 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Trajectory Rewards: Step-level Credit Assignment for Agentic Search via Graph Modeling
May 28, 2026In Agentic Search, trajectory-level outcome rewards fail to quantify the behavioral contributions of individual steps, while existing step-level reward methods typically rely on costly tree sampling. We view world knowledge as a latent world graph and each IS task as search within a latent task graph, where effective steps should make graph progress toward the answer node. Based on this prior, we propose Graph-Distance Contribution Reward (GDCR), a step-level process reward that scores newly-retrieved and newly-cited entities by their distance to the answer node in a training-time Entity-Relation (ER) graph. We further propose Step Advantage Policy Optimization (SAPO), which converts GDCR into step-level advantages and combines them with trajectory-level outcome advantages. Experiments on four challenging benchmarks validate the effectiveness of our method.
Fake-in-Facext: Towards Fine-Grained Explainable DeepFake Analysis
Oct 23, 2025The advancement of Multimodal Large Language Models (MLLMs) has bridged the gap between vision and language tasks, enabling the implementation of Explainable DeepFake Analysis (XDFA). However, current methods suffer from a lack of fine-grained awareness: the description of artifacts in data annotation is unreliable and coarse-grained, and the models fail to support the output of connections between textual forgery explanations and the visual evidence of artifacts, as well as the input of queries for arbitrary facial regions. As a result, their responses are not sufficiently grounded in Face Visual Context (Facext). To address this limitation, we propose the Fake-in-Facext (FiFa) framework, with contributions focusing on data annotation and model construction. We first define a Facial Image Concept Tree (FICT) to divide facial images into fine-grained regional concepts, thereby obtaining a more reliable data annotation pipeline, FiFa-Annotator, for forgery explanation. Based on this dedicated data annotation, we introduce a novel Artifact-Grounding Explanation (AGE) task, which generates textual forgery explanations interleaved with segmentation masks of manipulated artifacts. We propose a unified multi-task learning architecture, FiFa-MLLM, to simultaneously support abundant multimodal inputs and outputs for fine-grained Explainable DeepFake Analysis. With multiple auxiliary supervision tasks, FiFa-MLLM can outperform strong baselines on the AGE task and achieve SOTA performance on existing XDFA datasets. The code and data will be made open-source at https://github.com/lxq1000/Fake-in-Facext.
VA-AR: Learning Velocity-Aware Action Representations with Mixture of Window Attention
Mar 14, 2025Action recognition is a crucial task in artificial intelligence, with significant implications across various domains. We initially perform a comprehensive analysis of seven prominent action recognition methods across five widely-used datasets. This analysis reveals a critical, yet previously overlooked, observation: as the velocity of actions increases, the performance of these methods variably declines, undermining their robustness. This decline in performance poses significant challenges for their application in real-world scenarios. Building on these findings, we introduce the Velocity-Aware Action Recognition (VA-AR) framework to obtain robust action representations across different velocities. Our principal insight is that rapid actions (e.g., the giant circle backward in uneven bars or a smash in badminton) occur within short time intervals, necessitating smaller temporal attention windows to accurately capture intricate changes. Conversely, slower actions (e.g., drinking water or wiping face) require larger windows to effectively encompass the broader context. VA-AR employs a Mixture of Window Attention (MoWA) strategy, dynamically adjusting its attention window size based on the action's velocity. This adjustment enables VA-AR to obtain a velocity-aware representation, thereby enhancing the accuracy of action recognition. Extensive experiments confirm that VA-AR achieves state-of-the-art performance on the same five datasets, demonstrating VA-AR's effectiveness across a broad spectrum of action recognition scenarios.
Face-Human-Bench: A Comprehensive Benchmark of Face and Human Understanding for Multi-modal Assistants
Jan 05, 2025



Faces and humans are crucial elements in social interaction and are widely included in everyday photos and videos. Therefore, a deep understanding of faces and humans will enable multi-modal assistants to achieve improved response quality and broadened application scope. Currently, the multi-modal assistant community lacks a comprehensive and scientific evaluation of face and human understanding abilities. In this paper, we first propose a hierarchical ability taxonomy that includes three levels of abilities. Then, based on this taxonomy, we collect images and annotations from publicly available datasets in the face and human community and build a semi-automatic data pipeline to produce problems for the new benchmark. Finally, the obtained Face-Human-Bench comprises a development set with 900 problems and a test set with 1800 problems, supporting both English and Chinese. We conduct evaluations over 25 mainstream multi-modal large language models (MLLMs) with our Face-Human-Bench, focusing on the correlation between abilities, the impact of the relative position of targets on performance, and the impact of Chain of Thought (CoT) prompting on performance. Moreover, inspired by multi-modal agents, we also explore which abilities of MLLMs need to be supplemented by specialist models.
Towards Interactive Deepfake Analysis
Jan 02, 2025



Existing deepfake analysis methods are primarily based on discriminative models, which significantly limit their application scenarios. This paper aims to explore interactive deepfake analysis by performing instruction tuning on multi-modal large language models (MLLMs). This will face challenges such as the lack of datasets and benchmarks, and low training efficiency. To address these issues, we introduce (1) a GPT-assisted data construction process resulting in an instruction-following dataset called DFA-Instruct, (2) a benchmark named DFA-Bench, designed to comprehensively evaluate the capabilities of MLLMs in deepfake detection, deepfake classification, and artifact description, and (3) construct an interactive deepfake analysis system called DFA-GPT, as a strong baseline for the community, with the Low-Rank Adaptation (LoRA) module. The dataset and code will be made available at https://github.com/lxq1000/DFA-Instruct to facilitate further research.
Faceptor: A Generalist Model for Face Perception
Mar 14, 2024



With the comprehensive research conducted on various face analysis tasks, there is a growing interest among researchers to develop a unified approach to face perception. Existing methods mainly discuss unified representation and training, which lack task extensibility and application efficiency. To tackle this issue, we focus on the unified model structure, exploring a face generalist model. As an intuitive design, Naive Faceptor enables tasks with the same output shape and granularity to share the structural design of the standardized output head, achieving improved task extensibility. Furthermore, Faceptor is proposed to adopt a well-designed single-encoder dual-decoder architecture, allowing task-specific queries to represent new-coming semantics. This design enhances the unification of model structure while improving application efficiency in terms of storage overhead. Additionally, we introduce Layer-Attention into Faceptor, enabling the model to adaptively select features from optimal layers to perform the desired tasks. Through joint training on 13 face perception datasets, Faceptor achieves exceptional performance in facial landmark localization, face parsing, age estimation, expression recognition, binary attribute classification, and face recognition, achieving or surpassing specialized methods in most tasks. Our training framework can also be applied to auxiliary supervised learning, significantly improving performance in data-sparse tasks such as age estimation and expression recognition. The code and models will be made publicly available at https://github.com/lxq1000/Faceptor.
FakeNewsGPT4: Advancing Multimodal Fake News Detection through Knowledge-Augmented LVLMs
Mar 04, 2024



The massive generation of multimodal fake news exhibits substantial distribution discrepancies, prompting the need for generalized detectors. However, the insulated nature of training within specific domains restricts the capability of classical detectors to obtain open-world facts. In this paper, we propose FakeNewsGPT4, a novel framework that augments Large Vision-Language Models (LVLMs) with forgery-specific knowledge for manipulation reasoning while inheriting extensive world knowledge as complementary. Knowledge augmentation in FakeNewsGPT4 involves acquiring two types of forgery-specific knowledge, i.e., semantic correlation and artifact trace, and merging them into LVLMs. Specifically, we design a multi-level cross-modal reasoning module that establishes interactions across modalities for extracting semantic correlations. Concurrently, a dual-branch fine-grained verification module is presented to comprehend localized details to encode artifact traces. The generated knowledge is translated into refined embeddings compatible with LVLMs. We also incorporate candidate answer heuristics and soft prompts to enhance input informativeness. Extensive experiments on the public benchmark demonstrate that FakeNewsGPT4 achieves superior cross-domain performance compared to previous methods. Code will be available.
Open-Set Facial Expression Recognition
Jan 23, 2024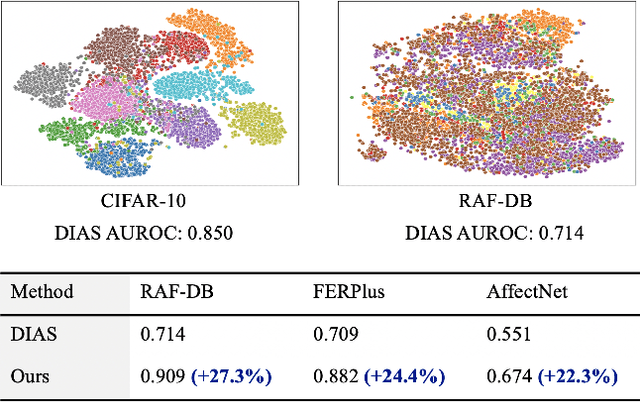
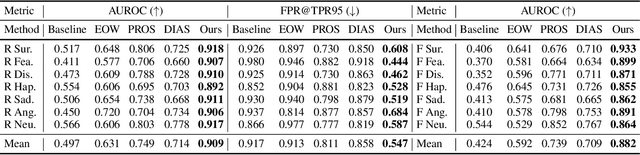
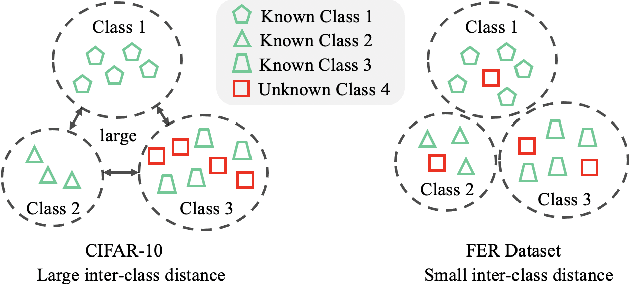
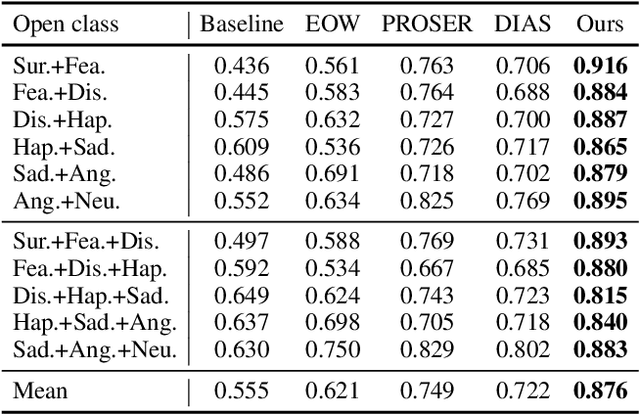
Facial expression recognition (FER) models are typically trained on datasets with a fixed number of seven basic classes. However, recent research works point out that there are far more expressions than the basic ones. Thus, when these models are deployed in the real world, they may encounter unknown classes, such as compound expressions that cannot be classified into existing basic classes. To address this issue, we propose the open-set FER task for the first time. Though there are many existing open-set recognition methods, we argue that they do not work well for open-set FER because FER data are all human faces with very small inter-class distances, which makes the open-set samples very similar to close-set samples. In this paper, we are the first to transform the disadvantage of small inter-class distance into an advantage by proposing a new way for open-set FER. Specifically, we find that small inter-class distance allows for sparsely distributed pseudo labels of open-set samples, which can be viewed as symmetric noisy labels. Based on this novel observation, we convert the open-set FER to a noisy label detection problem. We further propose a novel method that incorporates attention map consistency and cycle training to detect the open-set samples. Extensive experiments on various FER datasets demonstrate that our method clearly outperforms state-of-the-art open-set recognition methods by large margins. Code is available at https://github.com/zyh-uaiaaaa.
Leave No Stone Unturned: Mine Extra Knowledge for Imbalanced Facial Expression Recognition
Oct 30, 2023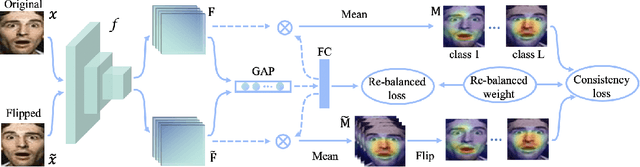



Facial expression data is characterized by a significant imbalance, with most collected data showing happy or neutral expressions and fewer instances of fear or disgust. This imbalance poses challenges to facial expression recognition (FER) models, hindering their ability to fully understand various human emotional states. Existing FER methods typically report overall accuracy on highly imbalanced test sets but exhibit low performance in terms of the mean accuracy across all expression classes. In this paper, our aim is to address the imbalanced FER problem. Existing methods primarily focus on learning knowledge of minor classes solely from minor-class samples. However, we propose a novel approach to extract extra knowledge related to the minor classes from both major and minor class samples. Our motivation stems from the belief that FER resembles a distribution learning task, wherein a sample may contain information about multiple classes. For instance, a sample from the major class surprise might also contain useful features of the minor class fear. Inspired by that, we propose a novel method that leverages re-balanced attention maps to regularize the model, enabling it to extract transformation invariant information about the minor classes from all training samples. Additionally, we introduce re-balanced smooth labels to regulate the cross-entropy loss, guiding the model to pay more attention to the minor classes by utilizing the extra information regarding the label distribution of the imbalanced training data. Extensive experiments on different datasets and backbones show that the two proposed modules work together to regularize the model and achieve state-of-the-art performance under the imbalanced FER task. Code is available at https://github.com/zyh-uaiaaaa.
SwinFace: A Multi-task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation
Aug 22, 2023



In recent years, vision transformers have been introduced into face recognition and analysis and have achieved performance breakthroughs. However, most previous methods generally train a single model or an ensemble of models to perform the desired task, which ignores the synergy among different tasks and fails to achieve improved prediction accuracy, increased data efficiency, and reduced training time. This paper presents a multi-purpose algorithm for simultaneous face recognition, facial expression recognition, age estimation, and face attribute estimation (40 attributes including gender) based on a single Swin Transformer. Our design, the SwinFace, consists of a single shared backbone together with a subnet for each set of related tasks. To address the conflicts among multiple tasks and meet the different demands of tasks, a Multi-Level Channel Attention (MLCA) module is integrated into each task-specific analysis subnet, which can adaptively select the features from optimal levels and channels to perform the desired tasks. Extensive experiments show that the proposed model has a better understanding of the face and achieves excellent performance for all tasks. Especially, it achieves 90.97% accuracy on RAF-DB and 0.22 $\epsilon$-error on CLAP2015, which are state-of-the-art results on facial expression recognition and age estimation respectively. The code and models will be made publicly available at https://github.com/lxq1000/SwinFace.