 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake-in-Facext: Towards Fine-Grained Explainable DeepFake Analysis
Oct 23, 2025The advancement of Multimodal Large Language Models (MLLMs) has bridged the gap between vision and language tasks, enabling the implementation of Explainable DeepFake Analysis (XDFA). However, current methods suffer from a lack of fine-grained awareness: the description of artifacts in data annotation is unreliable and coarse-grained, and the models fail to support the output of connections between textual forgery explanations and the visual evidence of artifacts, as well as the input of queries for arbitrary facial regions. As a result, their responses are not sufficiently grounded in Face Visual Context (Facext). To address this limitation, we propose the Fake-in-Facext (FiFa) framework, with contributions focusing on data annotation and model construction. We first define a Facial Image Concept Tree (FICT) to divide facial images into fine-grained regional concepts, thereby obtaining a more reliable data annotation pipeline, FiFa-Annotator, for forgery explanation. Based on this dedicated data annotation, we introduce a novel Artifact-Grounding Explanation (AGE) task, which generates textual forgery explanations interleaved with segmentation masks of manipulated artifacts. We propose a unified multi-task learning architecture, FiFa-MLLM, to simultaneously support abundant multimodal inputs and outputs for fine-grained Explainable DeepFake Analysis. With multiple auxiliary supervision tasks, FiFa-MLLM can outperform strong baselines on the AGE task and achieve SOTA performance on existing XDFA datasets. The code and data will be made open-source at https://github.com/lxq1000/Fake-in-Facext.
Towards Interactive Deepfake Analysis
Jan 02, 2025



Existing deepfake analysis methods are primarily based on discriminative models, which significantly limit their application scenarios. This paper aims to explore interactive deepfake analysis by performing instruction tuning on multi-modal large language models (MLLMs). This will face challenges such as the lack of datasets and benchmarks, and low training efficiency. To address these issues, we introduce (1) a GPT-assisted data construction process resulting in an instruction-following dataset called DFA-Instruct, (2) a benchmark named DFA-Bench, designed to comprehensively evaluate the capabilities of MLLMs in deepfake detection, deepfake classification, and artifact description, and (3) construct an interactive deepfake analysis system called DFA-GPT, as a strong baseline for the community, with the Low-Rank Adaptation (LoRA) module. The dataset and code will be made available at https://github.com/lxq1000/DFA-Instruct to facilitate further research.
Unsupervised Attention Regularization Based Domain Adaptation for Oracle Character Recognition
Sep 24, 2024The study of oracle characters plays an important role in Chinese archaeology and philology. However, the difficulty of collecting and annotating real-world scanned oracle characters hinders the development of oracle character recognition. In this paper, we develop a novel unsupervised domain adaptation (UDA) method, i.e., unsupervised attention regularization net?work (UARN), to transfer recognition knowledge from labeled handprinted oracle characters to unlabeled scanned data. First, we experimentally prove that existing UDA methods are not always consistent with human priors and cannot achieve optimal performance on the target domain. For these oracle characters with flip-insensitivity and high inter-class similarity, model interpretations are not flip-consistent and class-separable. To tackle this challenge, we take into consideration visual perceptual plausibility when adapting. Specifically, our method enforces attention consistency between the original and flipped images to achieve the model robustness to flipping. Simultaneously, we constrain attention separability between the pseudo class and the most confusing class to improve the model discriminability. Extensive experiments demonstrate that UARN shows better interpretability and achieves state-of-the-art performance on Oracle-241 dataset, substantially outperforming the previously structure-texture separation network by 8.5%.
Generalizable Facial Expression Recognition
Aug 20, 2024



SOTA facial expression recognition (FER) methods fail on test sets that have domain gaps with the train set. Recent domain adaptation FER methods need to acquire labeled or unlabeled samples of target domains to fine-tune the FER model, which might be infeasible in real-world deployment. In this paper, we aim to improve the zero-shot generalization ability of FER methods on different unseen test sets using only one train set. Inspired by how humans first detect faces and then select expression features, we propose a novel FER pipeline to extract expression-related features from any given face images. Our method is based on the generalizable face features extracted by large models like CLIP. However, it is non-trivial to adapt the general features of CLIP for specific tasks like FER. To preserve the generalization ability of CLIP and the high precision of the FER model, we design a novel approach that learns sigmoid masks based on the fixed CLIP face features to extract expression features. To further improve the generalization ability on unseen test sets, we separate the channels of the learned masked features according to the expression classes to directly generate logits and avoid using the FC layer to reduce overfitting. We also introduce a channel-diverse loss to make the learned masks separated. Extensive experiments on five different FER datasets verify that our method outperforms SOTA FER methods by large margins. Code is available in https://github.com/zyh-uaiaaaa/Generalizable-FER.
Efficient Face Super-Resolution via Wavelet-based Feature Enhancement Network
Jul 29, 2024Face super-resolution aims to reconstruct a high-resolution face image from a low-resolution face image. Previous methods typically employ an encoder-decoder structure to extract facial structural features, where the direct downsampling inevitably introduces distortions, especially to high-frequency features such as edges. To address this issue, we propose a wavelet-based feature enhancement network, which mitigates feature distortion by losslessly decomposing the input feature into high and low-frequency components using the wavelet transform and processing them separately. To improve the efficiency of facial feature extraction, a full domain Transformer is further proposed to enhance local, regional, and global facial features. Such designs allow our method to perform better without stacking many modules as previous methods did. Experiments show that our method effectively balances performance, model size, and speed. Code link: https://github.com/PRIS-CV/WFEN.
Skeleton2vec: A Self-supervised Learning Framework with Contextualized Target Representations for Skeleton Sequence
Jan 01, 2024Self-supervised pre-training paradigms have been extensively explored in the field of skeleton-based action recognition. In particular, methods based on masked prediction have pushed the performance of pre-training to a new height. However, these methods take low-level features, such as raw joint coordinates or temporal motion, as prediction targets for the masked regions, which is suboptimal. In this paper, we show that using high-level contextualized features as prediction targets can achieve superior performance. Specifically, we propose Skeleton2vec, a simple and efficient self-supervised 3D action representation learning framework, which utilizes a transformer-based teacher encoder taking unmasked training samples as input to create latent contextualized representations as prediction targets. Benefiting from the self-attention mechanism, the latent representations generated by the teacher encoder can incorporate the global context of the entire training samples, leading to a richer training task. Additionally, considering the high temporal correlations in skeleton sequences, we propose a motion-aware tube masking strategy which divides the skeleton sequence into several tubes and performs persistent masking within each tube based on motion priors, thus forcing the model to build long-range spatio-temporal connections and focus on action-semantic richer regions. Extensive experiments on NTU-60, NTU-120, and PKU-MMD datasets demonstrate that our proposed Skeleton2vec outperforms previous methods and achieves state-of-the-art results.
SwinFace: A Multi-task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation
Aug 22, 2023



In recent years, vision transformers have been introduced into face recognition and analysis and have achieved performance breakthroughs. However, most previous methods generally train a single model or an ensemble of models to perform the desired task, which ignores the synergy among different tasks and fails to achieve improved prediction accuracy, increased data efficiency, and reduced training time. This paper presents a multi-purpose algorithm for simultaneous face recognition, facial expression recognition, age estimation, and face attribute estimation (40 attributes including gender) based on a single Swin Transformer. Our design, the SwinFace, consists of a single shared backbone together with a subnet for each set of related tasks. To address the conflicts among multiple tasks and meet the different demands of tasks, a Multi-Level Channel Attention (MLCA) module is integrated into each task-specific analysis subnet, which can adaptively select the features from optimal levels and channels to perform the desired tasks. Extensive experiments show that the proposed model has a better understanding of the face and achieves excellent performance for all tasks. Especially, it achieves 90.97% accuracy on RAF-DB and 0.22 $\epsilon$-error on CLAP2015, which are state-of-the-art results on facial expression recognition and age estimation respectively. The code and models will be made publicly available at https://github.com/lxq1000/SwinFace.
SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition
May 24, 2022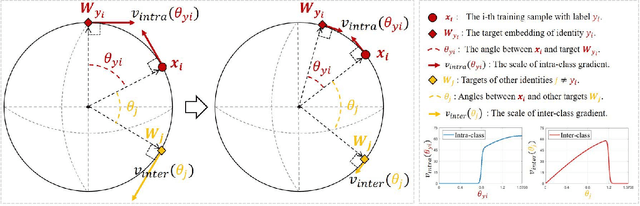
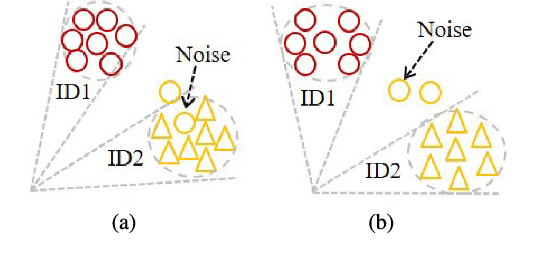
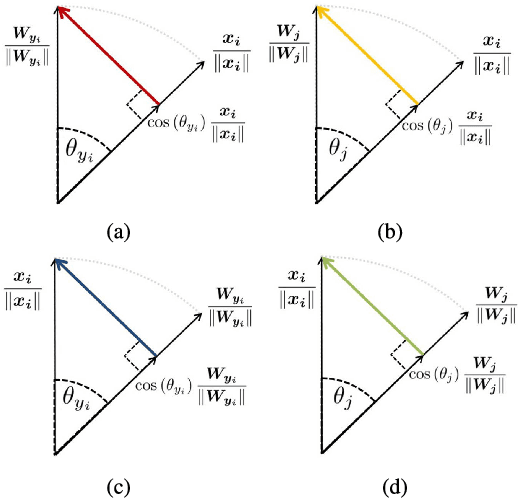
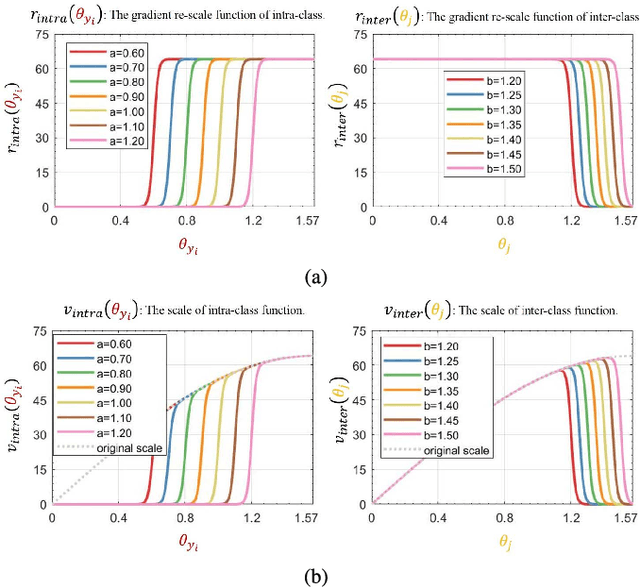
Deep face recognition has achieved great success due to large-scale training databases and rapidly developing loss functions. The existing algorithms devote to realizing an ideal idea: minimizing the intra-class distance and maximizing the inter-class distance. However, they may neglect that there are also low quality training images which should not be optimized in this strict way. Considering the imperfection of training databases, we propose that intra-class and inter-class objectives can be optimized in a moderate way to mitigate overfitting problem, and further propose a novel loss function, named sigmoid-constrained hypersphere loss (SFace). Specifically, SFace imposes intra-class and inter-class constraints on a hypersphere manifold, which are controlled by two sigmoid gradient re-scale functions respectively. The sigmoid curves precisely re-scale the intra-class and inter-class gradients so that training samples can be optimized to some degree. Therefore, SFace can make a better balance between decreasing the intra-class distances for clean examples and preventing overfitting to the label noise, and contributes more robust deep face recognition models. Extensive experiments of models trained on CASIA-WebFace, VGGFace2, and MS-Celeb-1M databases, and evaluated on several face recognition benchmarks, such as LFW, MegaFace and IJB-C databases, have demonstrated the superiority of SFace.
* 12 pages, 9 figures
Identity-Aware CycleGAN for Face Photo-Sketch Synthesis and Recognition
Mar 30, 2021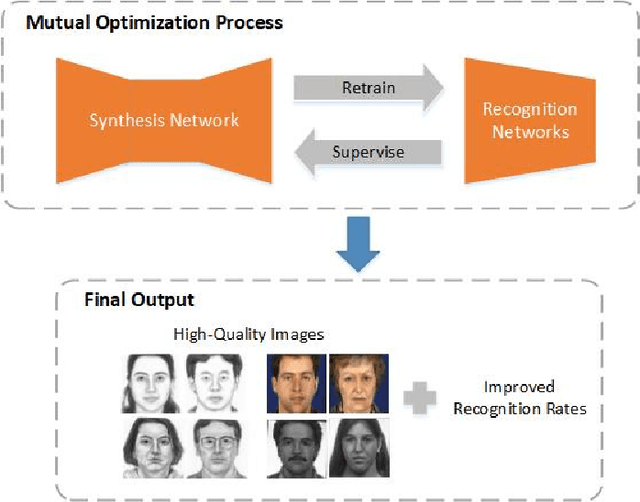
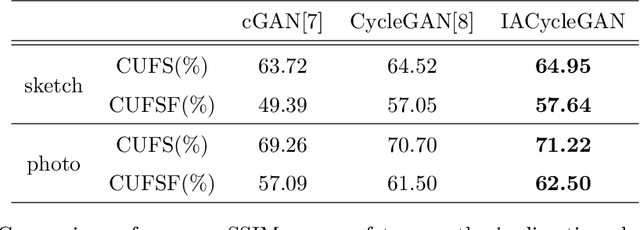
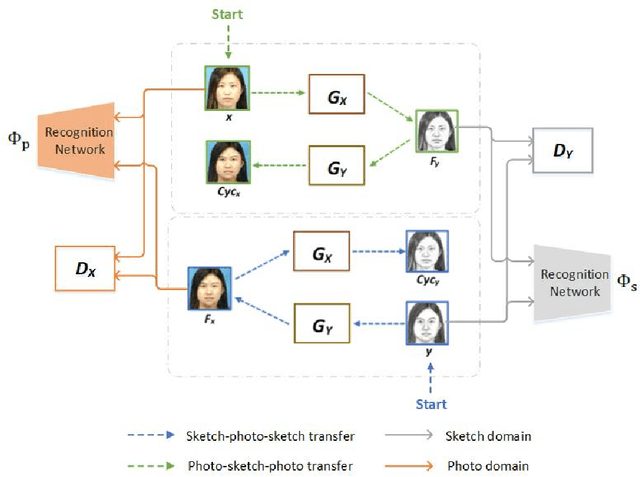
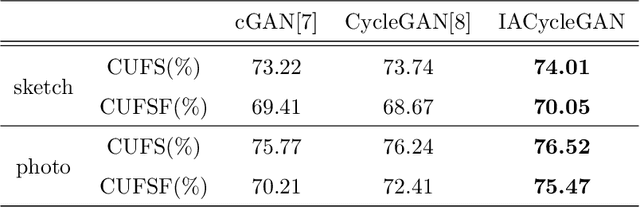
Face photo-sketch synthesis and recognition has many applications in digital entertainment and law enforcement. Recently, generative adversarial networks (GANs) based methods have significantly improved the quality of image synthesis, but they have not explicitly considered the purpose of recognition. In this paper, we first propose an Identity-Aware CycleGAN (IACycleGAN) model that applies a new perceptual loss to supervise the image generation network. It improves CycleGAN on photo-sketch synthesis by paying more attention to the synthesis of key facial regions, such as eyes and nose, which are important for identity recognition. Furthermore, we develop a mutual optimization procedure between the synthesis model and the recognition model, which iteratively synthesizes better images by IACycleGAN and enhances the recognition model by the triplet loss of the generated and real samples. Extensive experiments are performed on both photo-tosketch and sketch-to-photo tasks using the widely used CUFS and CUFSF databases. The results show that the proposed method performs better than several state-of-the-art methods in terms of both synthetic image quality and photo-sketch recognition accuracy.
* 36 pages, 11 figures
Mixed High-Order Attention Network for Person Re-Identification
Aug 16, 2019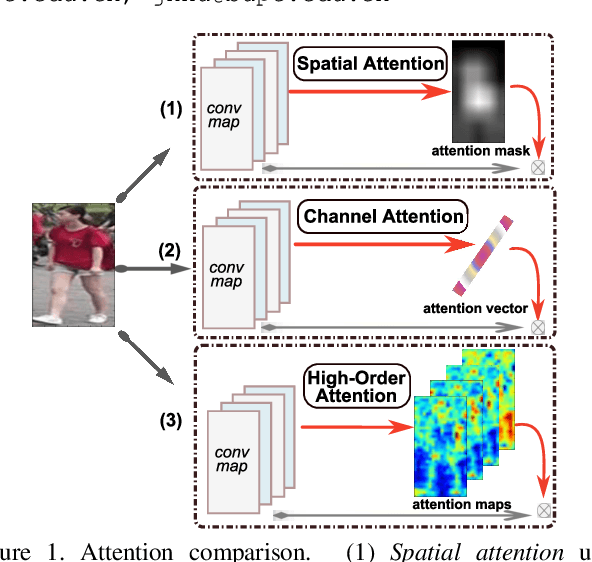
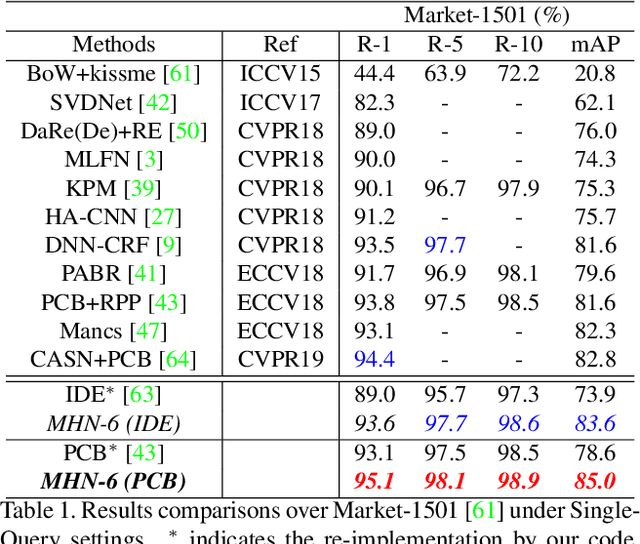
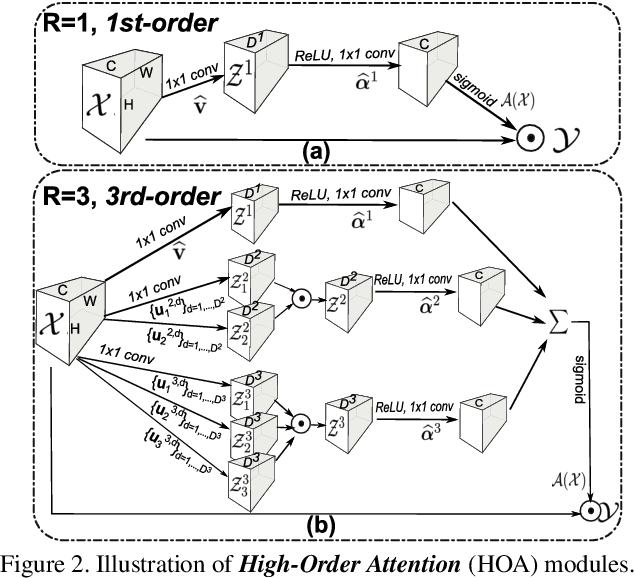
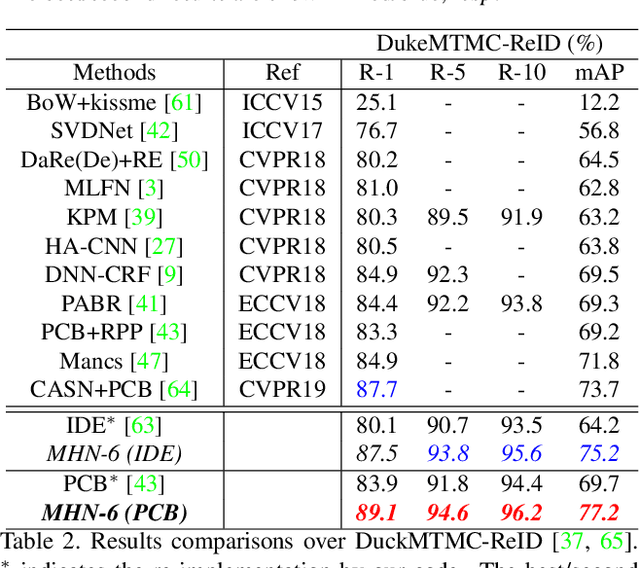
Attention has become more attractive in person reidentification (ReID) as it is capable of biasing the allocation of available resources towards the most informative parts of an input signal. However, state-of-the-art works concentrate only on coarse or first-order attention design, e.g. spatial and channels attention, while rarely exploring higher-order attention mechanism. We take a step towards addressing this problem. In this paper, we first propose the High-Order Attention (HOA) module to model and utilize the complex and high-order statistics information in attention mechanism, so as to capture the subtle differences among pedestrians and to produce the discriminative attention proposals. Then, rethinking person ReID as a zero-shot learning problem, we propose the Mixed High-Order Attention Network (MHN) to further enhance the discrimination and richness of attention knowledge in an explicit manner. Extensive experiments have been conducted to validate the superiority of our MHN for person ReID over a wide variety of state-of-the-art methods on three large-scale datasets, including Market-1501, DukeMTMC-ReID and CUHK03-NP. Code is available at http://www.bhchen.cn/.