 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTac2Pose: A Unified Approach Learned in Simulation for Category-level Visuotactile In-hand Pose Estimation
Sep 19, 2025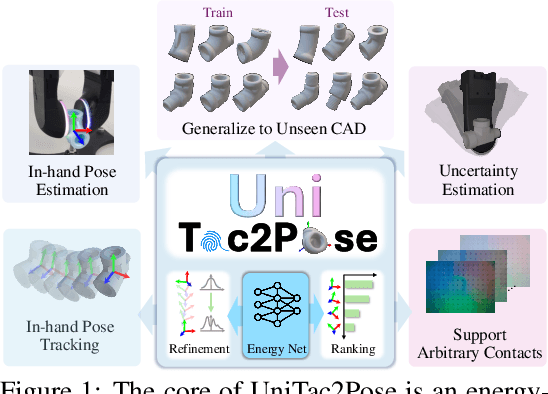
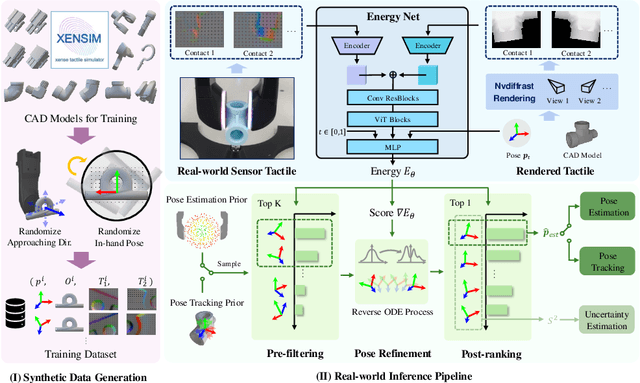

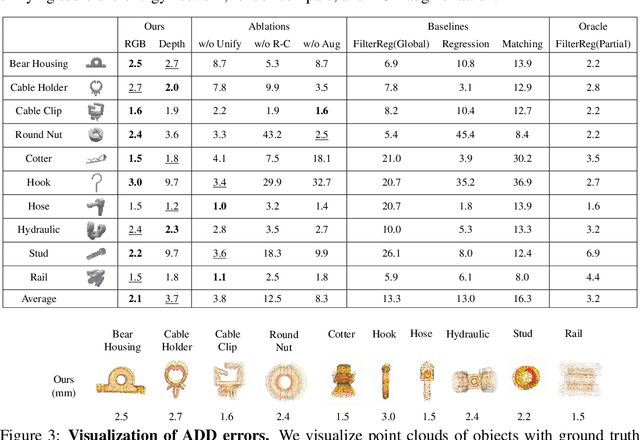
Accurate estimation of the in-hand pose of an object based on its CAD model is crucial in both industrial applications and everyday tasks, ranging from positioning workpieces and assembling components to seamlessly inserting devices like USB connectors. While existing methods often rely on regression, feature matching, or registration techniques, achieving high precision and generalizability to unseen CAD models remains a significant challenge. In this paper, we propose a novel three-stage framework for in-hand pose estimation. The first stage involves sampling and pre-ranking pose candidates, followed by iterative refinement of these candidates in the second stage. In the final stage, post-ranking is applied to identify the most likely pose candidates. These stages are governed by a unified energy-based diffusion model, which is trained solely on simulated data. This energy model simultaneously generates gradients to refine pose estimates and produces an energy scalar that quantifies the quality of the pose estimates. Additionally, borrowing the idea from the computer vision domain, we incorporate a render-compare architecture within the energy-based score network to significantly enhance sim-to-real performance, as demonstrated by our ablation studies. We conduct comprehensive experiments to show that our method outperforms conventional baselines based on regression, matching, and registration techniques, while also exhibiting strong intra-category generalization to previously unseen CAD models. Moreover, our approach integrates tactile object pose estimation, pose tracking, and uncertainty estimation into a unified framework, enabling robust performance across a variety of real-world conditions.
Idempotent Unsupervised Representation Learning for Skeleton-Based Action Recognition
Oct 27, 2024Generative models, as a powerful technique for generation, also gradually become a critical tool for recognition tasks. However, in skeleton-based action recognition, the features obtained from existing pre-trained generative methods contain redundant information unrelated to recognition, which contradicts the nature of the skeleton's spatially sparse and temporally consistent properties, leading to undesirable performance. To address this challenge, we make efforts to bridge the gap in theory and methodology and propose a novel skeleton-based idempotent generative model (IGM) for unsupervised representation learning. More specifically, we first theoretically demonstrate the equivalence between generative models and maximum entropy coding, which demonstrates a potential route that makes the features of generative models more compact by introducing contrastive learning. To this end, we introduce the idempotency constraint to form a stronger consistency regularization in the feature space, to push the features only to maintain the critical information of motion semantics for the recognition task. Our extensive experiments on benchmark datasets, NTU RGB+D and PKUMMD, demonstrate the effectiveness of our proposed method. On the NTU 60 xsub dataset, we observe a performance improvement from 84.6$\%$ to 86.2$\%$. Furthermore, in zero-shot adaptation scenarios, our model demonstrates significant efficacy by achieving promising results in cases that were previously unrecognizable. Our project is available at \url{https://github.com/LanglandsLin/IGM}.
MacDiff: Unified Skeleton Modeling with Masked Conditional Diffusion
Sep 16, 2024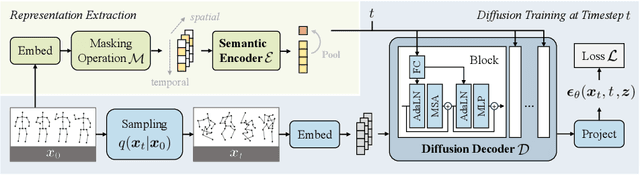
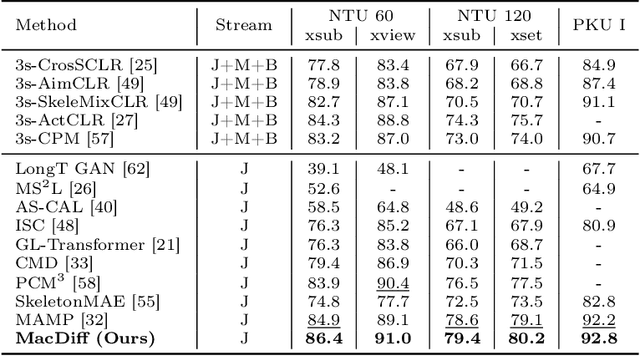
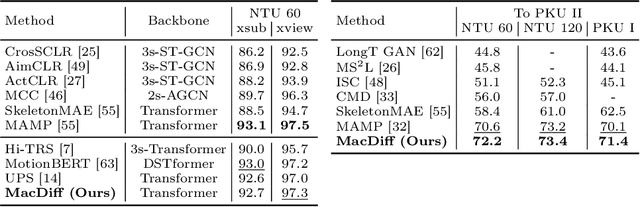
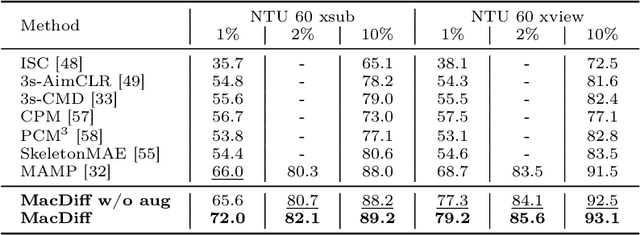
Self-supervised learning has proved effective for skeleton-based human action understanding. However, previous works either rely on contrastive learning that suffers false negative problems or are based on reconstruction that learns too much unessential low-level clues, leading to limited representations for downstream tasks. Recently, great advances have been made in generative learning, which is naturally a challenging yet meaningful pretext task to model the general underlying data distributions. However, the representation learning capacity of generative models is under-explored, especially for the skeletons with spacial sparsity and temporal redundancy. To this end, we propose Masked Conditional Diffusion (MacDiff) as a unified framework for human skeleton modeling. For the first time, we leverage diffusion models as effective skeleton representation learners. Specifically, we train a diffusion decoder conditioned on the representations extracted by a semantic encoder. Random masking is applied to encoder inputs to introduce a information bottleneck and remove redundancy of skeletons. Furthermore, we theoretically demonstrate that our generative objective involves the contrastive learning objective which aligns the masked and noisy views. Meanwhile, it also enforces the representation to complement for the noisy view, leading to better generalization performance. MacDiff achieves state-of-the-art performance on representation learning benchmarks while maintaining the competence for generative tasks. Moreover, we leverage the diffusion model for data augmentation, significantly enhancing the fine-tuning performance in scenarios with scarce labeled data. Our project is available at https://lehongwu.github.io/ECCV24MacDiff/.