 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Understanding to Erasing: Towards Complete and Stable Video Object Removal
Apr 02, 2026Video object removal aims to eliminate target objects from videos while plausibly completing missing regions and preserving spatio-temporal consistency. Although diffusion models have recently advanced this task, it remains challenging to remove object-induced side effects (e.g., shadows, reflections, and illumination changes) without compromising overall coherence. This limitation stems from the insufficient physical and semantic understanding of the target object and its interactions with the scene. In this paper, we propose to introduce understanding into erasing from two complementary perspectives. Externally, we introduce a distillation scheme that transfers the relationships between objects and their induced effects from vision foundation models to video diffusion models. Internally, we propose a framewise context cross-attention mechanism that grounds each denoising block in informative, unmasked context surrounding the target region. External and internal guidance jointly enable our model to understand the target object, its induced effects, and the global background context, resulting in clear and coherent object removal. Extensive experiments demonstrate our state-of-the-art performance, and we establish the first real-world benchmark for video object removal to facilitate future research and community progress. Our code, data, and models are available at: https://github.com/WeChatCV/UnderEraser.
SECURE: Stable Early Collision Understanding via Robust Embeddings in Autonomous Driving
Apr 01, 2026While deep learning has significantly advanced accident anticipation, the robustness of these safety-critical systems against real-world perturbations remains a major challenge. We reveal that state-of-the-art models like CRASH, despite their high performance, exhibit significant instability in predictions and latent representations when faced with minor input perturbations, posing serious reliability risks. To address this, we introduce SECURE - Stable Early Collision Understanding Robust Embeddings, a framework that formally defines and enforces model robustness. SECURE is founded on four key attributes: consistency and stability in both prediction space and latent feature space. We propose a principled training methodology that fine-tunes a baseline model using a multi-objective loss, which minimizes divergence from a reference model and penalizes sensitivity to adversarial perturbations. Experiments on DAD and CCD datasets demonstrate that our approach not only significantly enhances robustness against various perturbations but also improves performance on clean data, achieving new state-of-the-art results.
Identity as Presence: Towards Appearance and Voice Personalized Joint Audio-Video Generation
Mar 18, 2026Recent advances have demonstrated compelling capabilities in synthesizing real individuals into generated videos, reflecting the growing demand for identity-aware content creation. Nevertheless, an openly accessible framework enabling fine-grained control over facial appearance and voice timbre across multiple identities remains unavailable. In this work, we present a unified and scalable framework for identity-aware joint audio-video generation, enabling high-fidelity and consistent personalization. Specifically, we introduce a data curation pipeline that automatically extracts identity-bearing information with paired annotations across audio and visual modalities, covering diverse scenarios from single-subject to multi-subject interactions. We further propose a flexible and scalable identity injection mechanism for single- and multi-subject scenarios, in which both facial appearance and vocal timbre act as identity-bearing control signals. Moreover, in light of modality disparity, we design a multi-stage training strategy to accelerate convergence and enforce cross-modal coherence. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our webpage: \href{https://chen-yingjie.github.io/projects/Identity-as-Presence}{Identity-as-Presence}.
Enhancing WiFi CSI Fingerprinting: A Deep Auxiliary Learning Approach
Oct 26, 2025Radio frequency (RF) fingerprinting techniques provide a promising supplement to cryptography-based approaches but rely on dedicated equipment to capture in-phase and quadrature (IQ) samples, hindering their wide adoption. Recent advances advocate easily obtainable channel state information (CSI) by commercial WiFi devices for lightweight RF fingerprinting, while falling short in addressing the challenges of coarse granularity of CSI measurements in an open-world setting. In this paper, we propose CSI2Q, a novel CSI fingerprinting system that achieves comparable performance to IQ-based approaches. Instead of extracting fingerprints directly from raw CSI measurements, CSI2Q first transforms frequency-domain CSI measurements into time-domain signals that share the same feature space with IQ samples. Then, we employ a deep auxiliary learning strategy to transfer useful knowledge from an IQ fingerprinting model to the CSI counterpart. Finally, the trained CSI model is combined with an OpenMax function to estimate the likelihood of unknown ones. We evaluate CSI2Q on one synthetic CSI dataset involving 85 devices and two real CSI datasets, including 10 and 25 WiFi routers, respectively. Our system achieves accuracy increases of at least 16% on the synthetic CSI dataset, 20% on the in-lab CSI dataset, and 17% on the in-the-wild CSI dataset.
Stand-In: A Lightweight and Plug-and-Play Identity Control for Video Generation
Aug 12, 2025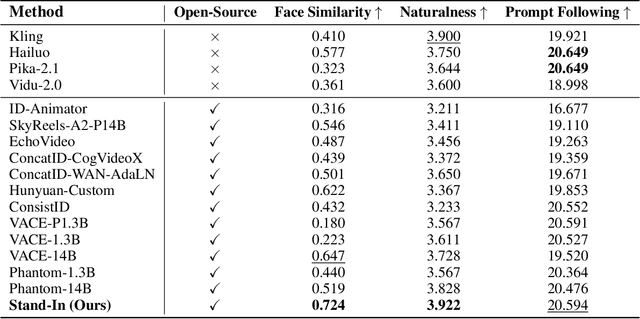
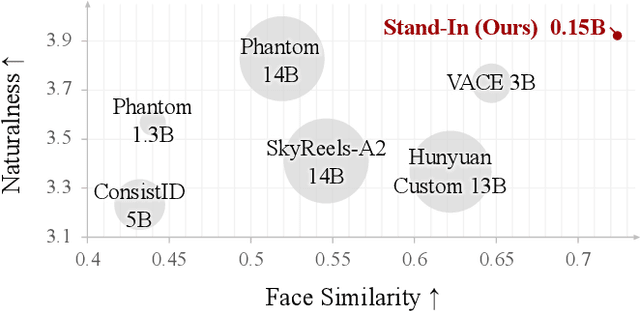
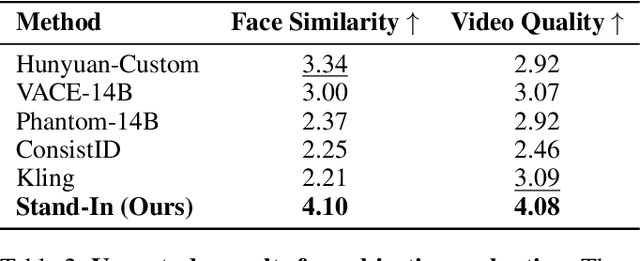

Generating high-fidelity human videos that match user-specified identities is important yet challenging in the field of generative AI. Existing methods often rely on an excessive number of training parameters and lack compatibility with other AIGC tools. In this paper, we propose Stand-In, a lightweight and plug-and-play framework for identity preservation in video generation. Specifically, we introduce a conditional image branch into the pre-trained video generation model. Identity control is achieved through restricted self-attentions with conditional position mapping, and can be learned quickly with only 2000 pairs. Despite incorporating and training just $\sim$1% additional parameters, our framework achieves excellent results in video quality and identity preservation, outperforming other full-parameter training methods. Moreover, our framework can be seamlessly integrated for other tasks, such as subject-driven video generation, pose-referenced video generation, stylization, and face swapping.
DECO: Life-Cycle Management of Enterprise-Grade Chatbots
Dec 08, 2024



Software engineers frequently grapple with the challenge of accessing disparate documentation and telemetry data, including Troubleshooting Guides (TSGs), incident reports, code repositories, and various internal tools developed by multiple stakeholders. While on-call duties are inevitable, incident resolution becomes even more daunting due to the obscurity of legacy sources and the pressures of strict time constraints. To enhance the efficiency of on-call engineers (OCEs) and streamline their daily workflows, we introduced DECO -- a comprehensive framework for developing, deploying, and managing enterprise-grade chatbots tailored to improve productivity in engineering routines. This paper details the design and implementation of the DECO framework, emphasizing its innovative NL2SearchQuery functionality and a hierarchical planner. These features support efficient and customized retrieval-augmented-generation (RAG) algorithms that not only extract relevant information from diverse sources but also select the most pertinent toolkits in response to user queries. This enables the addressing of complex technical questions and provides seamless, automated access to internal resources. Additionally, DECO incorporates a robust mechanism for converting unstructured incident logs into user-friendly, structured guides, effectively bridging the documentation gap. Feedback from users underscores DECO's pivotal role in simplifying complex engineering tasks, accelerating incident resolution, and bolstering organizational productivity. Since its launch in September 2023, DECO has demonstrated its effectiveness through extensive engagement, with tens of thousands of interactions from hundreds of active users across multiple organizations within the company.
Zero-Reference Low-Light Enhancement via Physical Quadruple Priors
Mar 19, 2024



Understanding illumination and reducing the need for supervision pose a significant challenge in low-light enhancement. Current approaches are highly sensitive to data usage during training and illumination-specific hyper-parameters, limiting their ability to handle unseen scenarios. In this paper, we propose a new zero-reference low-light enhancement framework trainable solely with normal light images. To accomplish this, we devise an illumination-invariant prior inspired by the theory of physical light transfer. This prior serves as the bridge between normal and low-light images. Then, we develop a prior-to-image framework trained without low-light data. During testing, this framework is able to restore our illumination-invariant prior back to images, automatically achieving low-light enhancement. Within this framework, we leverage a pretrained generative diffusion model for model ability, introduce a bypass decoder to handle detail distortion, as well as offer a lightweight version for practicality. Extensive experiments demonstrate our framework's superiority in various scenarios as well as good interpretability, robustness, and efficiency. Code is available on our project homepage: http://daooshee.github.io/QuadPrior-Website/
Open-Set Facial Expression Recognition
Jan 23, 2024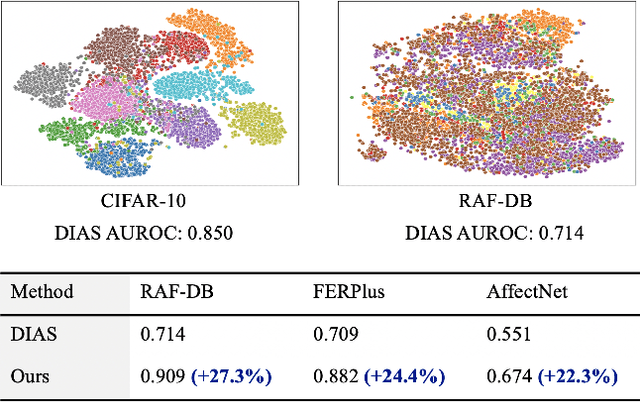
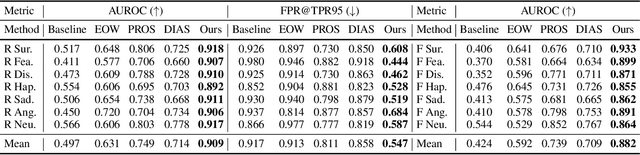
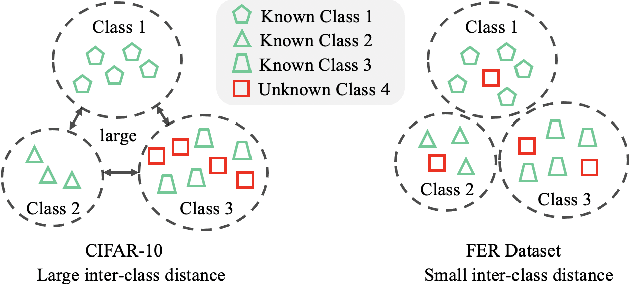
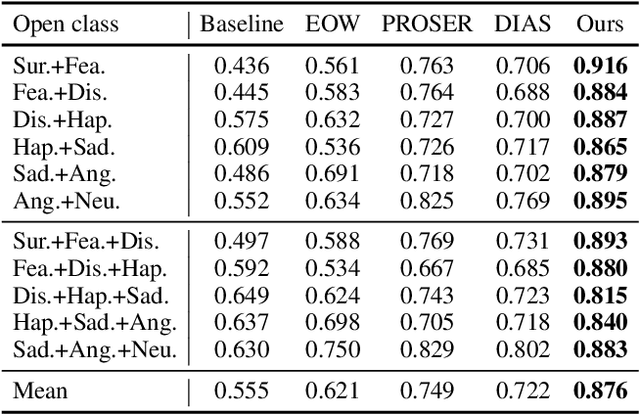
Facial expression recognition (FER) models are typically trained on datasets with a fixed number of seven basic classes. However, recent research works point out that there are far more expressions than the basic ones. Thus, when these models are deployed in the real world, they may encounter unknown classes, such as compound expressions that cannot be classified into existing basic classes. To address this issue, we propose the open-set FER task for the first time. Though there are many existing open-set recognition methods, we argue that they do not work well for open-set FER because FER data are all human faces with very small inter-class distances, which makes the open-set samples very similar to close-set samples. In this paper, we are the first to transform the disadvantage of small inter-class distance into an advantage by proposing a new way for open-set FER. Specifically, we find that small inter-class distance allows for sparsely distributed pseudo labels of open-set samples, which can be viewed as symmetric noisy labels. Based on this novel observation, we convert the open-set FER to a noisy label detection problem. We further propose a novel method that incorporates attention map consistency and cycle training to detect the open-set samples. Extensive experiments on various FER datasets demonstrate that our method clearly outperforms state-of-the-art open-set recognition methods by large margins. Code is available at https://github.com/zyh-uaiaaaa.
MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Jul 31, 2023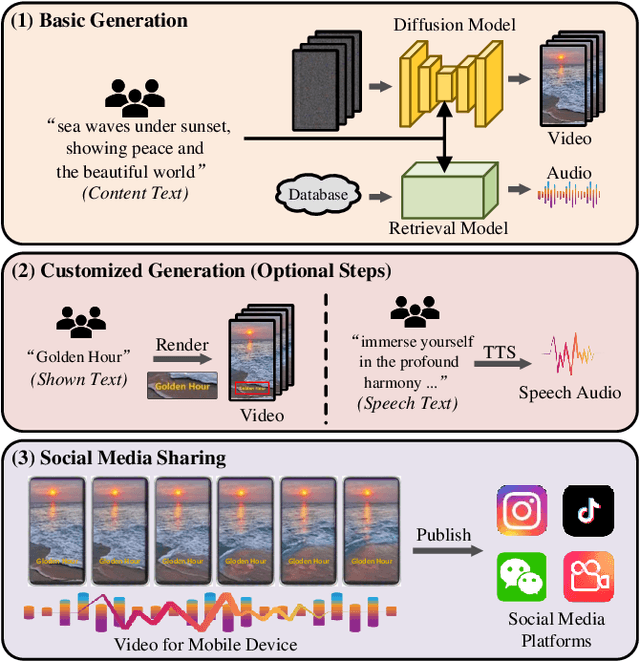

Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users' creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
Similarity Min-Max: Zero-Shot Day-Night Domain Adaptation
Jul 19, 2023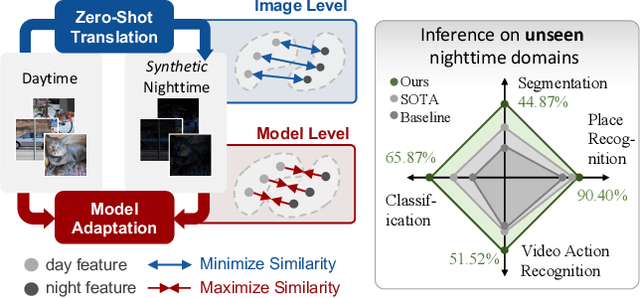
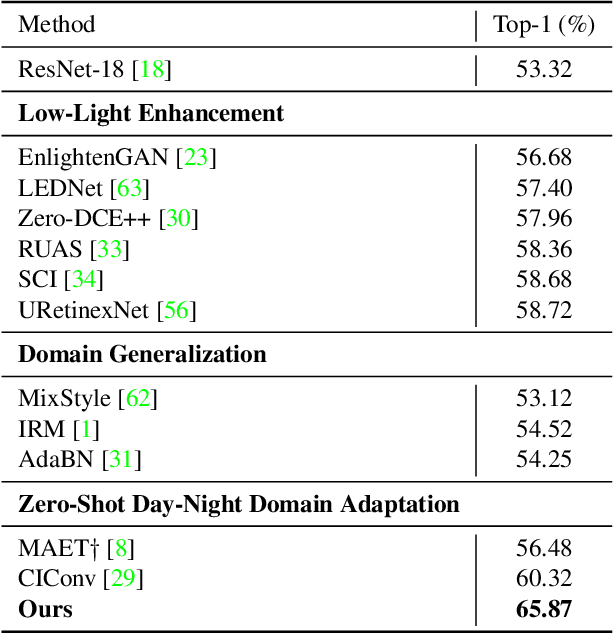
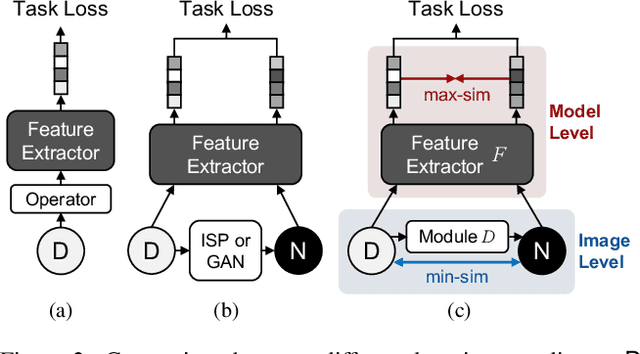
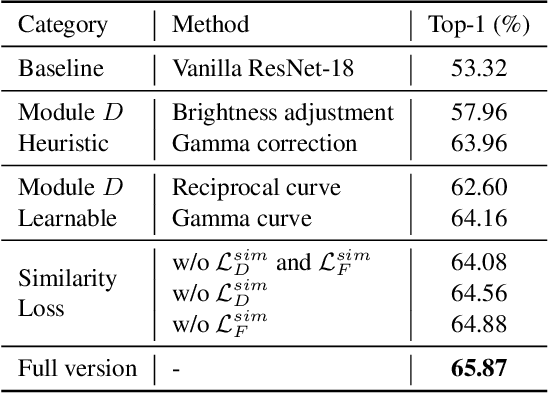
Low-light conditions not only hamper human visual experience but also degrade the model's performance on downstream vision tasks. While existing works make remarkable progress on day-night domain adaptation, they rely heavily on domain knowledge derived from the task-specific nighttime dataset. This paper challenges a more complicated scenario with border applicability, i.e., zero-shot day-night domain adaptation, which eliminates reliance on any nighttime data. Unlike prior zero-shot adaptation approaches emphasizing either image-level translation or model-level adaptation, we propose a similarity min-max paradigm that considers them under a unified framework. On the image level, we darken images towards minimum feature similarity to enlarge the domain gap. Then on the model level, we maximize the feature similarity between the darkened images and their normal-light counterparts for better model adaptation. To the best of our knowledge, this work represents the pioneering effort in jointly optimizing both aspects, resulting in a significant improvement of model generalizability. Extensive experiments demonstrate our method's effectiveness and broad applicability on various nighttime vision tasks, including classification, semantic segmentation, visual place recognition, and video action recognition. Code and pre-trained models are available at https://red-fairy.github.io/ZeroShotDayNightDA-Webpage/.