 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJanus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Jan 29, 2025In this work, we introduce Janus-Pro, an advanced version of the previous work Janus. Specifically, Janus-Pro incorporates (1) an optimized training strategy, (2) expanded training data, and (3) scaling to larger model size. With these improvements, Janus-Pro achieves significant advancements in both multimodal understanding and text-to-image instruction-following capabilities, while also enhancing the stability of text-to-image generation. We hope this work will inspire further exploration in the field. Code and models are publicly available.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024
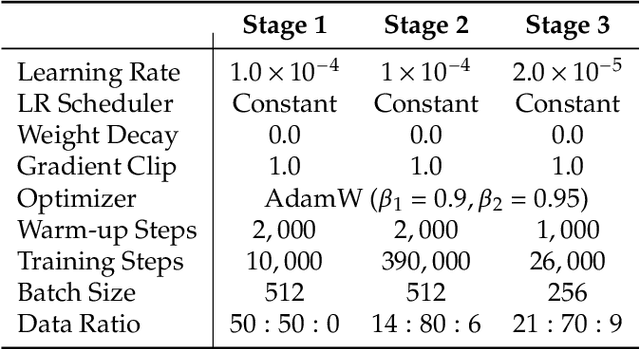

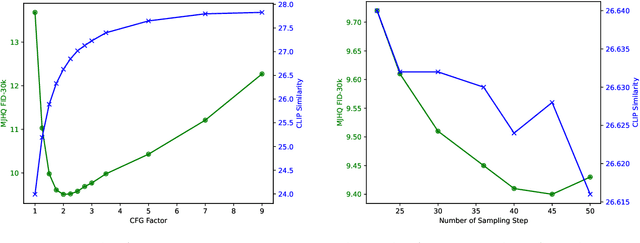
We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Oct 17, 2024



In this paper, we introduce Janus, an autoregressive framework that unifies multimodal understanding and generation. Prior research often relies on a single visual encoder for both tasks, such as Chameleon. However, due to the differing levels of information granularity required by multimodal understanding and generation, this approach can lead to suboptimal performance, particularly in multimodal understanding. To address this issue, we decouple visual encoding into separate pathways, while still leveraging a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder's roles in understanding and generation, but also enhances the framework's flexibility. For instance, both the multimodal understanding and generation components can independently select their most suitable encoding methods. Experiments show that Janus surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
The Devil is in the Neurons: Interpreting and Mitigating Social Biases in Pre-trained Language Models
Jun 14, 2024



Pre-trained Language models (PLMs) have been acknowledged to contain harmful information, such as social biases, which may cause negative social impacts or even bring catastrophic results in application. Previous works on this problem mainly focused on using black-box methods such as probing to detect and quantify social biases in PLMs by observing model outputs. As a result, previous debiasing methods mainly finetune or even pre-train language models on newly constructed anti-stereotypical datasets, which are high-cost. In this work, we try to unveil the mystery of social bias inside language models by introducing the concept of {\sc Social Bias Neurons}. Specifically, we propose {\sc Integrated Gap Gradients (IG$^2$)} to accurately pinpoint units (i.e., neurons) in a language model that can be attributed to undesirable behavior, such as social bias. By formalizing undesirable behavior as a distributional property of language, we employ sentiment-bearing prompts to elicit classes of sensitive words (demographics) correlated with such sentiments. Our IG$^2$ thus attributes the uneven distribution for different demographics to specific Social Bias Neurons, which track the trail of unwanted behavior inside PLM units to achieve interoperability. Moreover, derived from our interpretable technique, {\sc Bias Neuron Suppression (BNS)} is further proposed to mitigate social biases. By studying BERT, RoBERTa, and their attributable differences from debiased FairBERTa, IG$^2$ allows us to locate and suppress identified neurons, and further mitigate undesired behaviors. As measured by prior metrics from StereoSet, our model achieves a higher degree of fairness while maintaining language modeling ability with low cost.
Improving Long Text Understanding with Knowledge Distilled from Summarization Model
May 08, 2024Long text understanding is important yet challenging for natural language processing. A long article or document usually contains many redundant words that are not pertinent to its gist and sometimes can be regarded as noise. With recent advances of abstractive summarization, we propose our \emph{Gist Detector} to leverage the gist detection ability of a summarization model and integrate the extracted gist into downstream models to enhance their long text understanding ability. Specifically, Gist Detector first learns the gist detection knowledge distilled from a summarization model, and then produces gist-aware representations to augment downstream models. We evaluate our method on three different tasks: long document classification, distantly supervised open-domain question answering, and non-parallel text style transfer. The experimental results show that our method can significantly improve the performance of baseline models on all tasks.
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Feb 07, 20243D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training. In this paper, we introduce Large Multi-View Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images. Our key insights are two-fold: 1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused together for differentiable rendering. 2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
May 25, 2023



Large language models (LLMs) have notably accelerated progress towards artificial general intelligence (AGI), with their impressive zero-shot capacity for user-tailored tasks, endowing them with immense potential across a range of applications. However, in the field of computer vision, despite the availability of numerous powerful vision foundation models (VFMs), they are still restricted to tasks in a pre-defined form, struggling to match the open-ended task capabilities of LLMs. In this work, we present an LLM-based framework for vision-centric tasks, termed VisionLLM. This framework provides a unified perspective for vision and language tasks by treating images as a foreign language and aligning vision-centric tasks with language tasks that can be flexibly defined and managed using language instructions. An LLM-based decoder can then make appropriate predictions based on these instructions for open-ended tasks. Extensive experiments show that the proposed VisionLLM can achieve different levels of task customization through language instructions, from fine-grained object-level to coarse-grained task-level customization, all with good results. It's noteworthy that, with a generalist LLM-based framework, our model can achieve over 60\% mAP on COCO, on par with detection-specific models. We hope this model can set a new baseline for generalist vision and language models. The demo shall be released based on https://github.com/OpenGVLab/InternGPT. The code shall be released at https://github.com/OpenGVLab/VisionLLM.