Deep Reinforcement Learning Approach
Jan 29, 2026Urban Air Mobility (UAM) has emerged as a transformative solution to alleviate urban congestion by utilizing low-altitude airspace, thereby reducing pressure on ground transportation networks. To enable truly efficient and seamless door-to-door travel experiences, UAM requires close integration with existing ground transportation infrastructure. However, current research on optimal integrated routing strategies for passengers in air-ground mobility systems remains limited, with a lack of systematic exploration.To address this gap, we first propose a unified optimization model that integrates strategy selection for both air and ground transportation. This model captures the dynamic characteristics of multimodal transport networks and incorporates real-time traffic conditions alongside passenger decision-making behavior. Building on this model, we propose a Unified Air-Ground Mobility Coordination (UAGMC) framework, which leverages deep reinforcement learning (RL) and Vehicle-to-Everything (V2X) communication to optimize vertiport selection and dynamically plan air taxi routes. Experimental results demonstrate that UAGMC achieves a 34\% reduction in average travel time compared to conventional proportional allocation methods, enhancing overall travel efficiency and providing novel insights into the integration and optimization of multimodal transportation systems. This work lays a solid foundation for advancing intelligent urban mobility solutions through the coordination of air and ground transportation modes. The related code can be found at https://github.com/Traffic-Alpha/UAGMC.
VLMLight: Traffic Signal Control via Vision-Language Meta-Control and Dual-Branch Reasoning
May 26, 2025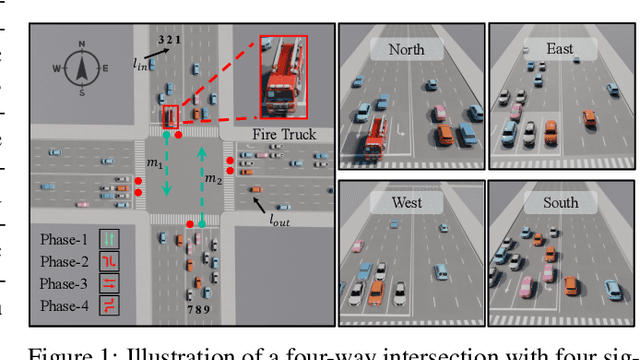
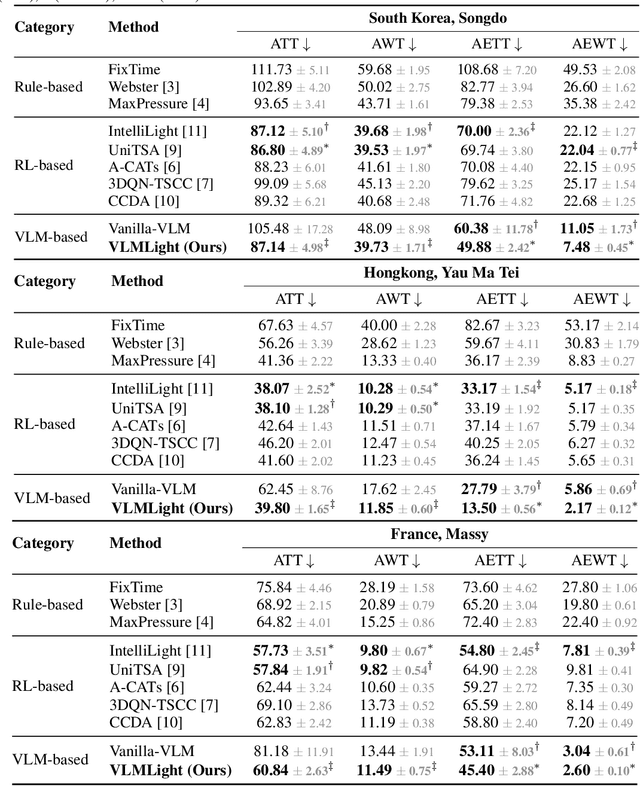
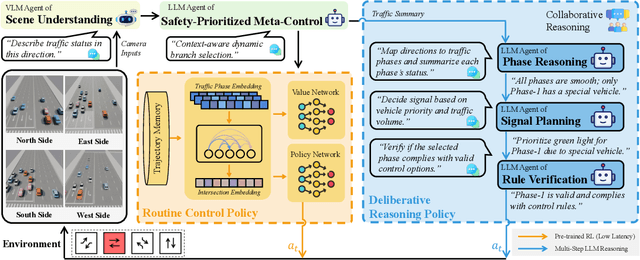

Traffic signal control (TSC) is a core challenge in urban mobility, where real-time decisions must balance efficiency and safety. Existing methods - ranging from rule-based heuristics to reinforcement learning (RL) - often struggle to generalize to complex, dynamic, and safety-critical scenarios. We introduce VLMLight, a novel TSC framework that integrates vision-language meta-control with dual-branch reasoning. At the core of VLMLight is the first image-based traffic simulator that enables multi-view visual perception at intersections, allowing policies to reason over rich cues such as vehicle type, motion, and spatial density. A large language model (LLM) serves as a safety-prioritized meta-controller, selecting between a fast RL policy for routine traffic and a structured reasoning branch for critical cases. In the latter, multiple LLM agents collaborate to assess traffic phases, prioritize emergency vehicles, and verify rule compliance. Experiments show that VLMLight reduces waiting times for emergency vehicles by up to 65% over RL-only systems, while preserving real-time performance in standard conditions with less than 1% degradation. VLMLight offers a scalable, interpretable, and safety-aware solution for next-generation traffic signal control.
Kolmogorov-Arnold Network for Remote Sensing Image Semantic Segmentation
Jan 13, 2025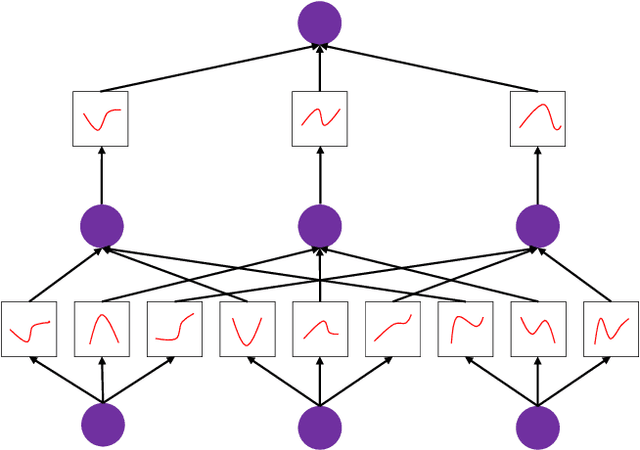
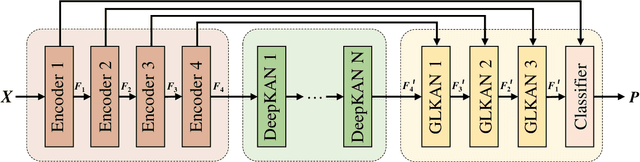
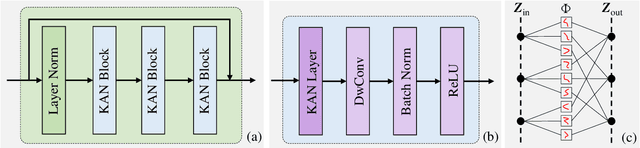
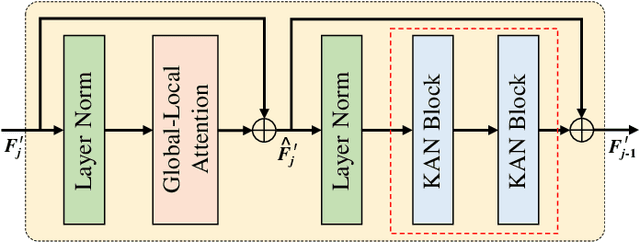
Semantic segmentation plays a crucial role in remote sensing applications, where the accurate extraction and representation of features are essential for high-quality results. Despite the widespread use of encoder-decoder architectures, existing methods often struggle with fully utilizing the high-dimensional features extracted by the encoder and efficiently recovering detailed information during decoding. To address these problems, we propose a novel semantic segmentation network, namely DeepKANSeg, including two key innovations based on the emerging Kolmogorov Arnold Network (KAN). Notably, the advantage of KAN lies in its ability to decompose high-dimensional complex functions into univariate transformations, enabling efficient and flexible representation of intricate relationships in data. First, we introduce a KAN-based deep feature refinement module, namely DeepKAN to effectively capture complex spatial and rich semantic relationships from high-dimensional features. Second, we replace the traditional multi-layer perceptron (MLP) layers in the global-local combined decoder with KAN-based linear layers, namely GLKAN. This module enhances the decoder's ability to capture fine-grained details during decoding. To evaluate the effectiveness of the proposed method, experiments are conducted on two well-known fine-resolution remote sensing benchmark datasets, namely ISPRS Vaihingen and ISPRS Potsdam. The results demonstrate that the KAN-enhanced segmentation model achieves superior performance in terms of accuracy compared to state-of-the-art methods. They highlight the potential of KANs as a powerful alternative to traditional architectures in semantic segmentation tasks. Moreover, the explicit univariate decomposition provides improved interpretability, which is particularly beneficial for applications requiring explainable learning in remote sensing.
MANet: Fine-Tuning Segment Anything Model for Multimodal Remote Sensing Semantic Segmentation
Oct 15, 2024



Multimodal remote sensing data, collected from a variety of sensors, provide a comprehensive and integrated perspective of the Earth's surface. By employing multimodal fusion techniques, semantic segmentation offers more detailed insights into geographic scenes compared to single-modality approaches. Building upon recent advancements in vision foundation models, particularly the Segment Anything Model (SAM), this study introduces a novel Multimodal Adapter-based Network (MANet) for multimodal remote sensing semantic segmentation. At the core of this approach is the development of a Multimodal Adapter (MMAdapter), which fine-tunes SAM's image encoder to effectively leverage the model's general knowledge for multimodal data. In addition, a pyramid-based Deep Fusion Module (DFM) is incorporated to further integrate high-level geographic features across multiple scales before decoding. This work not only introduces a novel network for multimodal fusion, but also demonstrates, for the first time, SAM's powerful generalization capabilities with Digital Surface Model (DSM) data. Experimental results on two well-established fine-resolution multimodal remote sensing datasets, ISPRS Vaihingen and ISPRS Potsdam, confirm that the proposed MANet significantly surpasses current models in the task of multimodal semantic segmentation. The source code for this work will be accessible at https://github.com/sstary/SSRS.
PPMamba: A Pyramid Pooling Local Auxiliary SSM-Based Model for Remote Sensing Image Semantic Segmentation
Sep 10, 2024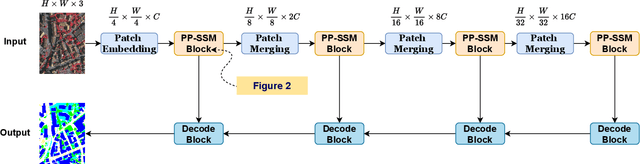
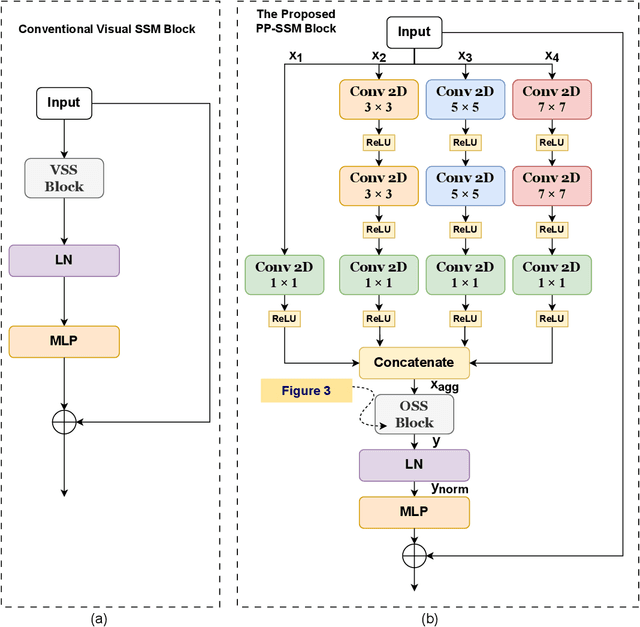
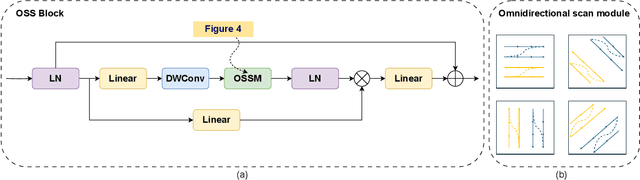
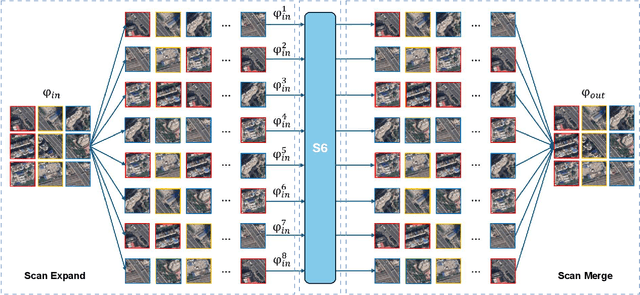
Semantic segmentation is a vital task in the field of remote sensing (RS). However, conventional convolutional neural network (CNN) and transformer-based models face limitations in capturing long-range dependencies or are often computationally intensive. Recently, an advanced state space model (SSM), namely Mamba, was introduced, offering linear computational complexity while effectively establishing long-distance dependencies. Despite their advantages, Mamba-based methods encounter challenges in preserving local semantic information. To cope with these challenges, this paper proposes a novel network called Pyramid Pooling Mamba (PPMamba), which integrates CNN and Mamba for RS semantic segmentation tasks. The core structure of PPMamba, the Pyramid Pooling-State Space Model (PP-SSM) block, combines a local auxiliary mechanism with an omnidirectional state space model (OSS) that selectively scans feature maps from eight directions, capturing comprehensive feature information. Additionally, the auxiliary mechanism includes pyramid-shaped convolutional branches designed to extract features at multiple scales. Extensive experiments on two widely-used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate that PPMamba achieves competitive performance compared to state-of-the-art models.
iLLM-TSC: Integration reinforcement learning and large language model for traffic signal control policy improvement
Jul 08, 2024
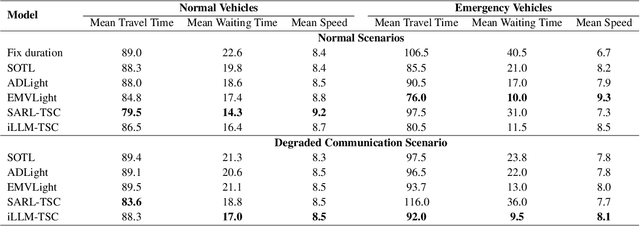
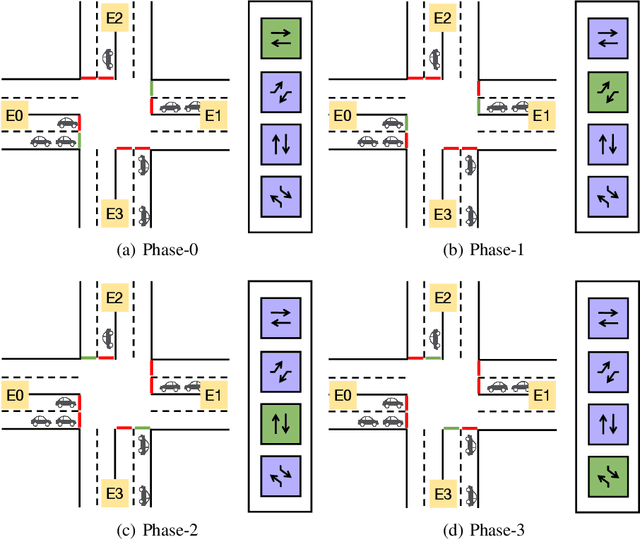

Urban congestion remains a critical challenge, with traffic signal control (TSC) emerging as a potent solution. TSC is often modeled as a Markov Decision Process problem and then solved using reinforcement learning (RL), which has proven effective. However, the existing RL-based TSC system often overlooks imperfect observations caused by degraded communication, such as packet loss, delays, and noise, as well as rare real-life events not included in the reward function, such as unconsidered emergency vehicles. To address these limitations, we introduce a novel integration framework that combines a large language model (LLM) with RL. This framework is designed to manage overlooked elements in the reward function and gaps in state information, thereby enhancing the policies of RL agents. In our approach, RL initially makes decisions based on observed data. Subsequently, LLMs evaluate these decisions to verify their reasonableness. If a decision is found to be unreasonable, it is adjusted accordingly. Additionally, this integration approach can be seamlessly integrated with existing RL-based TSC systems without necessitating modifications. Extensive testing confirms that our approach reduces the average waiting time by $17.5\%$ in degraded communication conditions as compared to traditional RL methods, underscoring its potential to advance practical RL applications in intelligent transportation systems. The related code can be found at \url{https://github.com/Traffic-Alpha/iLLM-TSC}.
Frequency Decomposition-Driven Unsupervised Domain Adaptation for Remote Sensing Image Semantic Segmentation
Apr 06, 2024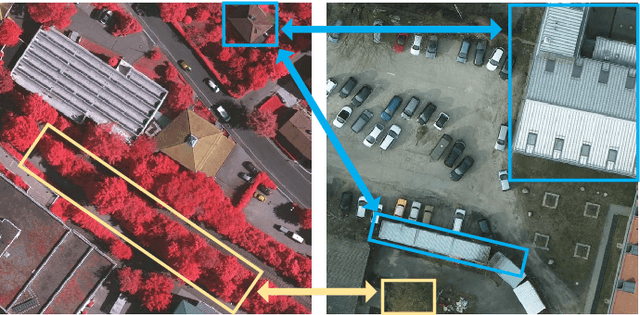
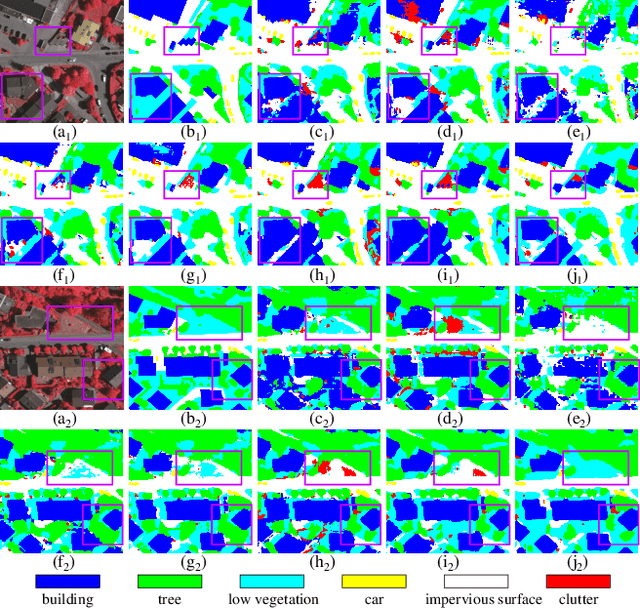
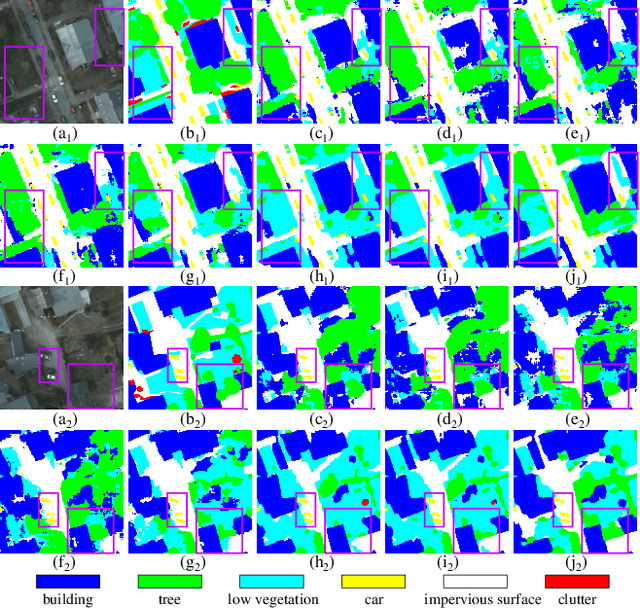

Cross-domain semantic segmentation of remote sensing (RS) imagery based on unsupervised domain adaptation (UDA) techniques has significantly advanced deep-learning applications in the geosciences. Recently, with its ingenious and versatile architecture, the Transformer model has been successfully applied in RS-UDA tasks. However, existing UDA methods mainly focus on domain alignment in the high-level feature space. It is still challenging to retain cross-domain local spatial details and global contextual semantics simultaneously, which is crucial for the RS image semantic segmentation task. To address these problems, we propose novel high/low-frequency decomposition (HLFD) techniques to guide representation alignment in cross-domain semantic segmentation. Specifically, HLFD attempts to decompose the feature maps into high- and low-frequency components before performing the domain alignment in the corresponding subspaces. Secondly, to further facilitate the alignment of decomposed features, we propose a fully global-local generative adversarial network, namely GLGAN, to learn domain-invariant detailed and semantic features across domains by leveraging global-local transformer blocks (GLTBs). By integrating HLFD techniques and the GLGAN, a novel UDA framework called FD-GLGAN is developed to improve the cross-domain transferability and generalization capability of semantic segmentation models. Extensive experiments on two fine-resolution benchmark datasets, namely ISPRS Potsdam and ISPRS Vaihingen, highlight the effectiveness and superiority of the proposed approach as compared to the state-of-the-art UDA methods. The source code for this work will be accessible at https://github.com/sstary/SSRS.
RS3Mamba: Visual State Space Model for Remote Sensing Images Semantic Segmentation
Apr 03, 2024Semantic segmentation of remote sensing images is a fundamental task in geoscience research. However, there are some significant shortcomings for the widely used convolutional neural networks (CNNs) and Transformers. The former is limited by its insufficient long-range modeling capabilities, while the latter is hampered by its computational complexity. Recently, a novel visual state space (VSS) model represented by Mamba has emerged, capable of modeling long-range relationships with linear computability. In this work, we propose a novel dual-branch network named remote sensing images semantic segmentation Mamba (RS3Mamba) to incorporate this innovative technology into remote sensing tasks. Specifically, RS3Mamba utilizes VSS blocks to construct an auxiliary branch, providing additional global information to convolution-based main branch. Moreover, considering the distinct characteristics of the two branches, we introduce a collaborative completion module (CCM) to enhance and fuse features from the dual-encoder. Experimental results on two widely used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness and potential of the proposed RS3Mamba. To the best of our knowledge, this is the first vision Mamba specifically designed for remote sensing images semantic segmentation. The source code will be made available at https://github.com/sstary/SSRS.
Adaptive Semantic-Enhanced Denoising Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Mar 17, 2024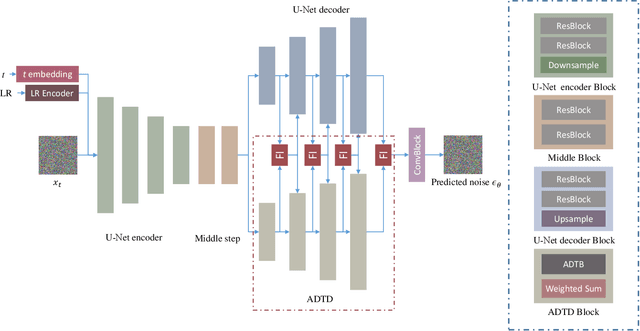
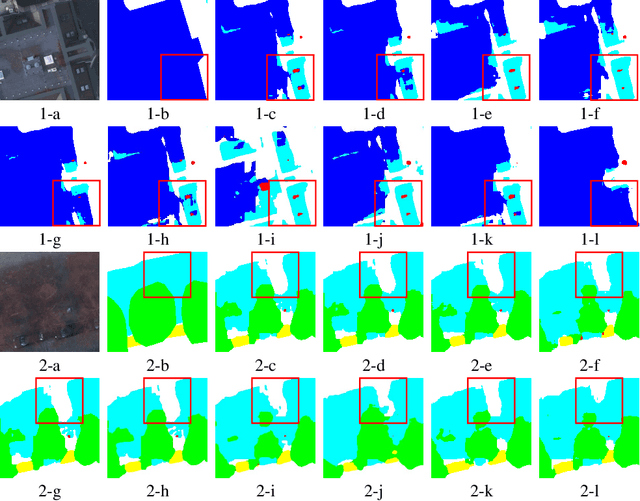
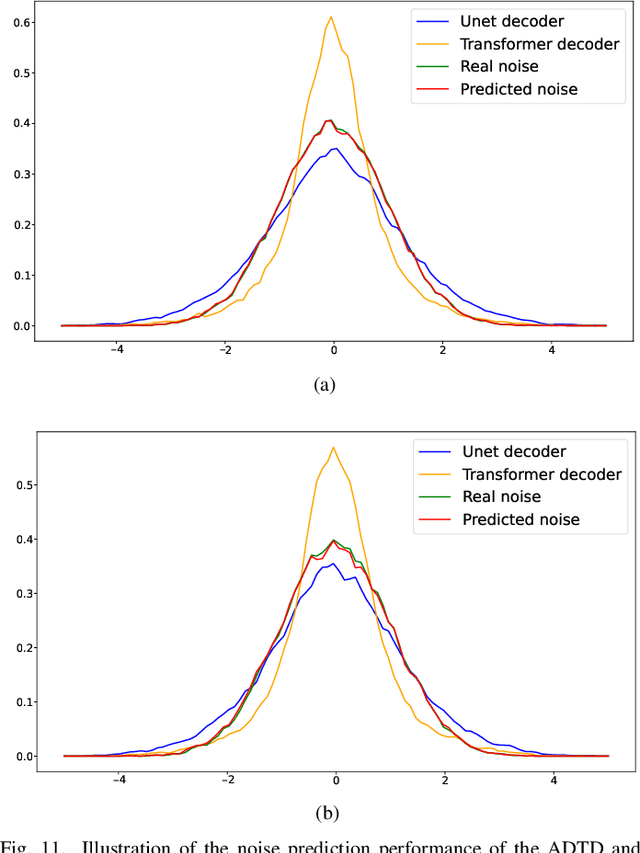
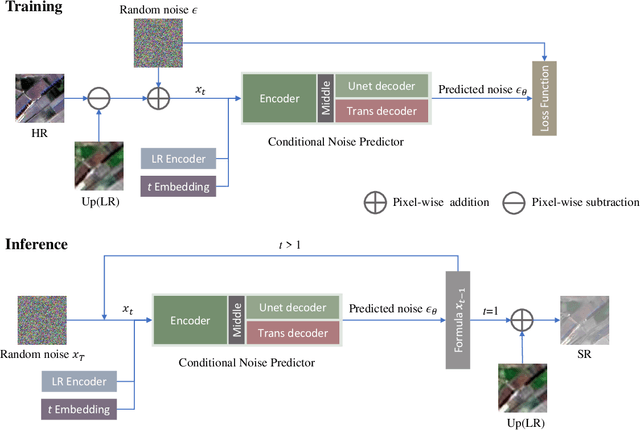
Remote sensing image super-resolution (SR) is a crucial task to restore high-resolution (HR) images from low-resolution (LR) observations. Recently, the Denoising Diffusion Probabilistic Model (DDPM) has shown promising performance in image reconstructions by overcoming problems inherent in generative models, such as over-smoothing and mode collapse. However, the high-frequency details generated by DDPM often suffer from misalignment with HR images due to the model's tendency to overlook long-range semantic contexts. This is attributed to the widely used U-Net decoder in the conditional noise predictor, which tends to overemphasize local information, leading to the generation of noises with significant variances during the prediction process. To address these issues, an adaptive semantic-enhanced DDPM (ASDDPM) is proposed to enhance the detail-preserving capability of the DDPM by incorporating low-frequency semantic information provided by the Transformer. Specifically, a novel adaptive diffusion Transformer decoder (ADTD) is developed to bridge the semantic gap between the encoder and decoder through regulating the noise prediction with the global contextual relationships and long-range dependencies in the diffusion process. Additionally, a residual feature fusion strategy establishes information exchange between the two decoders at multiple levels. As a result, the predicted noise generated by our approach closely approximates that of the real noise distribution.Extensive experiments on two SR and two semantic segmentation datasets confirm the superior performance of the proposed ASDDPM in both SR and the subsequent downstream applications. The source code will be available at https://github.com/littlebeen/ASDDPM-Adaptive-Semantic-Enhanced-DDPM.