 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompted Contrast with Masked Motion Modeling: Towards Versatile 3D Action Representation Learning
Paper and Code
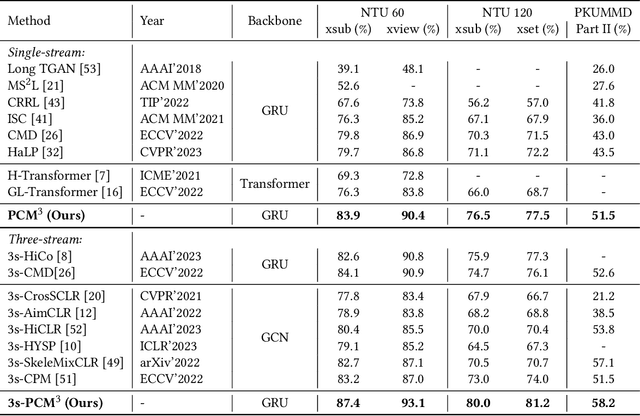
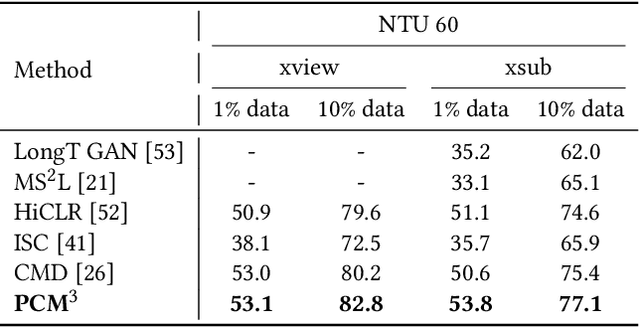
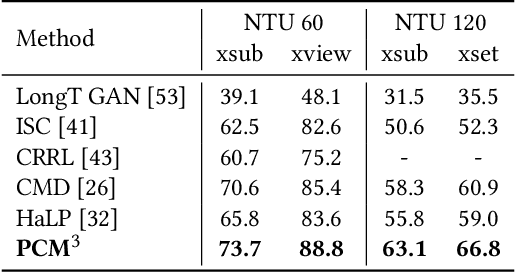
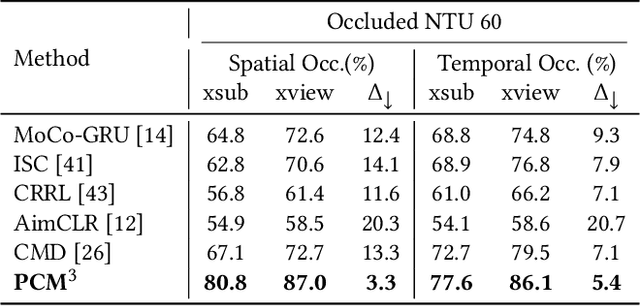
Self-supervised learning has proved effective for skeleton-based human action understanding, which is an important yet challenging topic. Previous works mainly rely on contrastive learning or masked motion modeling paradigm to model the skeleton relations. However, the sequence-level and joint-level representation learning cannot be effectively and simultaneously handled by these methods. As a result, the learned representations fail to generalize to different downstream tasks. Moreover, combining these two paradigms in a naive manner leaves the synergy between them untapped and can lead to interference in training. To address these problems, we propose Prompted Contrast with Masked Motion Modeling, PCM$^{\rm 3}$, for versatile 3D action representation learning. Our method integrates the contrastive learning and masked prediction tasks in a mutually beneficial manner, which substantially boosts the generalization capacity for various downstream tasks. Specifically, masked prediction provides novel training views for contrastive learning, which in turn guides the masked prediction training with high-level semantic information. Moreover, we propose a dual-prompted multi-task pretraining strategy, which further improves model representations by reducing the interference caused by learning the two different pretext tasks. Extensive experiments on five downstream tasks under three large-scale datasets are conducted, demonstrating the superior generalization capacity of PCM$^{\rm 3}$ compared to the state-of-the-art works. Our project is publicly available at: https://jhang2020.github.io/Projects/PCM3/PCM3.html .