 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGait Recognition Based on Tiny ML and IMU Sensors
Jul 24, 2025


This project presents the development of a gait recognition system using Tiny Machine Learning (Tiny ML) and Inertial Measurement Unit (IMU) sensors. The system leverages the XIAO-nRF52840 Sense microcontroller and the LSM6DS3 IMU sensor to capture motion data, including acceleration and angular velocity, from four distinct activities: walking, stationary, going upstairs, and going downstairs. The data collected is processed through Edge Impulse, an edge AI platform, which enables the training of machine learning models that can be deployed directly onto the microcontroller for real-time activity classification.The data preprocessing step involves extracting relevant features from the raw sensor data using techniques such as sliding windows and data normalization, followed by training a Deep Neural Network (DNN) classifier for activity recognition. The model achieves over 80% accuracy on a test dataset, demonstrating its ability to classify the four activities effectively. Additionally, the platform enables anomaly detection, further enhancing the robustness of the system. The integration of Tiny ML ensures low-power operation, making it suitable for battery-powered or energy-harvesting devices.
Idempotent Unsupervised Representation Learning for Skeleton-Based Action Recognition
Oct 27, 2024Generative models, as a powerful technique for generation, also gradually become a critical tool for recognition tasks. However, in skeleton-based action recognition, the features obtained from existing pre-trained generative methods contain redundant information unrelated to recognition, which contradicts the nature of the skeleton's spatially sparse and temporally consistent properties, leading to undesirable performance. To address this challenge, we make efforts to bridge the gap in theory and methodology and propose a novel skeleton-based idempotent generative model (IGM) for unsupervised representation learning. More specifically, we first theoretically demonstrate the equivalence between generative models and maximum entropy coding, which demonstrates a potential route that makes the features of generative models more compact by introducing contrastive learning. To this end, we introduce the idempotency constraint to form a stronger consistency regularization in the feature space, to push the features only to maintain the critical information of motion semantics for the recognition task. Our extensive experiments on benchmark datasets, NTU RGB+D and PKUMMD, demonstrate the effectiveness of our proposed method. On the NTU 60 xsub dataset, we observe a performance improvement from 84.6$\%$ to 86.2$\%$. Furthermore, in zero-shot adaptation scenarios, our model demonstrates significant efficacy by achieving promising results in cases that were previously unrecognizable. Our project is available at \url{https://github.com/LanglandsLin/IGM}.
MacDiff: Unified Skeleton Modeling with Masked Conditional Diffusion
Sep 16, 2024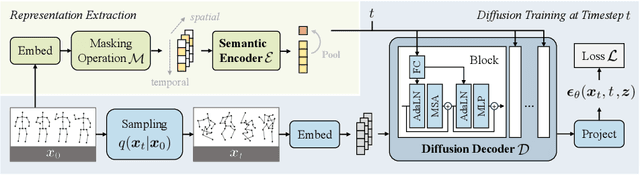
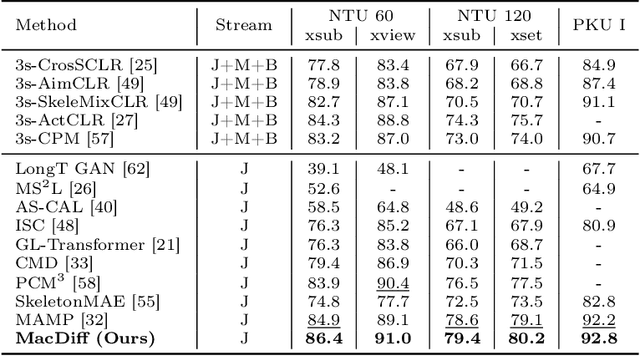
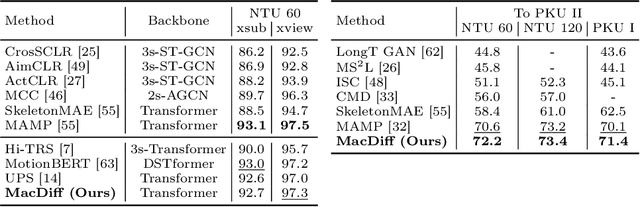
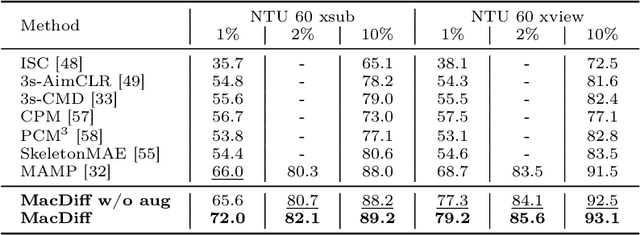
Self-supervised learning has proved effective for skeleton-based human action understanding. However, previous works either rely on contrastive learning that suffers false negative problems or are based on reconstruction that learns too much unessential low-level clues, leading to limited representations for downstream tasks. Recently, great advances have been made in generative learning, which is naturally a challenging yet meaningful pretext task to model the general underlying data distributions. However, the representation learning capacity of generative models is under-explored, especially for the skeletons with spacial sparsity and temporal redundancy. To this end, we propose Masked Conditional Diffusion (MacDiff) as a unified framework for human skeleton modeling. For the first time, we leverage diffusion models as effective skeleton representation learners. Specifically, we train a diffusion decoder conditioned on the representations extracted by a semantic encoder. Random masking is applied to encoder inputs to introduce a information bottleneck and remove redundancy of skeletons. Furthermore, we theoretically demonstrate that our generative objective involves the contrastive learning objective which aligns the masked and noisy views. Meanwhile, it also enforces the representation to complement for the noisy view, leading to better generalization performance. MacDiff achieves state-of-the-art performance on representation learning benchmarks while maintaining the competence for generative tasks. Moreover, we leverage the diffusion model for data augmentation, significantly enhancing the fine-tuning performance in scenarios with scarce labeled data. Our project is available at https://lehongwu.github.io/ECCV24MacDiff/.
Shap-Mix: Shapley Value Guided Mixing for Long-Tailed Skeleton Based Action Recognition
Jul 17, 2024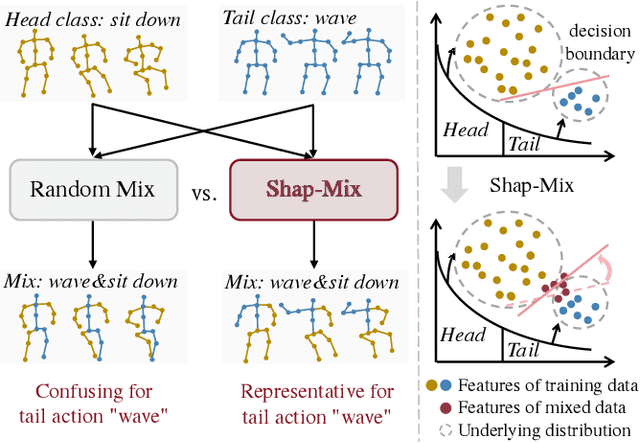
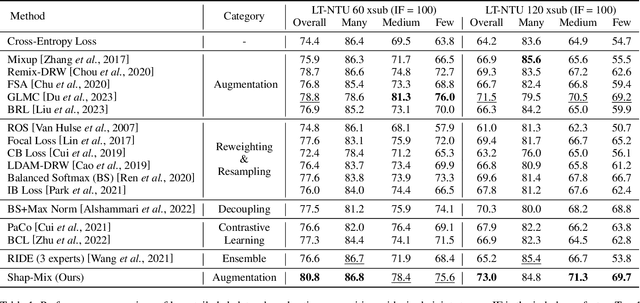
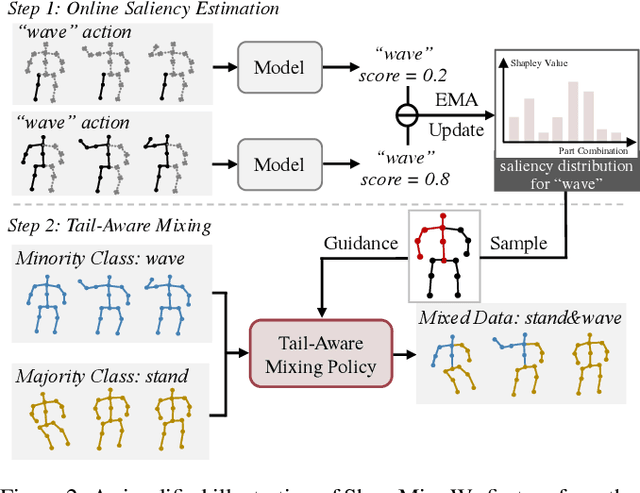

In real-world scenarios, human actions often fall into a long-tailed distribution. It makes the existing skeleton-based action recognition works, which are mostly designed based on balanced datasets, suffer from a sharp performance degradation. Recently, many efforts have been madeto image/video long-tailed learning. However, directly applying them to skeleton data can be sub-optimal due to the lack of consideration of the crucial spatial-temporal motion patterns, especially for some modality-specific methodologies such as data augmentation. To this end, considering the crucial role of the body parts in the spatially concentrated human actions, we attend to the mixing augmentations and propose a novel method, Shap-Mix, which improves long-tailed learning by mining representative motion patterns for tail categories. Specifically, we first develop an effective spatial-temporal mixing strategy for the skeleton to boost representation quality. Then, the employed saliency guidance method is presented, consisting of the saliency estimation based on Shapley value and a tail-aware mixing policy. It preserves the salient motion parts of minority classes in mixed data, explicitly establishing the relationships between crucial body structure cues and high-level semantics. Extensive experiments on three large-scale skeleton datasets show our remarkable performance improvement under both long-tailed and balanced settings. Our project is publicly available at: https://jhang2020.github.io/Projects/Shap-Mix/Shap-Mix.html.
Self-Supervised Skeleton Action Representation Learning: A Benchmark and Beyond
Jun 05, 2024Self-supervised learning (SSL), which aims to learn meaningful prior representations from unlabeled data, has been proven effective for label-efficient skeleton-based action understanding. Different from the image domain, skeleton data possesses sparser spatial structures and diverse representation forms, with the absence of background clues and the additional temporal dimension. This presents the new challenges for the pretext task design of spatial-temporal motion representation learning. Recently, many endeavors have been made for skeleton-based SSL and remarkable progress has been achieved. However, a systematic and thorough review is still lacking. In this paper, we conduct, for the first time, a comprehensive survey on self-supervised skeleton-based action representation learning, where various literature is organized according to their pre-training pretext task methodologies. Following the taxonomy of context-based, generative learning, and contrastive learning approaches, we make a thorough review and benchmark of existing works and shed light on the future possible directions. Our investigation demonstrates that most SSL works rely on the single paradigm, learning representations of a single level, and are evaluated on the action recognition task solely, which leaves the generalization power of skeleton SSL models under-explored. To this end, a novel and effective SSL method for skeleton is further proposed, which integrates multiple pretext tasks to jointly learn versatile representations of different granularity, substantially boosting the generalization capacity for different downstream tasks. Extensive experiments under three large-scale datasets demonstrate that the proposed method achieves the superior generalization performance on various downstream tasks, including recognition, retrieval, detection, and few-shot learning.
Prompted Contrast with Masked Motion Modeling: Towards Versatile 3D Action Representation Learning
Aug 08, 2023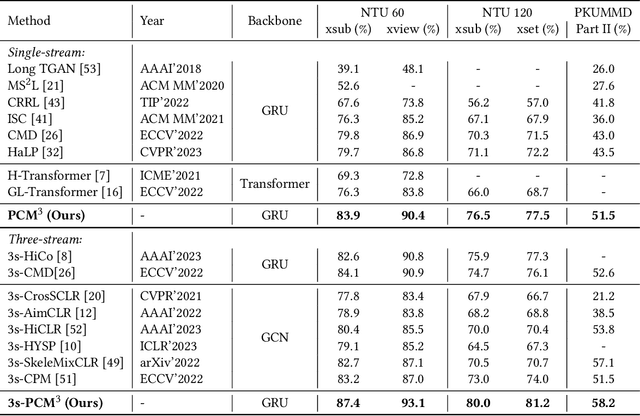
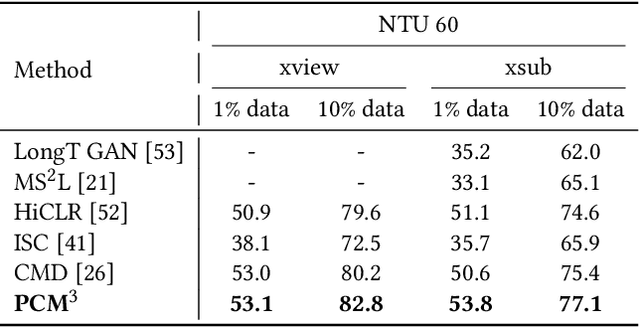
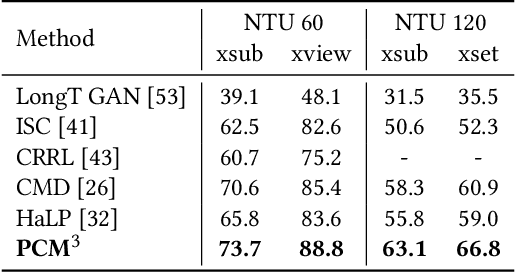
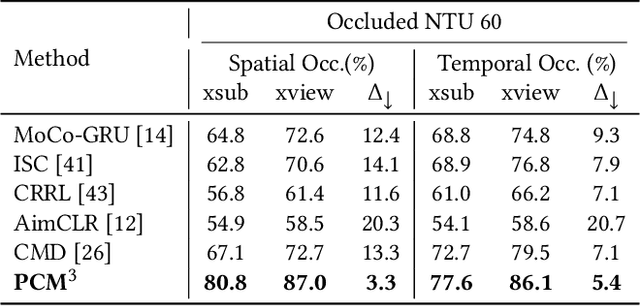
Self-supervised learning has proved effective for skeleton-based human action understanding, which is an important yet challenging topic. Previous works mainly rely on contrastive learning or masked motion modeling paradigm to model the skeleton relations. However, the sequence-level and joint-level representation learning cannot be effectively and simultaneously handled by these methods. As a result, the learned representations fail to generalize to different downstream tasks. Moreover, combining these two paradigms in a naive manner leaves the synergy between them untapped and can lead to interference in training. To address these problems, we propose Prompted Contrast with Masked Motion Modeling, PCM$^{\rm 3}$, for versatile 3D action representation learning. Our method integrates the contrastive learning and masked prediction tasks in a mutually beneficial manner, which substantially boosts the generalization capacity for various downstream tasks. Specifically, masked prediction provides novel training views for contrastive learning, which in turn guides the masked prediction training with high-level semantic information. Moreover, we propose a dual-prompted multi-task pretraining strategy, which further improves model representations by reducing the interference caused by learning the two different pretext tasks. Extensive experiments on five downstream tasks under three large-scale datasets are conducted, demonstrating the superior generalization capacity of PCM$^{\rm 3}$ compared to the state-of-the-art works. Our project is publicly available at: https://jhang2020.github.io/Projects/PCM3/PCM3.html .
Actionlet-Dependent Contrastive Learning for Unsupervised Skeleton-Based Action Recognition
Mar 21, 2023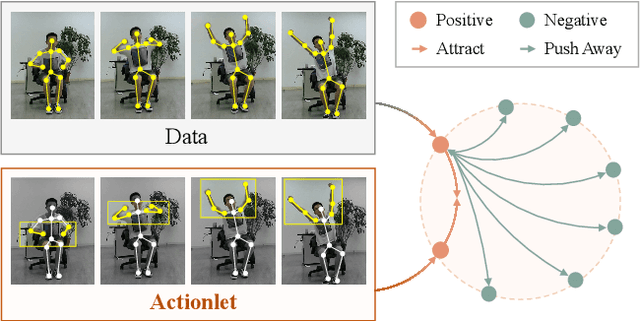
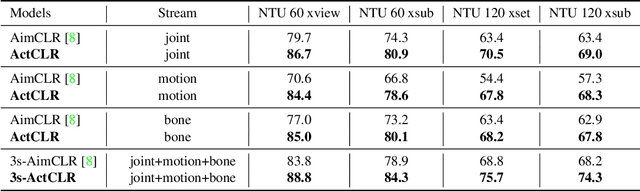
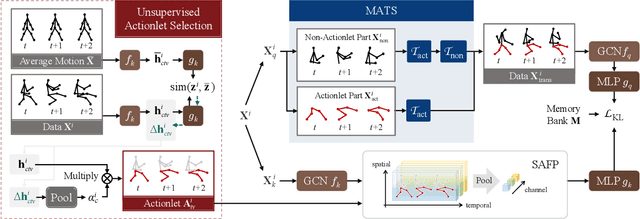
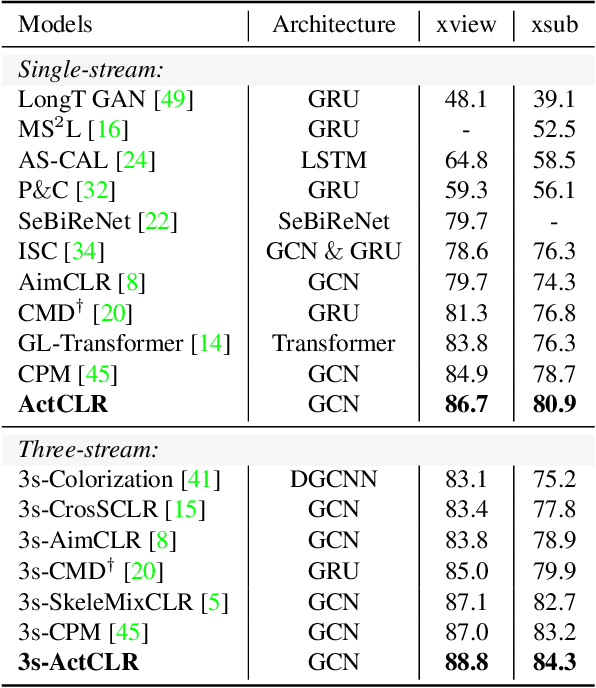
The self-supervised pretraining paradigm has achieved great success in skeleton-based action recognition. However, these methods treat the motion and static parts equally, and lack an adaptive design for different parts, which has a negative impact on the accuracy of action recognition. To realize the adaptive action modeling of both parts, we propose an Actionlet-Dependent Contrastive Learning method (ActCLR). The actionlet, defined as the discriminative subset of the human skeleton, effectively decomposes motion regions for better action modeling. In detail, by contrasting with the static anchor without motion, we extract the motion region of the skeleton data, which serves as the actionlet, in an unsupervised manner. Then, centering on actionlet, a motion-adaptive data transformation method is built. Different data transformations are applied to actionlet and non-actionlet regions to introduce more diversity while maintaining their own characteristics. Meanwhile, we propose a semantic-aware feature pooling method to build feature representations among motion and static regions in a distinguished manner. Extensive experiments on NTU RGB+D and PKUMMD show that the proposed method achieves remarkable action recognition performance. More visualization and quantitative experiments demonstrate the effectiveness of our method. Our project website is available at https://langlandslin.github.io/projects/ActCLR/
Hierarchical Consistent Contrastive Learning for Skeleton-Based Action Recognition with Growing Augmentations
Nov 24, 2022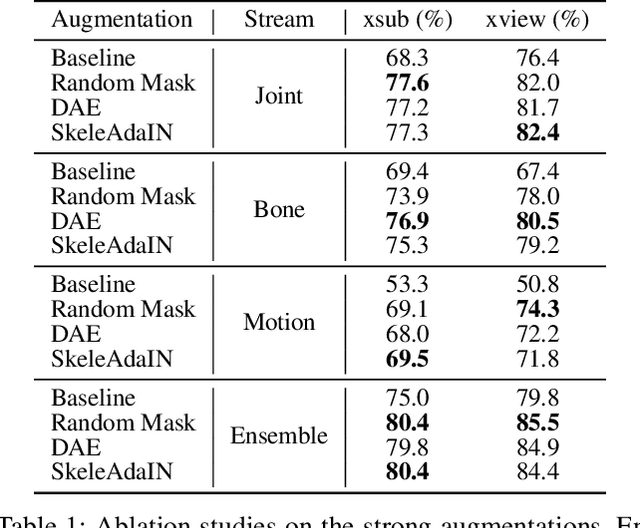
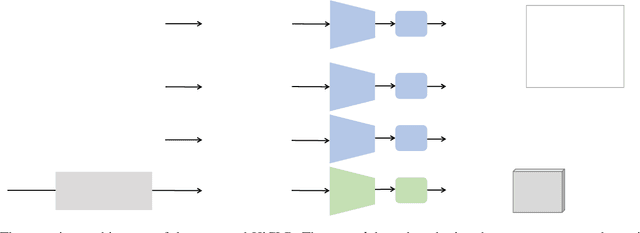

Contrastive learning has been proven beneficial for self-supervised skeleton-based action recognition. Most contrastive learning methods utilize carefully designed augmentations to generate different movement patterns of skeletons for the same semantics. However, it is still a pending issue to apply strong augmentations, which distort the images/skeletons' structures and cause semantic loss, due to their resulting unstable training. In this paper, we investigate the potential of adopting strong augmentations and propose a general hierarchical consistent contrastive learning framework (HiCLR) for skeleton-based action recognition. Specifically, we first design a gradual growing augmentation policy to generate multiple ordered positive pairs, which guide to achieve the consistency of the learned representation from different views. Then, an asymmetric loss is proposed to enforce the hierarchical consistency via a directional clustering operation in the feature space, pulling the representations from strongly augmented views closer to those from weakly augmented views for better generalizability. Meanwhile, we propose and evaluate three kinds of strong augmentations for 3D skeletons to demonstrate the effectiveness of our method. Extensive experiments show that HiCLR outperforms the state-of-the-art methods notably on three large-scale datasets, i.e., NTU60, NTU120, and PKUMMD.
S$^{5}$Mars: Self-Supervised and Semi-Supervised Learning for Mars Segmentation
Jul 04, 2022
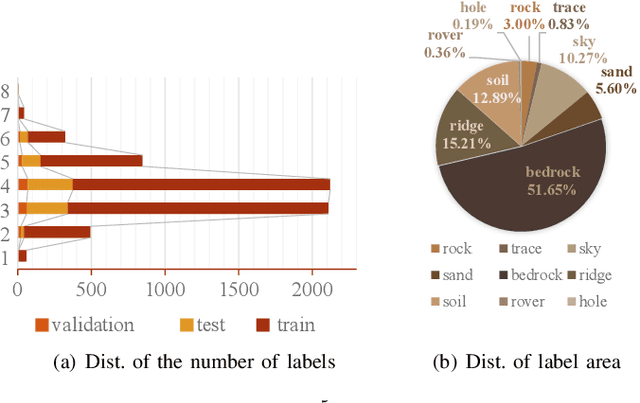
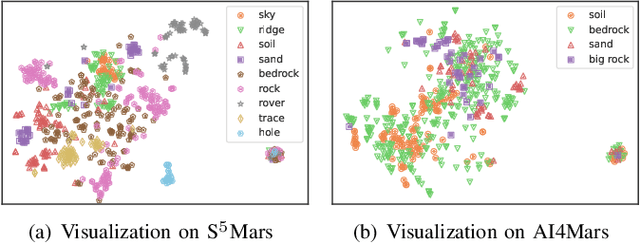
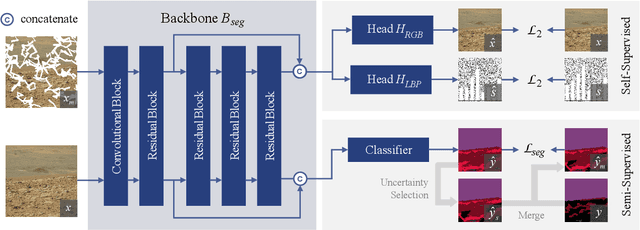
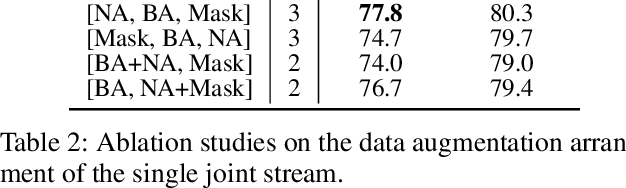
Deep learning has become a powerful tool for Mars exploration. Mars terrain segmentation is an important Martian vision task, which is the base of rover autonomous planning and safe driving. However, existing deep-learning-based terrain segmentation methods face two problems: one is the lack of sufficient detailed and high-confidence annotations, and the other is the over-reliance of models on annotated training data. In this paper, we address these two problems from the perspective of joint data and method design. We first present a new Mars terrain segmentation dataset which contains 6K high-resolution images and is sparsely annotated based on confidence, ensuring the high quality of labels. Then to learn from this sparse data, we propose a representation-learning-based framework for Mars terrain segmentation, including a self-supervised learning stage (for pre-training) and a semi-supervised learning stage (for fine-tuning). Specifically, for self-supervised learning, we design a multi-task mechanism based on the masked image modeling (MIM) concept to emphasize the texture information of images. For semi-supervised learning, since our dataset is sparsely annotated, we encourage the model to excavate the information of unlabeled area in each image by generating and utilizing pseudo-labels online. We name our dataset and method Self-Supervised and Semi-Supervised Segmentation for Mars (S$^{5}$Mars). Experimental results show that our method can outperform state-of-the-art approaches and improve terrain segmentation performance by a large margin.