 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion
Jul 17, 2024
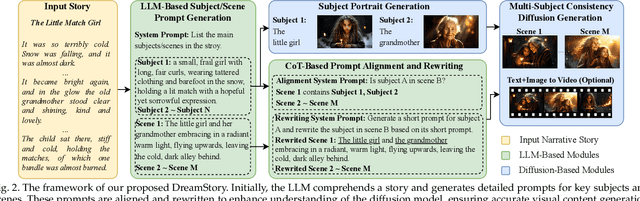
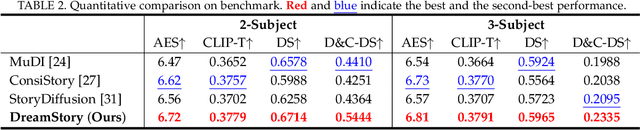
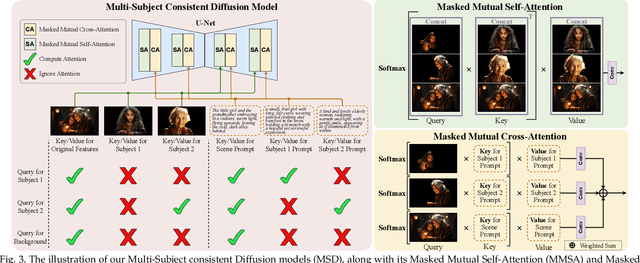
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose DreamStory, an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model. DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subject across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene's subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal anchors (guidance). Finally, the MSD uses these multimodal anchors to generate story scenes with consistent multi-subject. Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA and MMCA modules ensure appearance and semantic consistency with reference images and text, respectively. Both modules employ masking mechanisms to prevent subject blending. To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations. Please visit our project homepage at https://dream-xyz.github.io/dreamstory.
MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Jul 31, 2023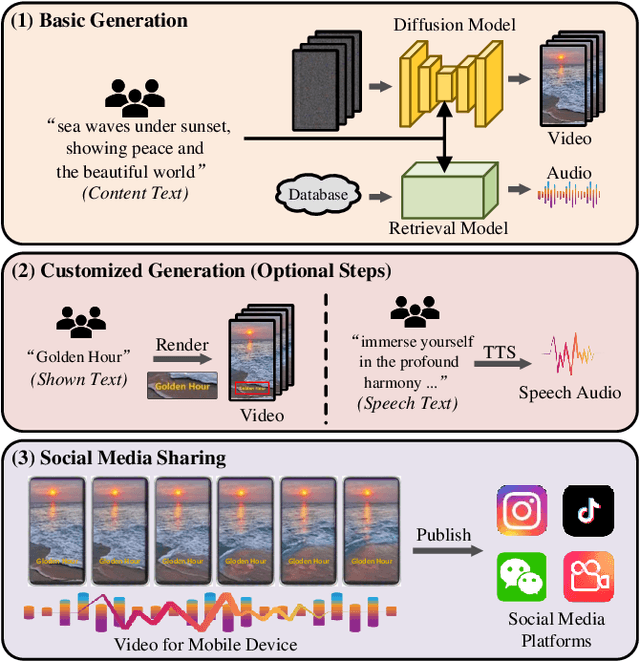

Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users' creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
Jun 12, 2023In this paper, we present MovieFactory, a powerful framework to generate cinematic-picture (3072$\times$1280), film-style (multi-scene), and multi-modality (sounding) movies on the demand of natural languages. As the first fully automated movie generation model to the best of our knowledge, our approach empowers users to create captivating movies with smooth transitions using simple text inputs, surpassing existing methods that produce soundless videos limited to a single scene of modest quality. To facilitate this distinctive functionality, we leverage ChatGPT to expand user-provided text into detailed sequential scripts for movie generation. Then we bring scripts to life visually and acoustically through vision generation and audio retrieval. To generate videos, we extend the capabilities of a pretrained text-to-image diffusion model through a two-stage process. Firstly, we employ spatial finetuning to bridge the gap between the pretrained image model and the new video dataset. Subsequently, we introduce temporal learning to capture object motion. In terms of audio, we leverage sophisticated retrieval models to select and align audio elements that correspond to the plot and visual content of the movie. Extensive experiments demonstrate that our MovieFactory produces movies with realistic visuals, diverse scenes, and seamlessly fitting audio, offering users a novel and immersive experience. Generated samples can be found in YouTube or Bilibili (1080P).
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation
May 18, 2023



We present VideoFactory, an innovative framework for generating high-quality open-domain videos. VideoFactory excels in producing high-definition (1376x768), widescreen (16:9) videos without watermarks, creating an engaging user experience. Generating videos guided by text instructions poses significant challenges, such as modeling the complex relationship between space and time, and the lack of large-scale text-video paired data. Previous approaches extend pretrained text-to-image generation models by adding temporal 1D convolution/attention modules for video generation. However, these approaches overlook the importance of jointly modeling space and time, inevitably leading to temporal distortions and misalignment between texts and videos. In this paper, we propose a novel approach that strengthens the interaction between spatial and temporal perceptions. In particular, we utilize a swapped cross-attention mechanism in 3D windows that alternates the "query" role between spatial and temporal blocks, enabling mutual reinforcement for each other. To fully unlock model capabilities for high-quality video generation, we curate a large-scale video dataset called HD-VG-130M. This dataset comprises 130 million text-video pairs from the open-domain, ensuring high-definition, widescreen and watermark-free characters. Objective metrics and user studies demonstrate the superiority of our approach in terms of per-frame quality, temporal correlation, and text-video alignment, with clear margins.
Learning Data-Driven Vector-Quantized Degradation Model for Animation Video Super-Resolution
Mar 17, 2023

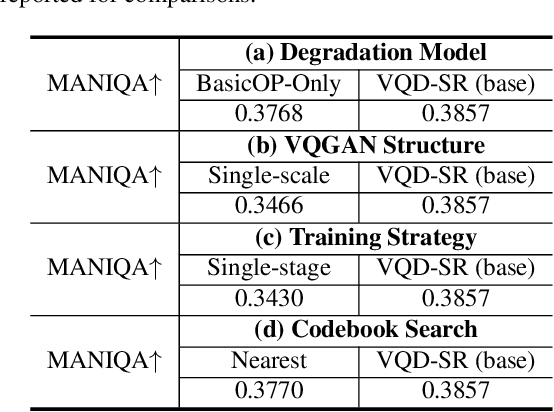
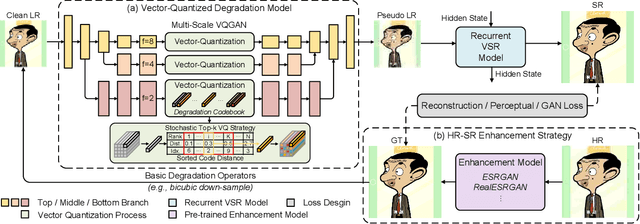
Existing real-world video super-resolution (VSR) methods focus on designing a general degradation pipeline for open-domain videos while ignoring data intrinsic characteristics which strongly limit their performance when applying to some specific domains (e.g. animation videos). In this paper, we thoroughly explore the characteristics of animation videos and leverage the rich priors in real-world animation data for a more practical animation VSR model. In particular, we propose a multi-scale Vector-Quantized Degradation model for animation video Super-Resolution (VQD-SR) to decompose the local details from global structures and transfer the degradation priors in real-world animation videos to a learned vector-quantized codebook for degradation modeling. A rich-content Real Animation Low-quality (RAL) video dataset is collected for extracting the priors. We further propose a data enhancement strategy for high-resolution (HR) training videos based on our observation that existing HR videos are mostly collected from the Web which contains conspicuous compression artifacts. The proposed strategy is valid to lift the upper bound of animation VSR performance, regardless of the specific VSR model. Experimental results demonstrate the superiority of the proposed VQD-SR over state-of-the-art methods, through extensive quantitative and qualitative evaluations of the latest animation video super-resolution benchmark.