 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCCDiff: Occupancy Diffusion Model for High-Fidelity 3D Building Reconstruction from Noisy Point Clouds
Dec 09, 2025A major challenge in reconstructing buildings from LiDAR point clouds lies in accurately capturing building surfaces under varying point densities and noise interference. To flexibly gather high-quality 3D profiles of the building in diverse resolution, we propose OCCDiff applying latent diffusion in the occupancy function space. Our OCCDiff combines a latent diffusion process with a function autoencoder architecture to generate continuous occupancy functions evaluable at arbitrary locations. Moreover, a point encoder is proposed to provide condition features to diffusion learning, constraint the final occupancy prediction for occupancy decoder, and insert multi-modal features for latent generation to latent encoder. To further enhance the model performance, a multi-task training strategy is employed, ensuring that the point encoder learns diverse and robust feature representations. Empirical results show that our method generates physically consistent samples with high fidelity to the target distribution and exhibits robustness to noisy data.
Pose as a Modality: A Psychology-Inspired Network for Personality Recognition with a New Multimodal Dataset
Mar 17, 2025In recent years, predicting Big Five personality traits from multimodal data has received significant attention in artificial intelligence (AI). However, existing computational models often fail to achieve satisfactory performance. Psychological research has shown a strong correlation between pose and personality traits, yet previous research has largely ignored pose data in computational models. To address this gap, we develop a novel multimodal dataset that incorporates full-body pose data. The dataset includes video recordings of 287 participants completing a virtual interview with 36 questions, along with self-reported Big Five personality scores as labels. To effectively utilize this multimodal data, we introduce the Psychology-Inspired Network (PINet), which consists of three key modules: Multimodal Feature Awareness (MFA), Multimodal Feature Interaction (MFI), and Psychology-Informed Modality Correlation Loss (PIMC Loss). The MFA module leverages the Vision Mamba Block to capture comprehensive visual features related to personality, while the MFI module efficiently fuses the multimodal features. The PIMC Loss, grounded in psychological theory, guides the model to emphasize different modalities for different personality dimensions. Experimental results show that the PINet outperforms several state-of-the-art baseline models. Furthermore, the three modules of PINet contribute almost equally to the model's overall performance. Incorporating pose data significantly enhances the model's performance, with the pose modality ranking mid-level in importance among the five modalities. These findings address the existing gap in personality-related datasets that lack full-body pose data and provide a new approach for improving the accuracy of personality prediction models, highlighting the importance of integrating psychological insights into AI frameworks.
PPMamba: A Pyramid Pooling Local Auxiliary SSM-Based Model for Remote Sensing Image Semantic Segmentation
Sep 10, 2024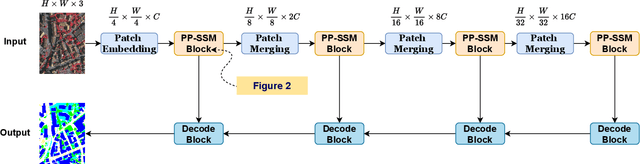
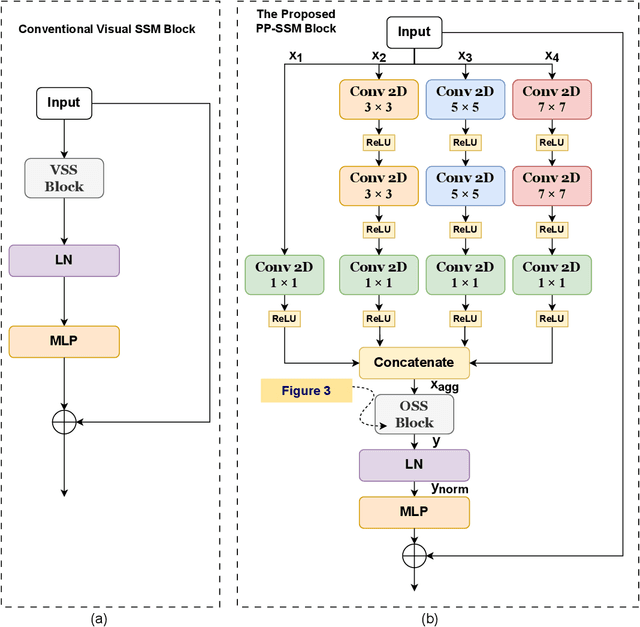
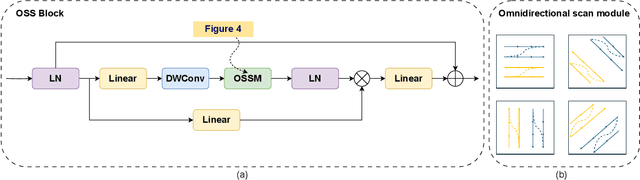
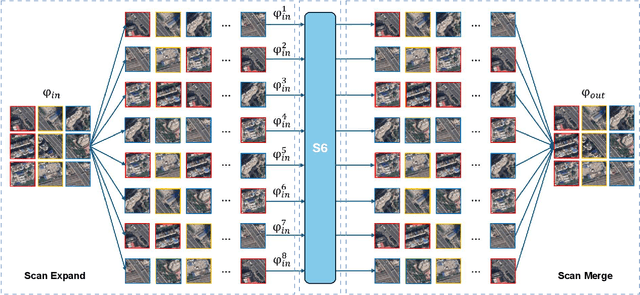
Semantic segmentation is a vital task in the field of remote sensing (RS). However, conventional convolutional neural network (CNN) and transformer-based models face limitations in capturing long-range dependencies or are often computationally intensive. Recently, an advanced state space model (SSM), namely Mamba, was introduced, offering linear computational complexity while effectively establishing long-distance dependencies. Despite their advantages, Mamba-based methods encounter challenges in preserving local semantic information. To cope with these challenges, this paper proposes a novel network called Pyramid Pooling Mamba (PPMamba), which integrates CNN and Mamba for RS semantic segmentation tasks. The core structure of PPMamba, the Pyramid Pooling-State Space Model (PP-SSM) block, combines a local auxiliary mechanism with an omnidirectional state space model (OSS) that selectively scans feature maps from eight directions, capturing comprehensive feature information. Additionally, the auxiliary mechanism includes pyramid-shaped convolutional branches designed to extract features at multiple scales. Extensive experiments on two widely-used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate that PPMamba achieves competitive performance compared to state-of-the-art models.
Adaptive Semantic-Enhanced Denoising Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Mar 17, 2024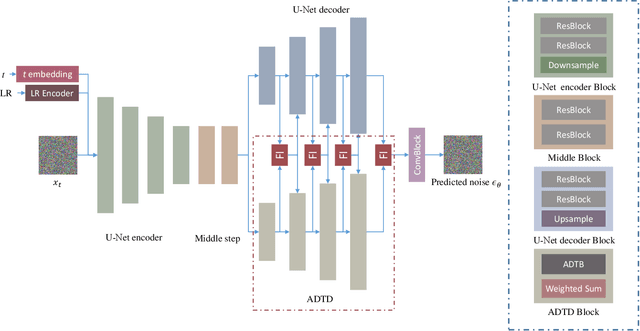
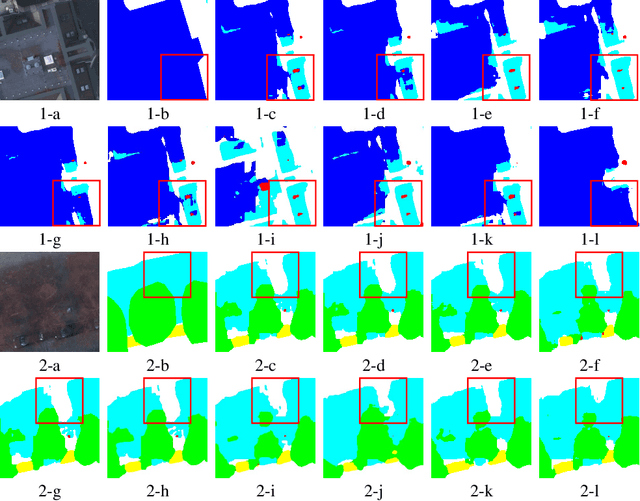
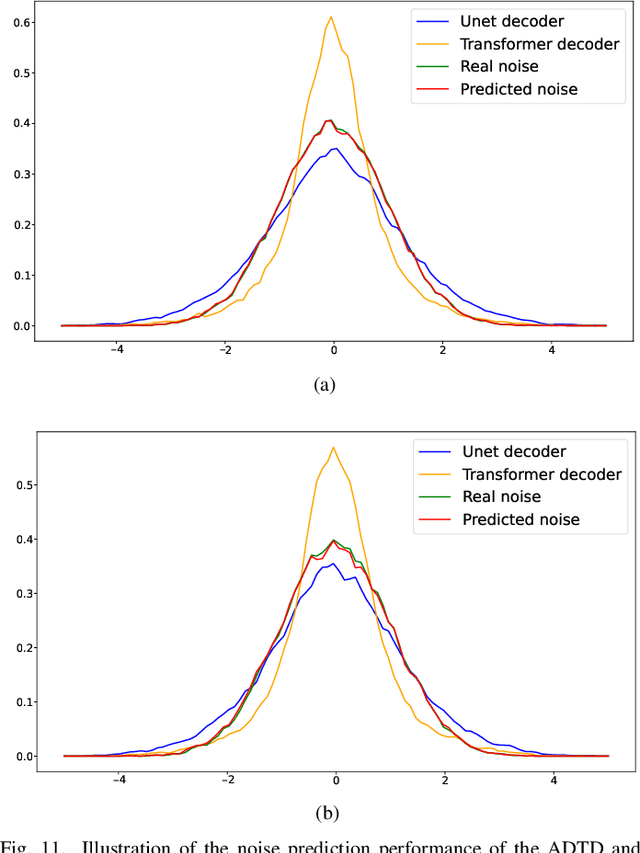
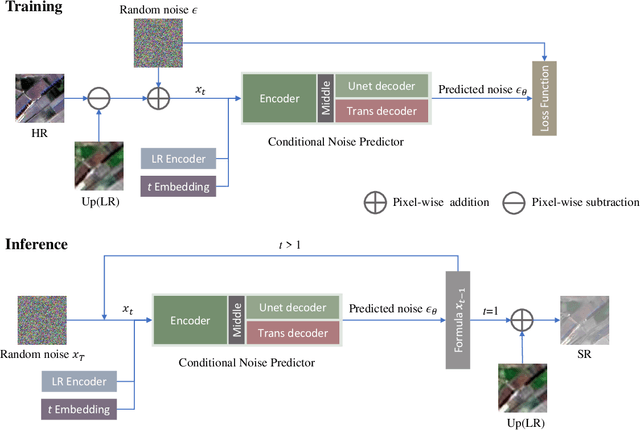
Remote sensing image super-resolution (SR) is a crucial task to restore high-resolution (HR) images from low-resolution (LR) observations. Recently, the Denoising Diffusion Probabilistic Model (DDPM) has shown promising performance in image reconstructions by overcoming problems inherent in generative models, such as over-smoothing and mode collapse. However, the high-frequency details generated by DDPM often suffer from misalignment with HR images due to the model's tendency to overlook long-range semantic contexts. This is attributed to the widely used U-Net decoder in the conditional noise predictor, which tends to overemphasize local information, leading to the generation of noises with significant variances during the prediction process. To address these issues, an adaptive semantic-enhanced DDPM (ASDDPM) is proposed to enhance the detail-preserving capability of the DDPM by incorporating low-frequency semantic information provided by the Transformer. Specifically, a novel adaptive diffusion Transformer decoder (ADTD) is developed to bridge the semantic gap between the encoder and decoder through regulating the noise prediction with the global contextual relationships and long-range dependencies in the diffusion process. Additionally, a residual feature fusion strategy establishes information exchange between the two decoders at multiple levels. As a result, the predicted noise generated by our approach closely approximates that of the real noise distribution.Extensive experiments on two SR and two semantic segmentation datasets confirm the superior performance of the proposed ASDDPM in both SR and the subsequent downstream applications. The source code will be available at https://github.com/littlebeen/ASDDPM-Adaptive-Semantic-Enhanced-DDPM.
DF4LCZ: A SAM-Empowered Data Fusion Framework for Scene-Level Local Climate Zone Classification
Mar 14, 2024Recent advancements in remote sensing (RS) technologies have shown their potential in accurately classifying local climate zones (LCZs). However, traditional scene-level methods using convolutional neural networks (CNNs) often struggle to integrate prior knowledge of ground objects effectively. Moreover, commonly utilized data sources like Sentinel-2 encounter difficulties in capturing detailed ground object information. To tackle these challenges, we propose a data fusion method that integrates ground object priors extracted from high-resolution Google imagery with Sentinel-2 multispectral imagery. The proposed method introduces a novel Dual-stream Fusion framework for LCZ classification (DF4LCZ), integrating instance-based location features from Google imagery with the scene-level spatial-spectral features extracted from Sentinel-2 imagery. The framework incorporates a Graph Convolutional Network (GCN) module empowered by the Segment Anything Model (SAM) to enhance feature extraction from Google imagery. Simultaneously, the framework employs a 3D-CNN architecture to learn the spectral-spatial features of Sentinel-2 imagery. Experiments are conducted on a multi-source remote sensing image dataset specifically designed for LCZ classification, validating the effectiveness of the proposed DF4LCZ. The related code and dataset are available at https://github.com/ctrlovefly/DF4LCZ.
Diffusion Enhancement for Cloud Removal in Ultra-Resolution Remote Sensing Imagery
Jan 25, 2024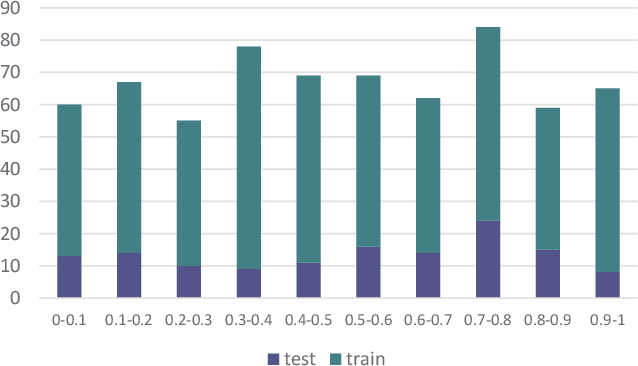
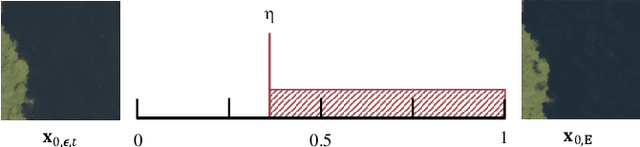
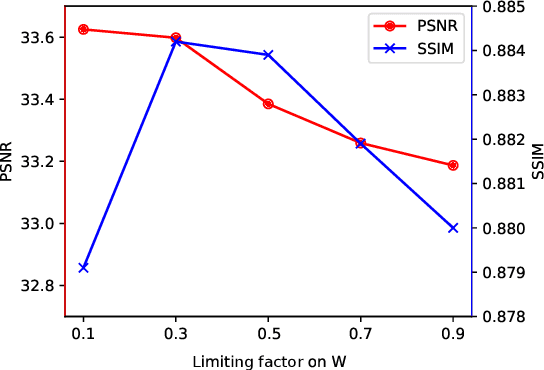
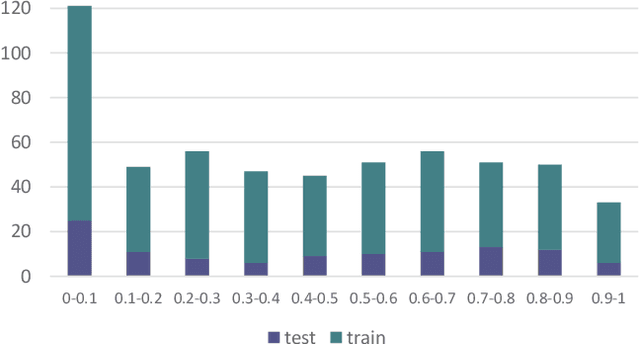
The presence of cloud layers severely compromises the quality and effectiveness of optical remote sensing (RS) images. However, existing deep-learning (DL)-based Cloud Removal (CR) techniques encounter difficulties in accurately reconstructing the original visual authenticity and detailed semantic content of the images. To tackle this challenge, this work proposes to encompass enhancements at the data and methodology fronts. On the data side, an ultra-resolution benchmark named CUHK Cloud Removal (CUHK-CR) of 0.5m spatial resolution is established. This benchmark incorporates rich detailed textures and diverse cloud coverage, serving as a robust foundation for designing and assessing CR models. From the methodology perspective, a novel diffusion-based framework for CR called Diffusion Enhancement (DE) is proposed to perform progressive texture detail recovery, which mitigates the training difficulty with improved inference accuracy. Additionally, a Weight Allocation (WA) network is developed to dynamically adjust the weights for feature fusion, thereby further improving performance, particularly in the context of ultra-resolution image generation. Furthermore, a coarse-to-fine training strategy is applied to effectively expedite training convergence while reducing the computational complexity required to handle ultra-resolution images. Extensive experiments on the newly established CUHK-CR and existing datasets such as RICE confirm that the proposed DE framework outperforms existing DL-based methods in terms of both perceptual quality and signal fidelity.
FreestyleRet: Retrieving Images from Style-Diversified Queries
Dec 08, 2023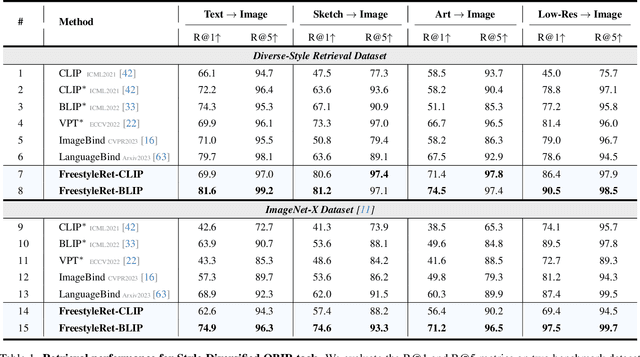


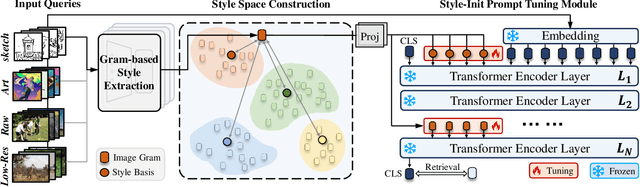
Image Retrieval aims to retrieve corresponding images based on a given query. In application scenarios, users intend to express their retrieval intent through various query styles. However, current retrieval tasks predominantly focus on text-query retrieval exploration, leading to limited retrieval query options and potential ambiguity or bias in user intention. In this paper, we propose the Style-Diversified Query-Based Image Retrieval task, which enables retrieval based on various query styles. To facilitate the novel setting, we propose the first Diverse-Style Retrieval dataset, encompassing diverse query styles including text, sketch, low-resolution, and art. We also propose a light-weighted style-diversified retrieval framework. For various query style inputs, we apply the Gram Matrix to extract the query's textural features and cluster them into a style space with style-specific bases. Then we employ the style-init prompt tuning module to enable the visual encoder to comprehend the texture and style information of the query. Experiments demonstrate that our model, employing the style-init prompt tuning strategy, outperforms existing retrieval models on the style-diversified retrieval task. Moreover, style-diversified queries~(sketch+text, art+text, etc) can be simultaneously retrieved in our model. The auxiliary information from other queries enhances the retrieval performance within the respective query.