 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacDiff: Unified Skeleton Modeling with Masked Conditional Diffusion
Paper and Code
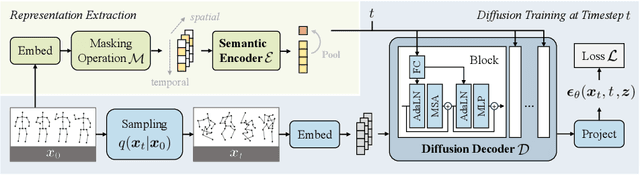
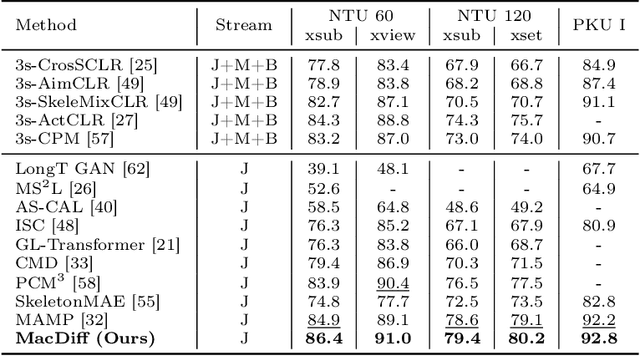
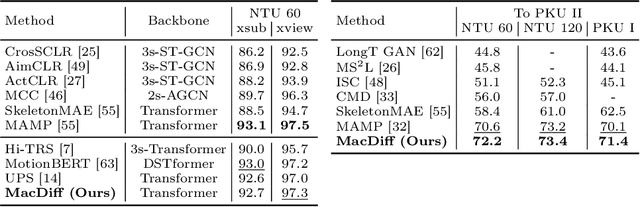
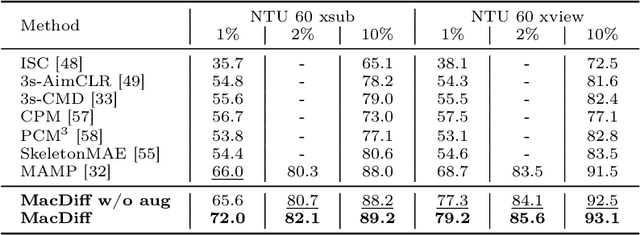
Self-supervised learning has proved effective for skeleton-based human action understanding. However, previous works either rely on contrastive learning that suffers false negative problems or are based on reconstruction that learns too much unessential low-level clues, leading to limited representations for downstream tasks. Recently, great advances have been made in generative learning, which is naturally a challenging yet meaningful pretext task to model the general underlying data distributions. However, the representation learning capacity of generative models is under-explored, especially for the skeletons with spacial sparsity and temporal redundancy. To this end, we propose Masked Conditional Diffusion (MacDiff) as a unified framework for human skeleton modeling. For the first time, we leverage diffusion models as effective skeleton representation learners. Specifically, we train a diffusion decoder conditioned on the representations extracted by a semantic encoder. Random masking is applied to encoder inputs to introduce a information bottleneck and remove redundancy of skeletons. Furthermore, we theoretically demonstrate that our generative objective involves the contrastive learning objective which aligns the masked and noisy views. Meanwhile, it also enforces the representation to complement for the noisy view, leading to better generalization performance. MacDiff achieves state-of-the-art performance on representation learning benchmarks while maintaining the competence for generative tasks. Moreover, we leverage the diffusion model for data augmentation, significantly enhancing the fine-tuning performance in scenarios with scarce labeled data. Our project is available at https://lehongwu.github.io/ECCV24MacDiff/.