 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Context Matters: Towards Provable Multi-Modality Guidance for Super-Resolution
May 11, 2026Super-resolution (SR) is a severely ill-posed problem with inherent ambiguity, as widely recognized in both empirical and theoretical studies. Although recent semantic-guided and multi-modal SR methods exploit large models or external priors to enhance semantic alignment, the fusion of heterogeneous modalities remains insufficiently understood in practice and theory. In this work, we provide the first theoretical modeling of multi-modal SR, revealing that prior methods are bottlenecked by sub-optimal modality utilization. Our analysis shows that the generalization risk bound can be improved by strengthening the alignment between modality weights and their effective contributions, while reducing representation complexity. This theoretical insight inspires us to propose the novel Multi-Modal Mixture-of-Experts Super-Resolution framework (M$^3$ESR) that employs generalization-oriented dynamic modality fusion for accurate risk control and modality contribution optimization. In detail, we propose a novel spatially dynamic modality weighting module and a temporally adaptive modality temperature scheduling mechanism, enabling flexible and adaptive spatial-temporal modality weighting for effective risk control. Extensive experiments demonstrate that our M$^3$ESR significantly boosts generalization and semantic consistency performances, which confirms our superiority.
S$^{5}$Mars: Self-Supervised and Semi-Supervised Learning for Mars Segmentation
Jul 04, 2022
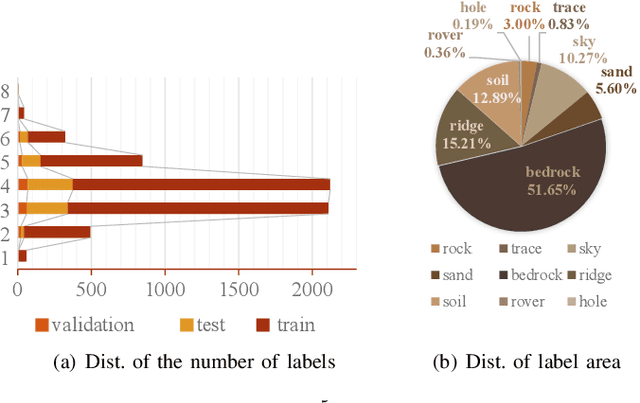
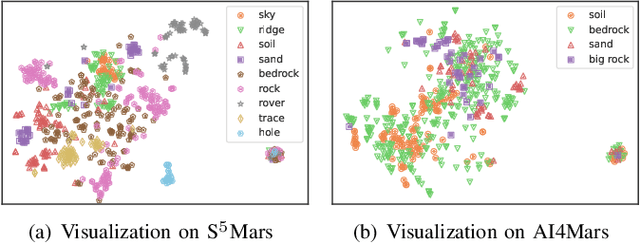
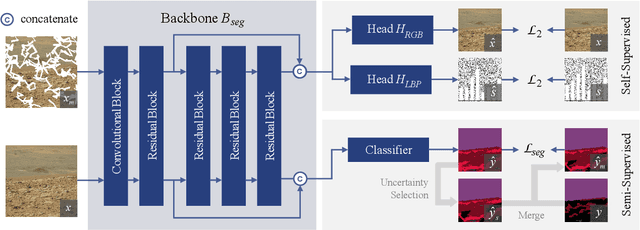
Deep learning has become a powerful tool for Mars exploration. Mars terrain segmentation is an important Martian vision task, which is the base of rover autonomous planning and safe driving. However, existing deep-learning-based terrain segmentation methods face two problems: one is the lack of sufficient detailed and high-confidence annotations, and the other is the over-reliance of models on annotated training data. In this paper, we address these two problems from the perspective of joint data and method design. We first present a new Mars terrain segmentation dataset which contains 6K high-resolution images and is sparsely annotated based on confidence, ensuring the high quality of labels. Then to learn from this sparse data, we propose a representation-learning-based framework for Mars terrain segmentation, including a self-supervised learning stage (for pre-training) and a semi-supervised learning stage (for fine-tuning). Specifically, for self-supervised learning, we design a multi-task mechanism based on the masked image modeling (MIM) concept to emphasize the texture information of images. For semi-supervised learning, since our dataset is sparsely annotated, we encourage the model to excavate the information of unlabeled area in each image by generating and utilizing pseudo-labels online. We name our dataset and method Self-Supervised and Semi-Supervised Segmentation for Mars (S$^{5}$Mars). Experimental results show that our method can outperform state-of-the-art approaches and improve terrain segmentation performance by a large margin.
Semi-Supervised Learning for Mars Imagery Classification and Segmentation
Jun 05, 2022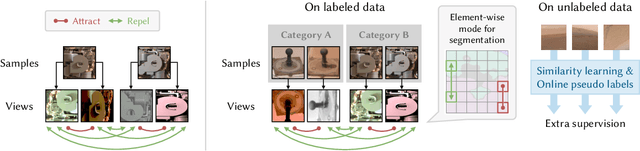
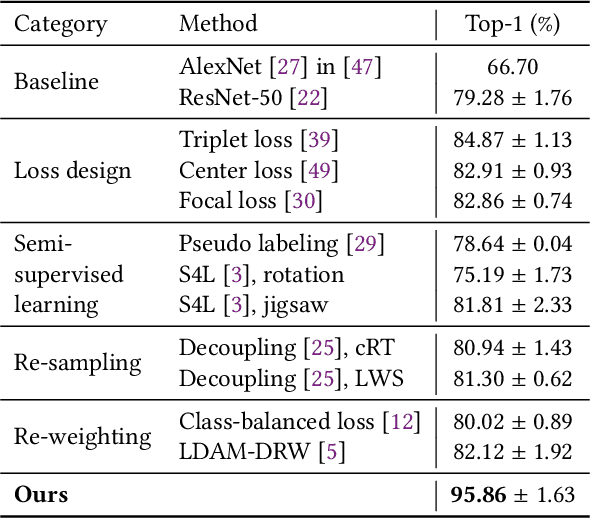
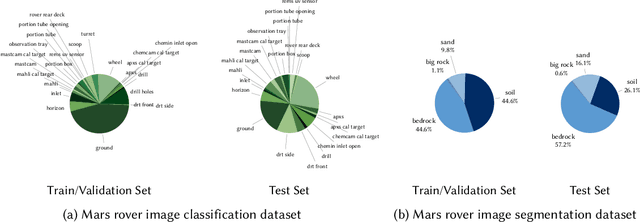
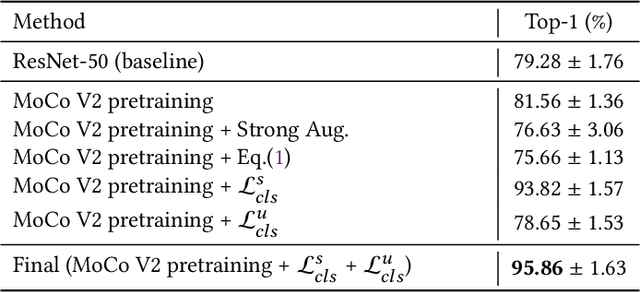
With the progress of Mars exploration, numerous Mars image data are collected and need to be analyzed. However, due to the imbalance and distortion of Martian data, the performance of existing computer vision models is unsatisfactory. In this paper, we introduce a semi-supervised framework for machine vision on Mars and try to resolve two specific tasks: classification and segmentation. Contrastive learning is a powerful representation learning technique. However, there is too much information overlap between Martian data samples, leading to a contradiction between contrastive learning and Martian data. Our key idea is to reconcile this contradiction with the help of annotations and further take advantage of unlabeled data to improve performance. For classification, we propose to ignore inner-class pairs on labeled data as well as neglect negative pairs on unlabeled data, forming supervised inter-class contrastive learning and unsupervised similarity learning. For segmentation, we extend supervised inter-class contrastive learning into an element-wise mode and use online pseudo labels for supervision on unlabeled areas. Experimental results show that our learning strategies can improve the classification and segmentation models by a large margin and outperform state-of-the-art approaches.
Conditional DETR for Fast Training Convergence
Aug 19, 2021



The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7x faster for the backbones R50 and R101 and 10x faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.
Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight
Jun 08, 2021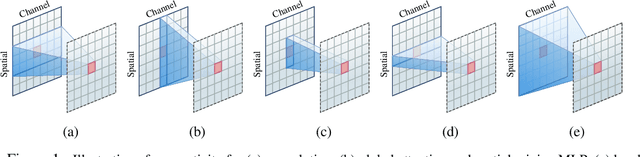

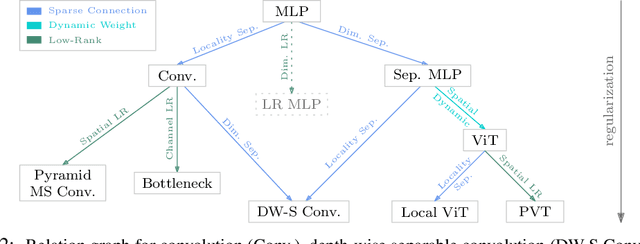
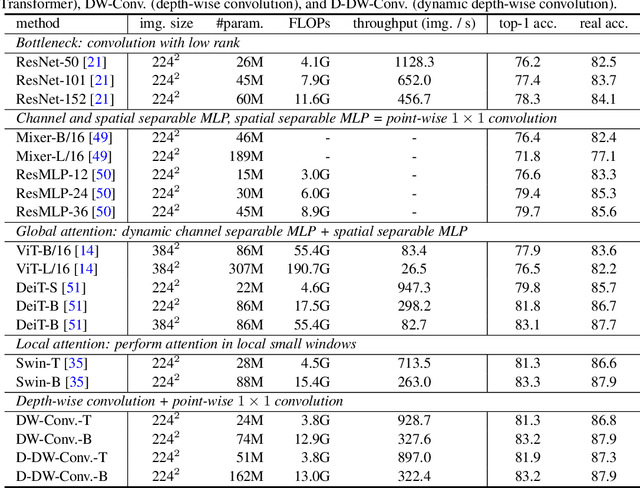
Vision Transformer (ViT) attains state-of-the-art performance in visual recognition, and the variant, Local Vision Transformer, makes further improvements. The major component in Local Vision Transformer, local attention, performs the attention separately over small local windows. We rephrase local attention as a channel-wise locally-connected layer and analyze it from two network regularization manners, sparse connectivity and weight sharing, as well as weight computation. Sparse connectivity: there is no connection across channels, and each position is connected to the positions within a small local window. Weight sharing: the connection weights for one position are shared across channels or within each group of channels. Dynamic weight: the connection weights are dynamically predicted according to each image instance. We point out that local attention resembles depth-wise convolution and its dynamic version in sparse connectivity. The main difference lies in weight sharing - depth-wise convolution shares connection weights (kernel weights) across spatial positions. We empirically observe that the models based on depth-wise convolution and the dynamic variant with lower computation complexity perform on-par with or sometimes slightly better than Swin Transformer, an instance of Local Vision Transformer, for ImageNet classification, COCO object detection and ADE semantic segmentation. These observations suggest that Local Vision Transformer takes advantage of two regularization forms and dynamic weight to increase the network capacity.