 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion
Paper and Code

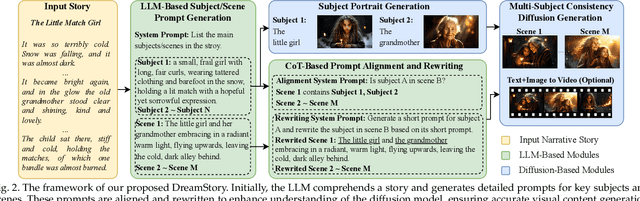
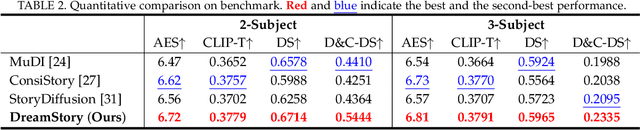
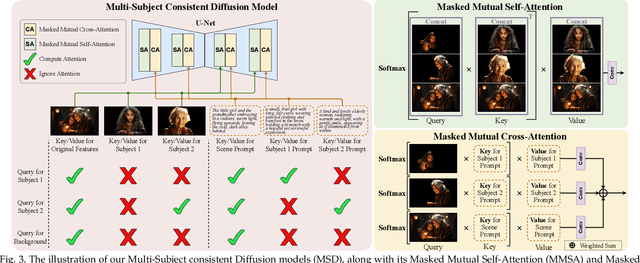
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose DreamStory, an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model. DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subject across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene's subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal anchors (guidance). Finally, the MSD uses these multimodal anchors to generate story scenes with consistent multi-subject. Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA and MMCA modules ensure appearance and semantic consistency with reference images and text, respectively. Both modules employ masking mechanisms to prevent subject blending. To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations. Please visit our project homepage at https://dream-xyz.github.io/dreamstory.