 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tilted Seesaw: Revisiting Autoencoder Trade-off for Controllable Diffusion
Jan 29, 2026In latent diffusion models, the autoencoder (AE) is typically expected to balance two capabilities: faithful reconstruction and a generation-friendly latent space (e.g., low gFID). In recent ImageNet-scale AE studies, we observe a systematic bias toward generative metrics in handling this trade-off: reconstruction metrics are increasingly under-reported, and ablation-based AE selection often favors the best-gFID configuration even when reconstruction fidelity degrades. We theoretically analyze why this gFID-dominant preference can appear unproblematic for ImageNet generation, yet becomes risky when scaling to controllable diffusion: AEs can induce condition drift, which limits achievable condition alignment. Meanwhile, we find that reconstruction fidelity, especially instance-level measures, better indicates controllability. We empirically validate the impact of tilted autoencoder evaluation on controllability by studying several recent ImageNet AEs. Using a multi-dimensional condition-drift evaluation protocol reflecting controllable generation tasks, we find that gFID is only weakly predictive of condition preservation, whereas reconstruction-oriented metrics are substantially more aligned. ControlNet experiments further confirm that controllability tracks condition preservation rather than gFID. Overall, our results expose a gap between ImageNet-centric AE evaluation and the requirements of scalable controllable diffusion, offering practical guidance for more reliable benchmarking and model selection.
Exploring Position Encoding in Diffusion U-Net for Training-free High-resolution Image Generation
Mar 12, 2025



Denoising higher-resolution latents via a pre-trained U-Net leads to repetitive and disordered image patterns. Although recent studies make efforts to improve generative quality by aligning denoising process across original and higher resolutions, the root cause of suboptimal generation is still lacking exploration. Through comprehensive analysis of position encoding in U-Net, we attribute it to inconsistent position encoding, sourced by the inadequate propagation of position information from zero-padding to latent features in convolution layers as resolution increases. To address this issue, we propose a novel training-free approach, introducing a Progressive Boundary Complement (PBC) method. This method creates dynamic virtual image boundaries inside the feature map to enhance position information propagation, enabling high-quality and rich-content high-resolution image synthesis. Extensive experiments demonstrate the superiority of our method.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024

We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Oct 17, 2024



In this paper, we introduce Janus, an autoregressive framework that unifies multimodal understanding and generation. Prior research often relies on a single visual encoder for both tasks, such as Chameleon. However, due to the differing levels of information granularity required by multimodal understanding and generation, this approach can lead to suboptimal performance, particularly in multimodal understanding. To address this issue, we decouple visual encoding into separate pathways, while still leveraging a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder's roles in understanding and generation, but also enhances the framework's flexibility. For instance, both the multimodal understanding and generation components can independently select their most suitable encoding methods. Experiments show that Janus surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
MacDiff: Unified Skeleton Modeling with Masked Conditional Diffusion
Sep 16, 2024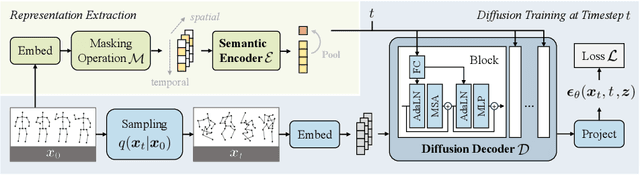
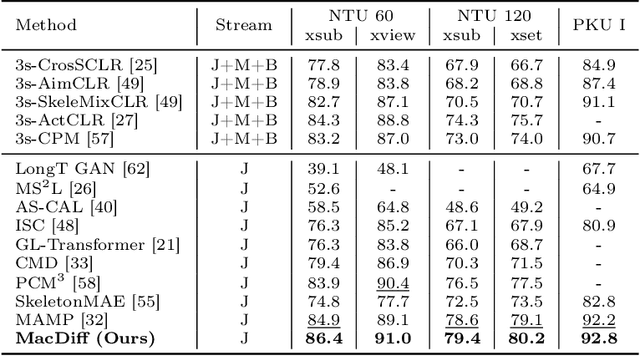
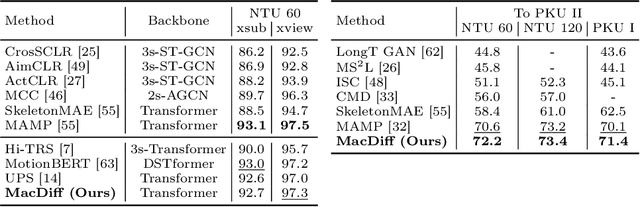
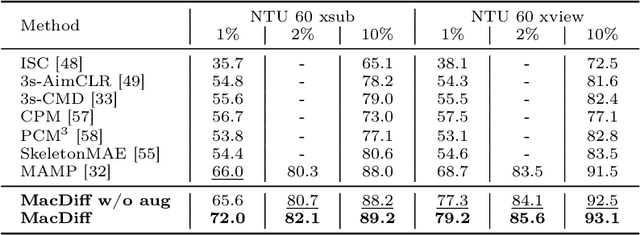
Self-supervised learning has proved effective for skeleton-based human action understanding. However, previous works either rely on contrastive learning that suffers false negative problems or are based on reconstruction that learns too much unessential low-level clues, leading to limited representations for downstream tasks. Recently, great advances have been made in generative learning, which is naturally a challenging yet meaningful pretext task to model the general underlying data distributions. However, the representation learning capacity of generative models is under-explored, especially for the skeletons with spacial sparsity and temporal redundancy. To this end, we propose Masked Conditional Diffusion (MacDiff) as a unified framework for human skeleton modeling. For the first time, we leverage diffusion models as effective skeleton representation learners. Specifically, we train a diffusion decoder conditioned on the representations extracted by a semantic encoder. Random masking is applied to encoder inputs to introduce a information bottleneck and remove redundancy of skeletons. Furthermore, we theoretically demonstrate that our generative objective involves the contrastive learning objective which aligns the masked and noisy views. Meanwhile, it also enforces the representation to complement for the noisy view, leading to better generalization performance. MacDiff achieves state-of-the-art performance on representation learning benchmarks while maintaining the competence for generative tasks. Moreover, we leverage the diffusion model for data augmentation, significantly enhancing the fine-tuning performance in scenarios with scarce labeled data. Our project is available at https://lehongwu.github.io/ECCV24MacDiff/.
Correcting Diffusion-Based Perceptual Image Compression with Privileged End-to-End Decoder
Apr 07, 2024
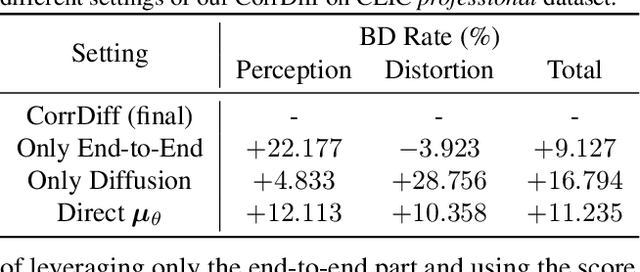
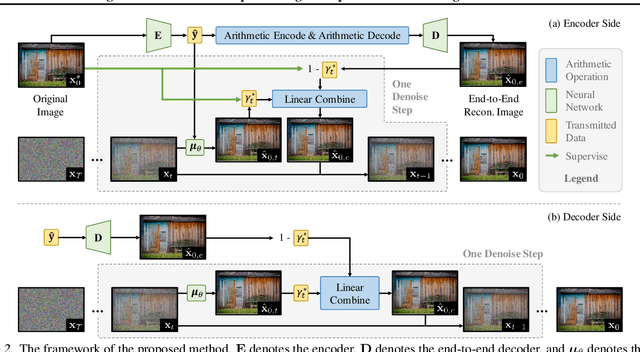

The images produced by diffusion models can attain excellent perceptual quality. However, it is challenging for diffusion models to guarantee distortion, hence the integration of diffusion models and image compression models still needs more comprehensive explorations. This paper presents a diffusion-based image compression method that employs a privileged end-to-end decoder model as correction, which achieves better perceptual quality while guaranteeing the distortion to an extent. We build a diffusion model and design a novel paradigm that combines the diffusion model and an end-to-end decoder, and the latter is responsible for transmitting the privileged information extracted at the encoder side. Specifically, we theoretically analyze the reconstruction process of the diffusion models at the encoder side with the original images being visible. Based on the analysis, we introduce an end-to-end convolutional decoder to provide a better approximation of the score function $\nabla_{\mathbf{x}_t}\log p(\mathbf{x}_t)$ at the encoder side and effectively transmit the combination. Experiments demonstrate the superiority of our method in both distortion and perception compared with previous perceptual compression methods.
Diffusion Enhancement for Cloud Removal in Ultra-Resolution Remote Sensing Imagery
Jan 25, 2024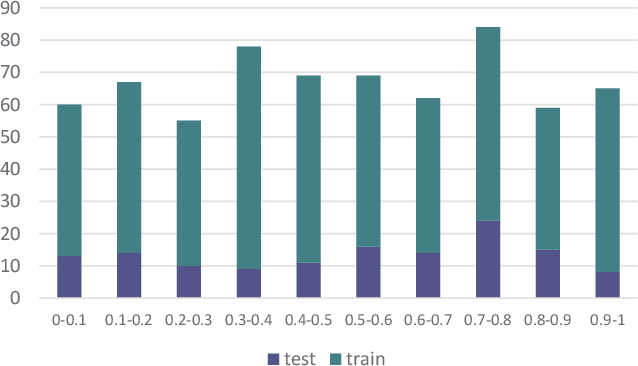
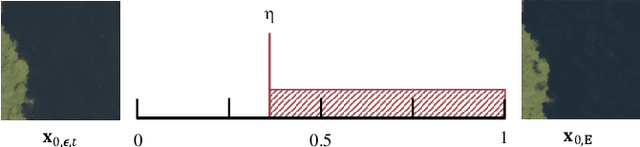
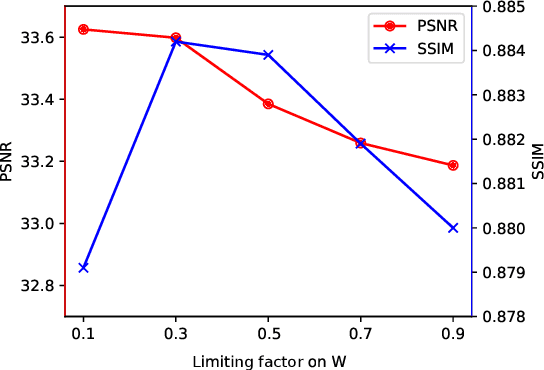
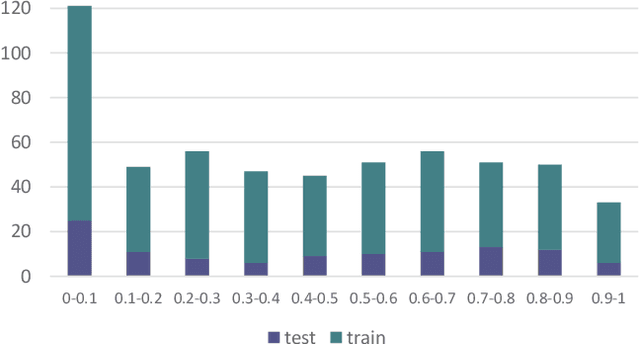
The presence of cloud layers severely compromises the quality and effectiveness of optical remote sensing (RS) images. However, existing deep-learning (DL)-based Cloud Removal (CR) techniques encounter difficulties in accurately reconstructing the original visual authenticity and detailed semantic content of the images. To tackle this challenge, this work proposes to encompass enhancements at the data and methodology fronts. On the data side, an ultra-resolution benchmark named CUHK Cloud Removal (CUHK-CR) of 0.5m spatial resolution is established. This benchmark incorporates rich detailed textures and diverse cloud coverage, serving as a robust foundation for designing and assessing CR models. From the methodology perspective, a novel diffusion-based framework for CR called Diffusion Enhancement (DE) is proposed to perform progressive texture detail recovery, which mitigates the training difficulty with improved inference accuracy. Additionally, a Weight Allocation (WA) network is developed to dynamically adjust the weights for feature fusion, thereby further improving performance, particularly in the context of ultra-resolution image generation. Furthermore, a coarse-to-fine training strategy is applied to effectively expedite training convergence while reducing the computational complexity required to handle ultra-resolution images. Extensive experiments on the newly established CUHK-CR and existing datasets such as RICE confirm that the proposed DE framework outperforms existing DL-based methods in terms of both perceptual quality and signal fidelity.
Solving Diffusion ODEs with Optimal Boundary Conditions for Better Image Super-Resolution
May 24, 2023Diffusion models, as a kind of powerful generative model, have given impressive results on image super-resolution (SR) tasks. However, due to the randomness introduced in the reverse process of diffusion models, the performances of diffusion-based SR models are fluctuating at every time of sampling, especially for samplers with few resampled steps. This inherent randomness of diffusion models results in ineffectiveness and instability, making it challenging for users to guarantee the quality of SR results. However, our work takes this randomness as an opportunity: fully analyzing and leveraging it leads to the construction of an effective plug-and-play sampling method that owns the potential to benefit a series of diffusion-based SR methods. More in detail, we propose to steadily sample high-quality SR images from pretrained diffusion-based SR models by solving diffusion ordinary differential equations (diffusion ODEs) with optimal boundary conditions (BCs) and analyze the characteristics between the choices of BCs and their corresponding SR results. Our analysis shows the route to obtain an approximately optimal BC via an efficient exploration in the whole space. The quality of SR results sampled by the proposed method with fewer steps outperforms the quality of results sampled by current methods with randomness from the same pretrained diffusion-based SR model, which means that our sampling method ``boosts'' current diffusion-based SR models without any additional training.