 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Modal Latent Diffusion for Joint Subject and Text Conditional Image Generation
Paper and Code
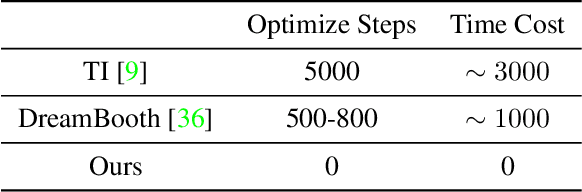
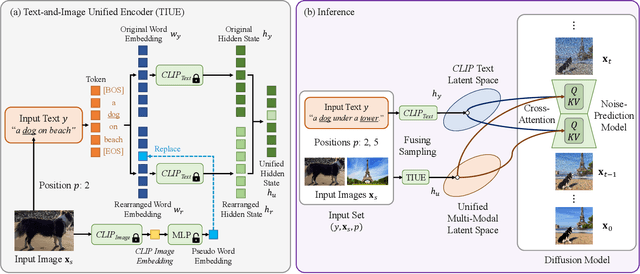


Language-guided image generation has achieved great success nowadays by using diffusion models. However, texts can be less detailed to describe highly-specific subjects such as a particular dog or a certain car, which makes pure text-to-image generation not accurate enough to satisfy user requirements. In this work, we present a novel Unified Multi-Modal Latent Diffusion (UMM-Diffusion) which takes joint texts and images containing specified subjects as input sequences and generates customized images with the subjects. To be more specific, both input texts and images are encoded into one unified multi-modal latent space, in which the input images are learned to be projected to pseudo word embedding and can be further combined with text to guide image generation. Besides, to eliminate the irrelevant parts of the input images such as background or illumination, we propose a novel sampling technique of diffusion models used by the image generator which fuses the results guided by multi-modal input and pure text input. By leveraging the large-scale pre-trained text-to-image generator and the designed image encoder, our method is able to generate high-quality images with complex semantics from both aspects of input texts and images.