 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Question Answering: Datasets, Algorithms and Challenges
Paper and Code


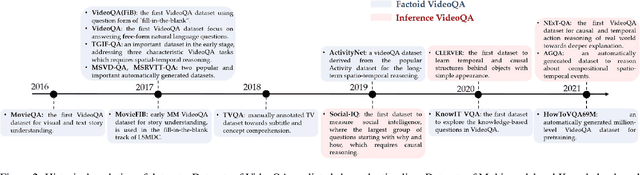
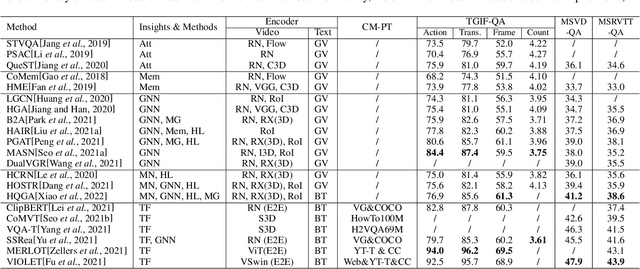
Video Question Answering (VideoQA) aims to answer natural language questions according to the given videos. It has earned increasing attention with recent research trends in joint vision and language understanding. Yet, compared with ImageQA, VideoQA is largely underexplored and progresses slowly. Although different algorithms have continually been proposed and shown success on different VideoQA datasets, we find that there lacks a meaningful survey to categorize them, which seriously impedes its advancements. This paper thus provides a clear taxonomy and comprehensive analyses to VideoQA, focusing on the datasets, algorithms, and unique challenges. We then point out the research trend of studying beyond factoid QA to inference QA towards the cognition of video contents, Finally, we conclude some promising directions for future exploration.