 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCha:End-to-End Video Character Replacement without Structural Guidance
Jan 14, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
End-to-End Video Character Replacement without Structural Guidance
Jan 13, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
Frequency-Controlled Diffusion Model for Versatile Text-Guided Image-to-Image Translation
Jul 03, 2024



Recently, large-scale text-to-image (T2I) diffusion models have emerged as a powerful tool for image-to-image translation (I2I), allowing open-domain image translation via user-provided text prompts. This paper proposes frequency-controlled diffusion model (FCDiffusion), an end-to-end diffusion-based framework that contributes a novel solution to text-guided I2I from a frequency-domain perspective. At the heart of our framework is a feature-space frequency-domain filtering module based on Discrete Cosine Transform, which filters the latent features of the source image in the DCT domain, yielding filtered image features bearing different DCT spectral bands as different control signals to the pre-trained Latent Diffusion Model. We reveal that control signals of different DCT spectral bands bridge the source image and the T2I generated image in different correlations (e.g., style, structure, layout, contour, etc.), and thus enable versatile I2I applications emphasizing different I2I correlations, including style-guided content creation, image semantic manipulation, image scene translation, and image style translation. Different from related approaches, FCDiffusion establishes a unified text-guided I2I framework suitable for diverse image translation tasks simply by switching among different frequency control branches at inference time. The effectiveness and superiority of our method for text-guided I2I are demonstrated with extensive experiments both qualitatively and quantitatively. The code is publicly available at: https://github.com/XiangGao1102/FCDiffusion.
* Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI 2024)
Self-Aligned Concave Curve: Illumination Enhancement for Unsupervised Adaptation
Oct 07, 2022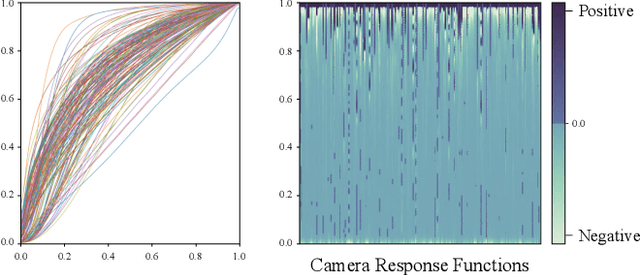
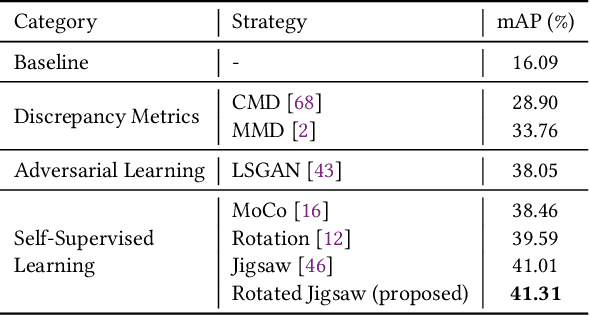
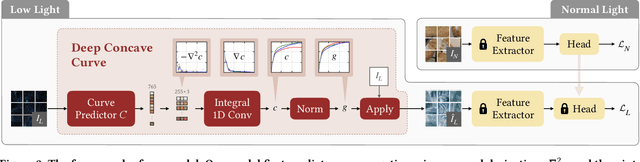

Low light conditions not only degrade human visual experience, but also reduce the performance of downstream machine analytics. Although many works have been designed for low-light enhancement or domain adaptive machine analytics, the former considers less on high-level vision, while the latter neglects the potential of image-level signal adjustment. How to restore underexposed images/videos from the perspective of machine vision has long been overlooked. In this paper, we are the first to propose a learnable illumination enhancement model for high-level vision. Inspired by real camera response functions, we assume that the illumination enhancement function should be a concave curve, and propose to satisfy this concavity through discrete integral. With the intention of adapting illumination from the perspective of machine vision without task-specific annotated data, we design an asymmetric cross-domain self-supervised training strategy. Our model architecture and training designs mutually benefit each other, forming a powerful unsupervised normal-to-low light adaptation framework. Comprehensive experiments demonstrate that our method surpasses existing low-light enhancement and adaptation methods and shows superior generalization on various low-light vision tasks, including classification, detection, action recognition, and optical flow estimation. Project website: https://daooshee.github.io/SACC-Website/