 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchJudge: A Diagnostic Benchmark for Grading Hand-drawn Diagrams with Multimodal Large Language Models
Jan 11, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual understanding, they often struggle when faced with the unstructured and ambiguous nature of human-generated sketches. This limitation is particularly pronounced in the underexplored task of visual grading, where models should not only solve a problem but also diagnose errors in hand-drawn diagrams. Such diagnostic capabilities depend on complex structural, semantic, and metacognitive reasoning. To bridge this gap, we introduce SketchJudge, a novel benchmark tailored for evaluating MLLMs as graders of hand-drawn STEM diagrams. SketchJudge encompasses 1,015 hand-drawn student responses across four domains: geometry, physics, charts, and flowcharts, featuring diverse stylistic variations and distinct error types. Evaluations on SketchJudge demonstrate that even advanced MLLMs lag significantly behind humans, validating the benchmark's effectiveness in exposing the fragility of current vision-language alignment in symbolic and noisy contexts. All data, code, and evaluation scripts are publicly available at https://github.com/yuhangsu82/SketchJudge.
Enhancing Generalization of Invisible Facial Privacy Cloak via Gradient Accumulation
Jan 03, 2024The blooming of social media and face recognition (FR) systems has increased people's concern about privacy and security. A new type of adversarial privacy cloak (class-universal) can be applied to all the images of regular users, to prevent malicious FR systems from acquiring their identity information. In this work, we discover the optimization dilemma in the existing methods -- the local optima problem in large-batch optimization and the gradient information elimination problem in small-batch optimization. To solve these problems, we propose Gradient Accumulation (GA) to aggregate multiple small-batch gradients into a one-step iterative gradient to enhance the gradient stability and reduce the usage of quantization operations. Experiments show that our proposed method achieves high performance on the Privacy-Commons dataset against black-box face recognition models.
AdvCloak: Customized Adversarial Cloak for Privacy Protection
Dec 22, 2023



With extensive face images being shared on social media, there has been a notable escalation in privacy concerns. In this paper, we propose AdvCloak, an innovative framework for privacy protection using generative models. AdvCloak is designed to automatically customize class-wise adversarial masks that can maintain superior image-level naturalness while providing enhanced feature-level generalization ability. Specifically, AdvCloak sequentially optimizes the generative adversarial networks by employing a two-stage training strategy. This strategy initially focuses on adapting the masks to the unique individual faces via image-specific training and then enhances their feature-level generalization ability to diverse facial variations of individuals via person-specific training. To fully utilize the limited training data, we combine AdvCloak with several general geometric modeling methods, to better describe the feature subspace of source identities. Extensive quantitative and qualitative evaluations on both common and celebrity datasets demonstrate that AdvCloak outperforms existing state-of-the-art methods in terms of efficiency and effectiveness.
VIoTGPT: Learning to Schedule Vision Tools towards Intelligent Video Internet of Things
Dec 01, 2023



Video Internet of Things (VIoT) has shown full potential in collecting an unprecedented volume of video data. Learning to schedule perceiving models and analyzing the collected videos intelligently will be potential sparks for VIoT. In this paper, to address the challenges posed by the fine-grained and interrelated vision tool usage of VIoT, we build VIoTGPT, the framework based on LLMs to correctly interact with humans, query knowledge videos, and invoke vision models to accomplish complicated tasks. To support VIoTGPT and related future works, we meticulously crafted the training dataset and established benchmarks involving 11 representative vision models across three categories based on semi-automatic annotations. To guide LLM to act as the intelligent agent towards intelligent VIoT, we resort to ReAct instruction tuning based on the collected VIoT dataset to learn the tool capability. Quantitative and qualitative experimental results and analyses demonstrate the effectiveness of VIoTGPT.
Enhancing Generalization of Universal Adversarial Perturbation through Gradient Aggregation
Aug 11, 2023
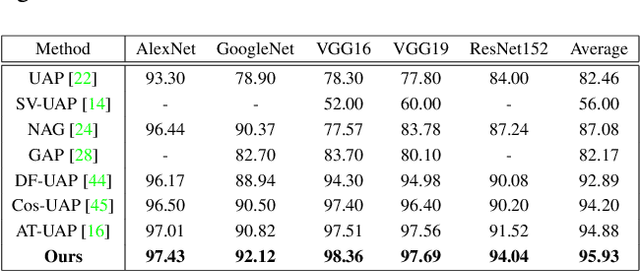


Deep neural networks are vulnerable to universal adversarial perturbation (UAP), an instance-agnostic perturbation capable of fooling the target model for most samples. Compared to instance-specific adversarial examples, UAP is more challenging as it needs to generalize across various samples and models. In this paper, we examine the serious dilemma of UAP generation methods from a generalization perspective -- the gradient vanishing problem using small-batch stochastic gradient optimization and the local optima problem using large-batch optimization. To address these problems, we propose a simple and effective method called Stochastic Gradient Aggregation (SGA), which alleviates the gradient vanishing and escapes from poor local optima at the same time. Specifically, SGA employs the small-batch training to perform multiple iterations of inner pre-search. Then, all the inner gradients are aggregated as a one-step gradient estimation to enhance the gradient stability and reduce quantization errors. Extensive experiments on the standard ImageNet dataset demonstrate that our method significantly enhances the generalization ability of UAP and outperforms other state-of-the-art methods. The code is available at https://github.com/liuxuannan/Stochastic-Gradient-Aggregation.
SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition
May 24, 2022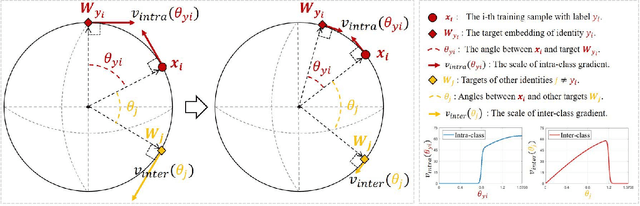
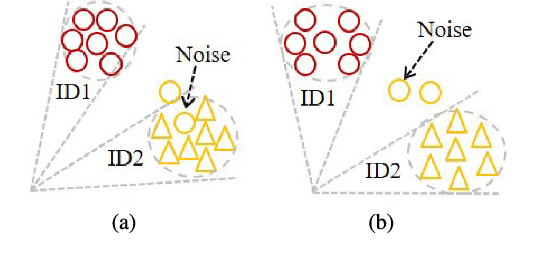
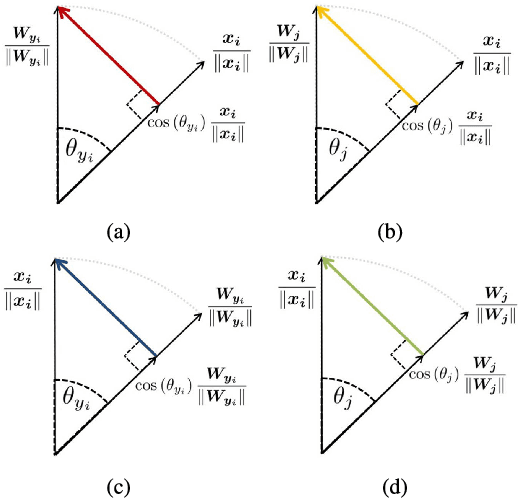
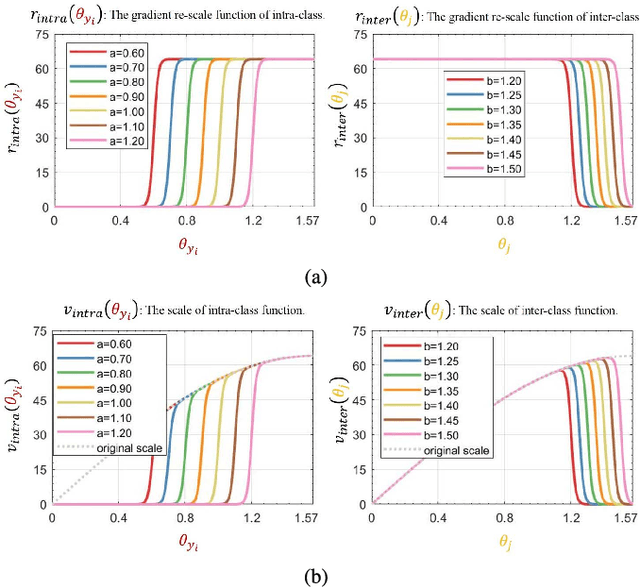
Deep face recognition has achieved great success due to large-scale training databases and rapidly developing loss functions. The existing algorithms devote to realizing an ideal idea: minimizing the intra-class distance and maximizing the inter-class distance. However, they may neglect that there are also low quality training images which should not be optimized in this strict way. Considering the imperfection of training databases, we propose that intra-class and inter-class objectives can be optimized in a moderate way to mitigate overfitting problem, and further propose a novel loss function, named sigmoid-constrained hypersphere loss (SFace). Specifically, SFace imposes intra-class and inter-class constraints on a hypersphere manifold, which are controlled by two sigmoid gradient re-scale functions respectively. The sigmoid curves precisely re-scale the intra-class and inter-class gradients so that training samples can be optimized to some degree. Therefore, SFace can make a better balance between decreasing the intra-class distances for clean examples and preventing overfitting to the label noise, and contributes more robust deep face recognition models. Extensive experiments of models trained on CASIA-WebFace, VGGFace2, and MS-Celeb-1M databases, and evaluated on several face recognition benchmarks, such as LFW, MegaFace and IJB-C databases, have demonstrated the superiority of SFace.
* 12 pages, 9 figures
OPOM: Customized Invisible Cloak towards Face Privacy Protection
May 24, 2022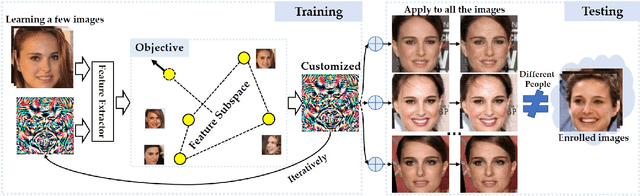
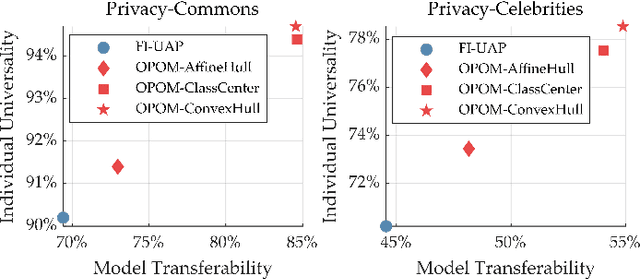
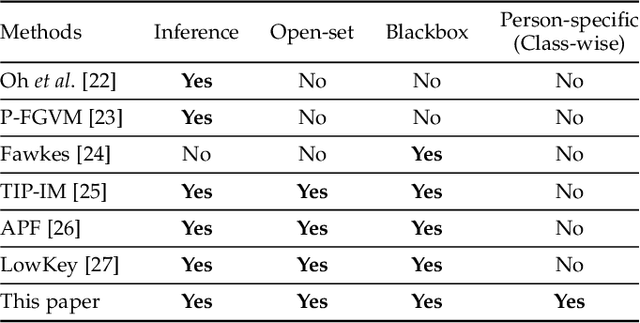
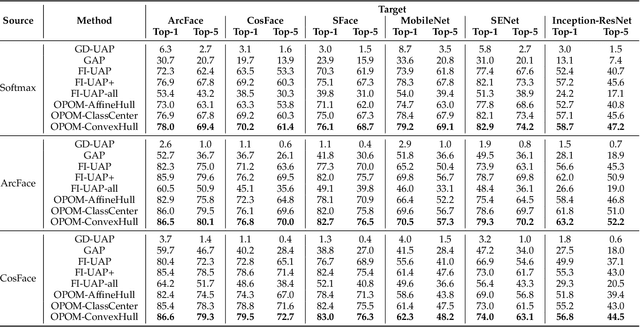
While convenient in daily life, face recognition technologies also raise privacy concerns for regular users on the social media since they could be used to analyze face images and videos, efficiently and surreptitiously without any security restrictions. In this paper, we investigate the face privacy protection from a technology standpoint based on a new type of customized cloak, which can be applied to all the images of a regular user, to prevent malicious face recognition systems from uncovering their identity. Specifically, we propose a new method, named one person one mask (OPOM), to generate person-specific (class-wise) universal masks by optimizing each training sample in the direction away from the feature subspace of the source identity. To make full use of the limited training images, we investigate several modeling methods, including affine hulls, class centers, and convex hulls, to obtain a better description of the feature subspace of source identities. The effectiveness of the proposed method is evaluated on both common and celebrity datasets against black-box face recognition models with different loss functions and network architectures. In addition, we discuss the advantages and potential problems of the proposed method. In particular, we conduct an application study on the privacy protection of a video dataset, Sherlock, to demonstrate the potential practical usage of the proposed method. Datasets and code are available at https://github.com/zhongyy/OPOM.
Video Question Answering: Datasets, Algorithms and Challenges
Mar 02, 2022

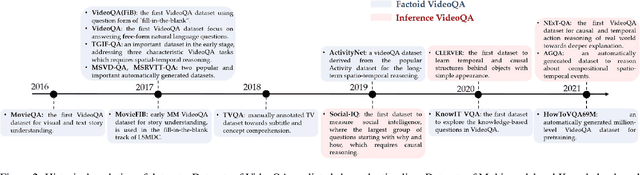
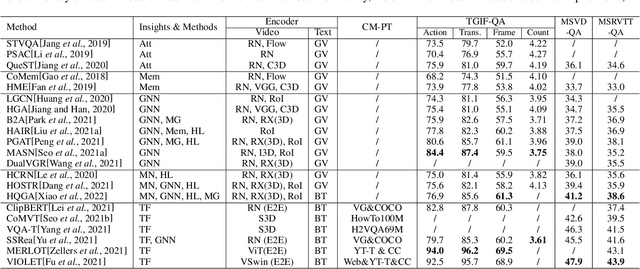
Video Question Answering (VideoQA) aims to answer natural language questions according to the given videos. It has earned increasing attention with recent research trends in joint vision and language understanding. Yet, compared with ImageQA, VideoQA is largely underexplored and progresses slowly. Although different algorithms have continually been proposed and shown success on different VideoQA datasets, we find that there lacks a meaningful survey to categorize them, which seriously impedes its advancements. This paper thus provides a clear taxonomy and comprehensive analyses to VideoQA, focusing on the datasets, algorithms, and unique challenges. We then point out the research trend of studying beyond factoid QA to inference QA towards the cognition of video contents, Finally, we conclude some promising directions for future exploration.
MLFW: A Database for Face Recognition on Masked Faces
Sep 15, 2021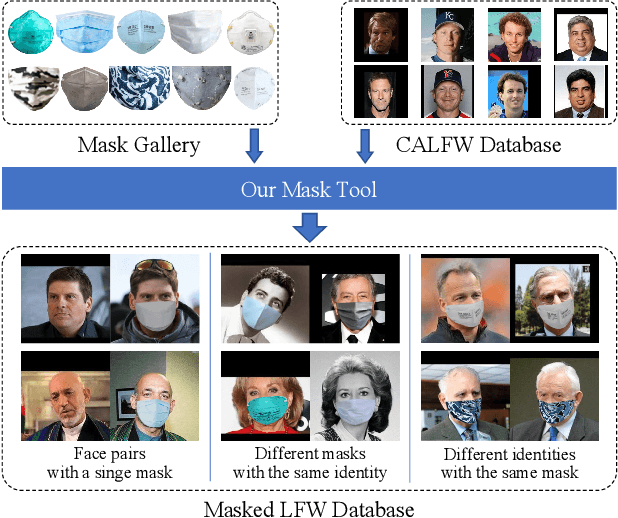


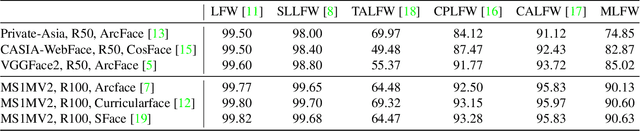
As more and more people begin to wear masks due to current COVID-19 pandemic, existing face recognition systems may encounter severe performance degradation when recognizing masked faces. To figure out the impact of masks on face recognition model, we build a simple but effective tool to generate masked faces from unmasked faces automatically, and construct a new database called Masked LFW (MLFW) based on Cross-Age LFW (CALFW) database. The mask on the masked face generated by our method has good visual consistency with the original face. Moreover, we collect various mask templates, covering most of the common styles appeared in the daily life, to achieve diverse generation effects. Considering realistic scenarios, we design three kinds of combinations of face pairs. The recognition accuracy of SOTA models declines 5%-16% on MLFW database compared with the accuracy on the original images. MLFW database can be viewed and downloaded at \url{http://whdeng.cn/mlfw}.
Face Transformer for Recognition
Apr 13, 2021



Recently there has been a growing interest in Transformer not only in NLP but also in computer vision. We wonder if transformer can be used in face recognition and whether it is better than CNNs. Therefore, we investigate the performance of Transformer models in face recognition. Considering the original Transformer may neglect the inter-patch information, we modify the patch generation process and make the tokens with sliding patches which overlaps with each others. The models are trained on CASIA-WebFace and MS-Celeb-1M databases, and evaluated on several mainstream benchmarks, including LFW, SLLFW, CALFW, CPLFW, TALFW, CFP-FP, AGEDB and IJB-C databases. We demonstrate that Face Transformer models trained on a large-scale database, MS-Celeb-1M, achieve comparable performance as CNN with similar number of parameters and MACs. To facilitate further researches, Face Transformer models and codes are available at https://github.com/zhongyy/Face-Transformer.