 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKolmogorov-Arnold Network for Remote Sensing Image Semantic Segmentation
Jan 13, 2025
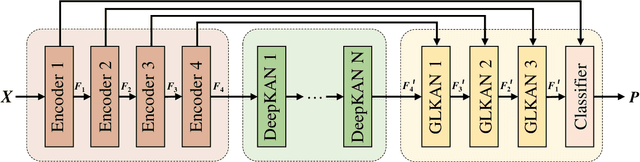
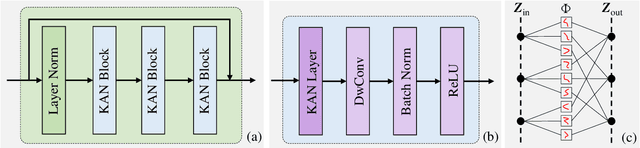
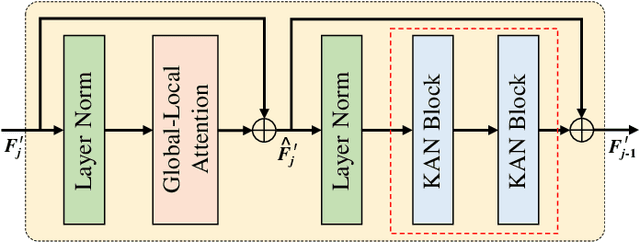
Semantic segmentation plays a crucial role in remote sensing applications, where the accurate extraction and representation of features are essential for high-quality results. Despite the widespread use of encoder-decoder architectures, existing methods often struggle with fully utilizing the high-dimensional features extracted by the encoder and efficiently recovering detailed information during decoding. To address these problems, we propose a novel semantic segmentation network, namely DeepKANSeg, including two key innovations based on the emerging Kolmogorov Arnold Network (KAN). Notably, the advantage of KAN lies in its ability to decompose high-dimensional complex functions into univariate transformations, enabling efficient and flexible representation of intricate relationships in data. First, we introduce a KAN-based deep feature refinement module, namely DeepKAN to effectively capture complex spatial and rich semantic relationships from high-dimensional features. Second, we replace the traditional multi-layer perceptron (MLP) layers in the global-local combined decoder with KAN-based linear layers, namely GLKAN. This module enhances the decoder's ability to capture fine-grained details during decoding. To evaluate the effectiveness of the proposed method, experiments are conducted on two well-known fine-resolution remote sensing benchmark datasets, namely ISPRS Vaihingen and ISPRS Potsdam. The results demonstrate that the KAN-enhanced segmentation model achieves superior performance in terms of accuracy compared to state-of-the-art methods. They highlight the potential of KANs as a powerful alternative to traditional architectures in semantic segmentation tasks. Moreover, the explicit univariate decomposition provides improved interpretability, which is particularly beneficial for applications requiring explainable learning in remote sensing.
PPMamba: A Pyramid Pooling Local Auxiliary SSM-Based Model for Remote Sensing Image Semantic Segmentation
Sep 10, 2024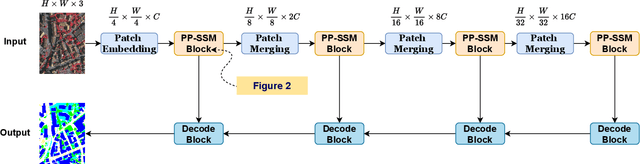
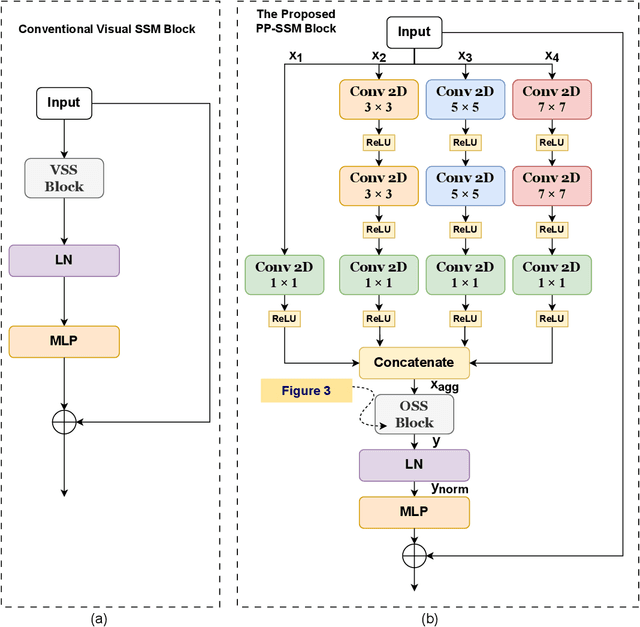
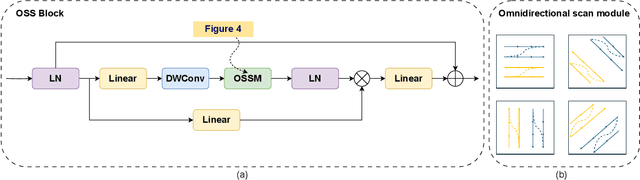
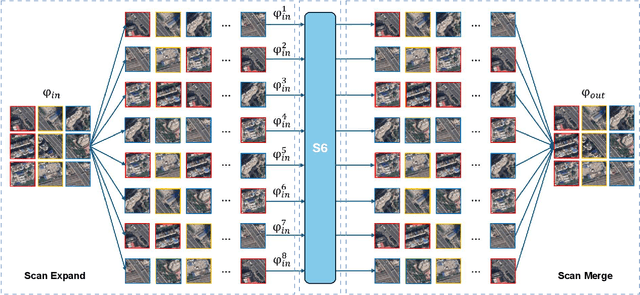
Semantic segmentation is a vital task in the field of remote sensing (RS). However, conventional convolutional neural network (CNN) and transformer-based models face limitations in capturing long-range dependencies or are often computationally intensive. Recently, an advanced state space model (SSM), namely Mamba, was introduced, offering linear computational complexity while effectively establishing long-distance dependencies. Despite their advantages, Mamba-based methods encounter challenges in preserving local semantic information. To cope with these challenges, this paper proposes a novel network called Pyramid Pooling Mamba (PPMamba), which integrates CNN and Mamba for RS semantic segmentation tasks. The core structure of PPMamba, the Pyramid Pooling-State Space Model (PP-SSM) block, combines a local auxiliary mechanism with an omnidirectional state space model (OSS) that selectively scans feature maps from eight directions, capturing comprehensive feature information. Additionally, the auxiliary mechanism includes pyramid-shaped convolutional branches designed to extract features at multiple scales. Extensive experiments on two widely-used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate that PPMamba achieves competitive performance compared to state-of-the-art models.
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Apr 08, 2024
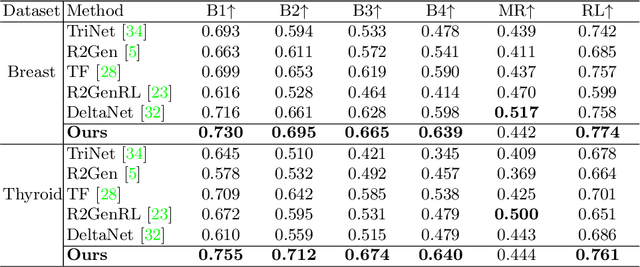


Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.